
Transfer learning, fine-tuning and hyperparameter tuning#
This tutorial will walk through the process of transfer learning from a pre-trained network and a minimal approach to hyperparamater tuning. We’ll discuss what transfer learning and hyperparamater tuning are, when to consider them and demonstrate how to do so practically. This is an adaptation of this example and this one.
Transfer learning and fine-tuning#
A pre-trained model is the result of a network that has been trained already on a large dataset, usually characterized by a high degree of generalization. These models, which require a long training time using significant computing resources, have most often learned to understand very basic representations of features across domains, such as edges and shapes. Because of their generalizability, they can be helpful in expediting the training process for a custom task because they’ve already grasped the basic features, allowing for any new training to focus on the more particular, higher-order features. This is the intuition behind a process known as transfer learning. In practice, transfer learning can help to reduce the amount of time it takes to train a performant custom model. Sometimes pre-trained models are referred to as “backbone” networks.
There are two main strategies to transfer learning, which we will discuss and practice in this tutorial:
Feature Extraction: In this technique, we use some of the layers from the the pre-trained network (with all of its learnings) to extract features from the custom data, and then append a new classifier (and perhaps several other layers) on top to learn more higher-order features and classify per the unique task. This process doesn’t retrain any parts of the pre-trained network. It just uses some layers from it that have been “frozen” to derive some basic/generic features from the custom data. Any new layers are targeting the unique classes and characteristics of the custom data.
Fine-Tuning: In this technique, we actually “unfreeze” some of the pre-trained network (usually the last few layers) to adjust the learned parameters using custom data. This process allows for the higher-order features of the new, custom data to be directly blended and jointly learned with the information already gathered by the pre-trained network. In effect, this may help make the whole network more relevant to the custom data and task. This technique is best used for situations in which the new training dataset is relatively large and somewhat similar to the original dataset seen by the pre-trained model.
Hyperparameter tuning#
Hyperparameters are the variables in a machine learning network that determine the topology and regulate the training process. Unlike trainable parameters, these variables do not change during training. There are exceptions to this, such as in the case of learning rate decay. One way to think of hyperparameters is in the sense of gears that you tune to affect the performance of the model. They can be largely broken down into two groups:
Model hyperparameters: these relate to aspects such as how many hidden layers a network has, how wide the layers are, what the kernel size is.
Algorithm hyperparameters: these have more impact on the speed and learning rigor of the model. Examples include the learning rate and the number of epochs.
Hyperparameters can be tuned (sometimes referred to as optimized) with two methods:
Manual hyperparameter tuning, where the machine learning practitioner adjusts and experiments with values.
Automatic hyperparameter tuning, where the machine learning practitioner sets up a hyperparameter search space to try many different hyperparameter combinations across a grid or within boundaries, and then selects the combination that results in the best performance based on a tuning algorithm.
Typically, many hyperparameters can remain fixed when fine-tuning. Usually, this gets a machine learning model the vast majority of the way toward peak performance. However, some pitfalls can arise if learning rates are too large (resulting in failure to converge) or epochs too few. And when transferring models to finetune on larger and higher resolution images, sometimes hyperparameters need to be tuned to account for smaller object sizes. We recommend starting a machine learning experiment with manual hyperparameter tuning and gradually adjusting values to understand how you need to adjust the learning process for your problem. Automatic hyperparameter tuning can be overkill and expensive because it requires running potentially many iterative experiments, utilizing resources and time, to arrive at what may be negligible differences in configuration (and performance) compared with manual tuning. That said, if you are not resource constrained and have an idea of what informative experiments you would like to run up front, automatic hyperparameter tuning can be an efficient way to select a best performing model. In this tutorial, we’ll explore how to do a minimal, automatic hyperparameter tuning experiment using the Keras library.
Let’s get started#
So, now that we have these two tranfer learning strategies and hyperparameter tuning in mind, let’s get started with a practical example. We will revisit the use case in which we want to classify satellite images from the Eurosat RGB land cover image classification dataset available on TensorFlow Datasets. The goal will be to see how transfer learning and hyperparameter tuning may help us arrive at a performant model quickly.
# install required libraries
!pip install -q rasterio==1.3.8
!pip install -q geopandas==0.13.2
!pip install -q -U keras-tuner==1.3.5
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.3/21.3 MB 50.8 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 176.1/176.1 kB 2.0 MB/s eta 0:00:00
?25h
# import required libraries
import os, glob, functools, fnmatch, io, shutil, tarfile, json
from zipfile import ZipFile
from itertools import product
from pathlib import Path
import urllib.request
import pandas as pd
from sklearn.model_selection import train_test_split
from PIL import Image
import numpy as np
from google.colab import drive
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
import keras_tuner as kt
# set your folders
if 'google.colab' in str(get_ipython()):
# mount google drive
drive.mount('/content/gdrive')
processed_outputs_dir = '/content/gdrive/My Drive/tf-eo-devseed-2-processed-outputs/'
user_outputs_dir = '/content/gdrive/My Drive/tf-eo-devseed-2-user_outputs_dir'
if not os.path.exists(user_outputs_dir):
os.makedirs(user_outputs_dir)
print('Running on Colab')
else:
processed_outputs_dir = os.path.abspath("./data/tf-eo-devseed-2-processed-outputs")
user_outputs_dir = os.path.abspath('./tf-eo-devseed-2-user_outputs_dir')
if not os.path.exists(user_outputs_dir):
os.makedirs(user_outputs_dir)
os.makedirs(processed_outputs_dir)
print(f'Not running on Colab, data needs to be downloaded locally at {os.path.abspath(processed_outputs_dir)}')
Mounted at /content/gdrive
Running on Colab
# Move to your user directory in order to write data
%cd $user_outputs_dir
/content/gdrive/My Drive/tf-eo-devseed-2-user_outputs_dir
Data loading and pre-processing#
We will again use the Eurosat dataset, which contains labeled Sentinel-2 image patches classified into 10 land cover types. More details here: https://www.tensorflow.org/datasets/catalog/eurosat
The classes in this dataset are: ['Industrial', 'Pasture', 'River', 'Forest', 'AnnualCrop', 'PermanentCrop', 'Highway', 'HerbaceousVegetation', 'Residential', 'SeaLake']
The dataset will be partitioned into training, validation and testing splits with a 70:20:10 ratio, respectively.
# Construct tf.data.Dataset(s)
all_dataset, ds_info = tfds.load(name="eurosat/rgb", split=tfds.Split.TRAIN, with_info=True)
all_dataset = all_dataset.shuffle(1024)
validation_dataset = all_dataset.take(int(len(all_dataset)*0.3))
train_dataset = all_dataset.skip(int(len(all_dataset)*0.3))
test_dataset = validation_dataset.take(int(len(validation_dataset)*0.3))
validation_dataset = validation_dataset.skip(int(len(validation_dataset)*0.3))
print("Number of samples in each split (train, val, test): ", len(train_dataset), len(validation_dataset), len(test_dataset))
Downloading and preparing dataset 89.91 MiB (download: 89.91 MiB, generated: Unknown size, total: 89.91 MiB) to /root/tensorflow_datasets/eurosat/rgb/2.0.0...
Dataset eurosat downloaded and prepared to /root/tensorflow_datasets/eurosat/rgb/2.0.0. Subsequent calls will reuse this data.
Number of samples in each split (train, val, test): 18900 5670 2430
# Dataset specific parameters to be used in the model structure
INPUT_SHAPE = (64, 64, 3)
NUM_CLASSES = 10
BATCH_SIZE = 4
# Batch the datasets
train_dataset = train_dataset.batch(BATCH_SIZE)
validation_dataset = validation_dataset.batch(BATCH_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
print("Number of batches in each split (train, val, test): ", len(train_dataset), len(validation_dataset), len(test_dataset))
Number of batches in each split (train, val, test): 4725 1418 608
# Keras expects non-dictionary style format for its input
def convert_dataset(item):
"""Prepares a dict-style dataset in the format Keras expects, (features, labels)."""
image = item['image']
label = item['label']
return image, label
train_dataset = train_dataset.map(convert_dataset)
validation_dataset = validation_dataset.map(convert_dataset)
test_dataset = test_dataset.map(convert_dataset)
# Inspect the structure of the dataset
print(train_dataset.element_spec)
(TensorSpec(shape=(None, 64, 64, 3), dtype=tf.uint8, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))
Let’s visualize examples of the classes in the dataset
fig = tfds.show_examples(all_dataset, ds_info)

Prepare the dataset for performance#
We will use buffered prefetching to efficiently load samples from disk with I/O blockages. Read more on this technique in this data performance guide.
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Augment the data#
We will apply various transformations (that reflect realistic representations) to improve the robustness of our dataset. For example, these will include rotation and flipping. In effect, these will help the model see more variety and avoid overfitting. Another good guide for data augmentation can be found here.
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
Note: The augmentation layers defined above are only active during training, not during evaluation or prediction.
Let’s try these layers on a sample training image and plot the results.
for image, _ in train_dataset.take(1): #batch in train_dataset.take(1):
#image, label = batch["image"].numpy(), batch["label"].numpy()
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

Rescale pixel values#
We want our custom data, in this case the Eurosat images, to fit the scale expected by the pre-trained model. We will load the pretrained tf.keras.applications.MobileNetV2 model soon, which expects pixel values between [-1, 1] so let’s rescale the new data to fit that criteria and add this as a preprocessing step in our final model set up.
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
Note: Alternatively, pixel values can be arbitrarily rescaled from [0, 255] to [-1, 1] using tf.keras.layers.Rescaling.
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
Note: When using tf.keras.applications such as the above for MobileNetV2, always check the associated docs to know whether pixels should be scaled within [-1, 1] or [0, 1].
Load the pre-trained network (backbone)#
Now we will load the model that will serve as the base from which we transfer learn using our Eurosat dataset. MobileNetV2 is a model that was developed at Google. It learned from the ImageNet dataset, which is a large and generalized dataset of natural images which has been used extensively for development of pre-trained models in computer vision.
We will use the final-most pre-classification layer from the pre-trained network, known as the “bottleneck layer”, for feature extraction.
A key step when loading the pre-trained network is to specify the include_top=False argument, which prevents inclusion of the classification layer.
# Create the base model from the pre-trained model MobileNet V2
INPUT_SHAPE = INPUT_SHAPE
base_model = tf.keras.applications.MobileNetV2(input_shape=INPUT_SHAPE,
include_top=False,
weights='imagenet')
WARNING:tensorflow:`input_shape` is undefined or non-square, or `rows` is not in [96, 128, 160, 192, 224]. Weights for input shape (224, 224) will be loaded as the default.
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224_no_top.h5
9406464/9406464 [==============================] - 1s 0us/step
This feature extractor converts each 64x64x3 image into a 2x2x1280 block of features. Let’s see what it does to an example batch of images:
#batch = next(iter(train_dataset))
image_batch, label_batch = next(iter(train_dataset)) #batch["image"].numpy(), batch["label"].numpy()
#print(image_batch)
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(4, 2, 2, 1280)
Feature extraction#
The next step is to freeze the pre-trained convolutional network we loaded, and implement it as a feature extractor, which will serve as input to a newly added top-level classifier that we will train using our custom data.
Freeze the pre-trained network#
Freezing the convolutional base network before compiling and training the model is crucial. By setting by setting layer.trainable = False for a layer, we ensure its weights don’t get updated/re-trained during training. There are many layers in MobileNetV2, so we will just freeze the whole network by setting the entire network’s trainable flag to False.
base_model.trainable = False
Critical note for use of BatchNormalization layers#
It’s common to include tf.keras.layers.BatchNormalization layers in a model, but in the context of fine-tuning which we will explore later on, it’s important that these layers are treated with precaution.
Under the mode of layer.trainable = False, a BatchNormalization layer won’t apply any updates to its mean and variance statistics. This is called inference mode. Keeping BatchNormalization layers in inference mode during fine-tuning is important, otherwise, the non-trainable weights will be updated and this will corrupt what the pre-trained model has already learned.
More on this can be read in this transfer learning guide.
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_224"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 64, 64, 3)] 0 []
Conv1 (Conv2D) (None, 32, 32, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 32, 32, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 32, 32, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 32, 32, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 32, 32, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 32, 32, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 32, 32, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 32, 32, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 32, 32, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 32, 32, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 32, 32, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 33, 33, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 16, 16, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 16, 16, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 16, 16, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 16, 16, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 16, 16, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 16, 16, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 16, 16, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 16, 16, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 16, 16, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 16, 16, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 16, 16, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 16, 16, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 16, 16, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 16, 16, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 16, 16, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 16, 16, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 16, 16, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 17, 17, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 8, 8, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 8, 8, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 8, 8, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 8, 8, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 8, 8, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 8, 8, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 8, 8, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 8, 8, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 8, 8, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 8, 8, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 8, 8, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 8, 8, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 8, 8, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 8, 8, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 8, 8, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 8, 8, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 8, 8, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 8, 8, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 8, 8, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 8, 8, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 8, 8, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 8, 8, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 8, 8, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 8, 8, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 8, 8, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 8, 8, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 9, 9, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 4, 4, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 4, 4, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 4, 4, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 4, 4, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 4, 4, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 4, 4, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 4, 4, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 4, 4, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 4, 4, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 4, 4, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 4, 4, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 4, 4, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 4, 4, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 4, 4, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 4, 4, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 4, 4, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 4, 4, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 4, 4, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 4, 4, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 4, 4, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 4, 4, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 4, 4, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 4, 4, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 4, 4, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 4, 4, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 4, 4, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 4, 4, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 4, 4, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 4, 4, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 4, 4, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 4, 4, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 4, 4, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 4, 4, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 4, 4, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 4, 4, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 4, 4, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 4, 4, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 4, 4, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 4, 4, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 4, 4, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 4, 4, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 4, 4, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 4, 4, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 4, 4, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 4, 4, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 4, 4, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 4, 4, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 4, 4, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 4, 4, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 4, 4, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 4, 4, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 4, 4, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 4, 4, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 4, 4, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 4, 4, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 4, 4, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 4, 4, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 4, 4, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 4, 4, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 4, 4, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 4, 4, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 5, 5, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 2, 2, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 2, 2, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 2, 2, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 2, 2, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 2, 2, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 2, 2, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 2, 2, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 2, 2, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 2, 2, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 2, 2, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 2, 2, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 2, 2, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 2, 2, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 2, 2, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 2, 2, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 2, 2, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 2, 2, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 2, 2, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 2, 2, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 2, 2, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 2, 2, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 2, 2, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 2, 2, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 2, 2, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 2, 2, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 2, 2, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 2, 2, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 2, 2, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 2, 2, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 2, 2, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 2, 2, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 2, 2, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 2, 2, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 2, 2, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
Add a new classification layer (head)#
We will add a layer that averages over the feature maps and produce a flat vector for each sample in the batch.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(4, 1280)
From this, we add the classification layer, tf.keras.layers.Dense, to obtain a single prediction per image from the averaged feature maps. This will produce logits, raw prediction values for each class.
prediction_layer = tf.keras.layers.Dense(NUM_CLASSES)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(4, 10)
Now we will put everything together and build a model that includes the data augmentation, rescaling, feature extractor layers and classification head using the Keras Functional API. Of note, we are setting training=False because this model contains a BatchNormalization layer.
inputs = tf.keras.Input(shape=INPUT_SHAPE)
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
Compile the model#
Compile the model. There are 10 classes in the Eurosat dataset, so we will use an appropriate loss function for multi-class classification, tf.keras.losses.SparseCategoricalCrossentropy, with from_logits=True as this model generates linear output.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 64, 64, 3)] 0
sequential (Sequential) (None, 64, 64, 3) 0
tf.math.truediv (TFOpLambda (None, 64, 64, 3) 0
)
tf.math.subtract (TFOpLambd (None, 64, 64, 3) 0
a)
mobilenetv2_1.00_224 (Funct (None, 2, 2, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 10) 12810
=================================================================
Total params: 2,270,794
Trainable params: 12,810
Non-trainable params: 2,257,984
_________________________________________________________________
The over 2 million parameters in the frozen MobileNetV2 backbone, and much fewer which are trainable parameters in our added Dense layer. These parameters are all divided between two key tf.Variable objects: weights and biases.
len(model.trainable_variables)
2
Train the model#
We will train for some epochs, and then check the accuracy on the validation set.
initial_epochs = 4 # 10
loss0, accuracy0 = model.evaluate(validation_dataset)
1418/1418 [==============================] - 14s 9ms/step - loss: 2.7675 - accuracy: 0.1557
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 2.77
initial accuracy: 0.16
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10
4725/4725 [==============================] - 58s 11ms/step - loss: 1.1679 - accuracy: 0.6061 - val_loss: 0.6880 - val_accuracy: 0.7744
Epoch 2/10
4725/4725 [==============================] - 52s 11ms/step - loss: 0.7045 - accuracy: 0.7712 - val_loss: 0.5544 - val_accuracy: 0.8210
Epoch 3/10
4725/4725 [==============================] - 50s 11ms/step - loss: 0.6095 - accuracy: 0.8019 - val_loss: 0.5040 - val_accuracy: 0.8400
Epoch 4/10
4725/4725 [==============================] - 52s 11ms/step - loss: 0.5752 - accuracy: 0.8144 - val_loss: 0.4693 - val_accuracy: 0.8476
Epoch 5/10
4725/4725 [==============================] - 52s 11ms/step - loss: 0.5468 - accuracy: 0.8233 - val_loss: 0.4595 - val_accuracy: 0.8496
Epoch 6/10
4725/4725 [==============================] - 50s 11ms/step - loss: 0.5243 - accuracy: 0.8267 - val_loss: 0.4379 - val_accuracy: 0.8586
Epoch 7/10
4725/4725 [==============================] - 52s 11ms/step - loss: 0.5160 - accuracy: 0.8317 - val_loss: 0.4288 - val_accuracy: 0.8626
Epoch 8/10
4725/4725 [==============================] - 52s 11ms/step - loss: 0.5046 - accuracy: 0.8327 - val_loss: 0.4287 - val_accuracy: 0.8596
Epoch 9/10
4725/4725 [==============================] - 49s 10ms/step - loss: 0.4945 - accuracy: 0.8376 - val_loss: 0.4275 - val_accuracy: 0.8649
Epoch 10/10
4725/4725 [==============================] - 47s 10ms/step - loss: 0.4897 - accuracy: 0.8407 - val_loss: 0.4082 - val_accuracy: 0.8693
Learning curves#
The learning curves for the training and validation accuracy/loss help us visualize what happens when we use the MobileNetV2 pre-trained model as a fixed feature extractor.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
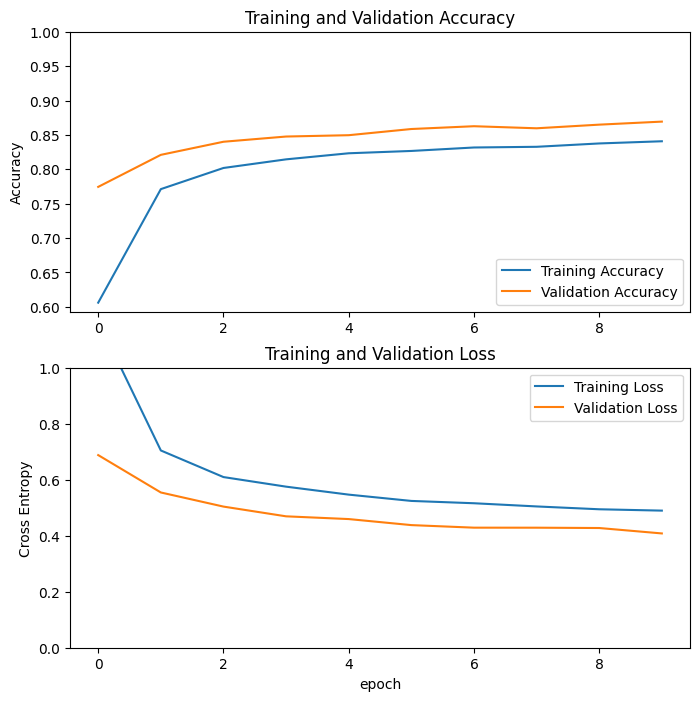
Note that the validation metrics are better than the training metrics. This is mainly the case because certain layers such as tf.keras.layers.BatchNormalization and tf.keras.layers.Dropout impact accuracy during training. However, they are inactive when calculating validation loss. A second yet much more minor reason for why the training metrics are lower is because
validation metrics are evaluated at the end of each epoch while training metrics are calculated as an average in each epoch. Therefore, validation metrics represent the concrete end of an epoch not the interim progress.
Now let’s measure the performance of the model on new data from the test set. By the way, Keras’ model.evaluate method will report the loss and metric defined in the modile.compile step.
loss_test, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
608/608 [==============================] - 4s 7ms/step - loss: 0.4550 - accuracy: 0.8469
Test accuracy : 0.8469135761260986
Fine tuning#
When we were using the pre-trained network for feature extraction alone, we were only training a minimal set of added layers on top of the MobileNetV2 backbone. None of the backbone was trained.
It’s possible we can improve the accuracy of our model further by fine-tuning the weights from the final-most pre-classification layers of the backbone by training them with our added classification layers.
This fused training should refine the pre-trained feature maps from a generic to more specific representation of the custom data.
Note: It’s best to fine-tune after having trained the top-level classifier with the backbone set to non-trainable. Reason being, if we were to try to jointly train a randomly initialized classifier on top of a pre-trained model, the computed gradients will be too large, causing major gradient updates and information degradation to the pre-trained model. As well, a best practice is to only fine-tune a minimal set of top-most layers from the backbone instead of the entire network since the bottom-most layers are really just learning simple, generic features. This harkens back to the goal of fine-tuning, which is to refine the higher-order feature maps to the custom data.
Un-freeze some top layers of the model#
We will unfreeze our backbone, the base_model, and instead, just set the bottom (generic) layers to be un-trainable.
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
Compile the model#
We must then recompile the model for these changes to take effect. It’s key to use a low learning rate because otherwise, we might overfit with such a large model.
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 64, 64, 3)] 0
sequential (Sequential) (None, 64, 64, 3) 0
tf.math.truediv (TFOpLambda (None, 64, 64, 3) 0
)
tf.math.subtract (TFOpLambd (None, 64, 64, 3) 0
a)
mobilenetv2_1.00_224 (Funct (None, 2, 2, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 10) 12810
=================================================================
Total params: 2,270,794
Trainable params: 1,874,250
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
Continue training the model#
Lastly, we will fine-tune by resuming training.
fine_tune_epochs = 4 # 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Epoch 10/20
4725/4725 [==============================] - 90s 17ms/step - loss: 0.5006 - accuracy: 0.8370 - val_loss: 0.3183 - val_accuracy: 0.8968
Epoch 11/20
4725/4725 [==============================] - 76s 16ms/step - loss: 0.3784 - accuracy: 0.8821 - val_loss: 0.2646 - val_accuracy: 0.9152
Epoch 12/20
4725/4725 [==============================] - 77s 16ms/step - loss: 0.3205 - accuracy: 0.8991 - val_loss: 0.2720 - val_accuracy: 0.9152
Epoch 13/20
4725/4725 [==============================] - 74s 16ms/step - loss: 0.2962 - accuracy: 0.9084 - val_loss: 0.2276 - val_accuracy: 0.9310
Epoch 14/20
4725/4725 [==============================] - 77s 16ms/step - loss: 0.2827 - accuracy: 0.9130 - val_loss: 0.2748 - val_accuracy: 0.9183
Epoch 15/20
4725/4725 [==============================] - 73s 16ms/step - loss: 0.2694 - accuracy: 0.9167 - val_loss: 0.2679 - val_accuracy: 0.9238
Epoch 16/20
4725/4725 [==============================] - 74s 16ms/step - loss: 0.2744 - accuracy: 0.9182 - val_loss: 0.2556 - val_accuracy: 0.9270
Epoch 17/20
4725/4725 [==============================] - 74s 16ms/step - loss: 0.2649 - accuracy: 0.9218 - val_loss: 0.2000 - val_accuracy: 0.9395
Epoch 18/20
4725/4725 [==============================] - 76s 16ms/step - loss: 0.2728 - accuracy: 0.9235 - val_loss: 0.2472 - val_accuracy: 0.9323
Epoch 19/20
4725/4725 [==============================] - 73s 15ms/step - loss: 0.2654 - accuracy: 0.9239 - val_loss: 0.2396 - val_accuracy: 0.9280
Epoch 20/20
4725/4725 [==============================] - 73s 15ms/step - loss: 0.2606 - accuracy: 0.9242 - val_loss: 0.2241 - val_accuracy: 0.9362
Again, the learning curves for the training and validation accuracy/loss help us visualize what happens when we fine-tune using the MobileNetV2 pre-trained model. Overfitting may be happening if we see a much higher validation loss compared to its training counterpart. This is not abnormal as the new, custom data is much smaller than that which was initially used to train the MobileNetV2 backbone.
#loss, history_fine.history['loss']
#acc, history_fine.history['accuracy']
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
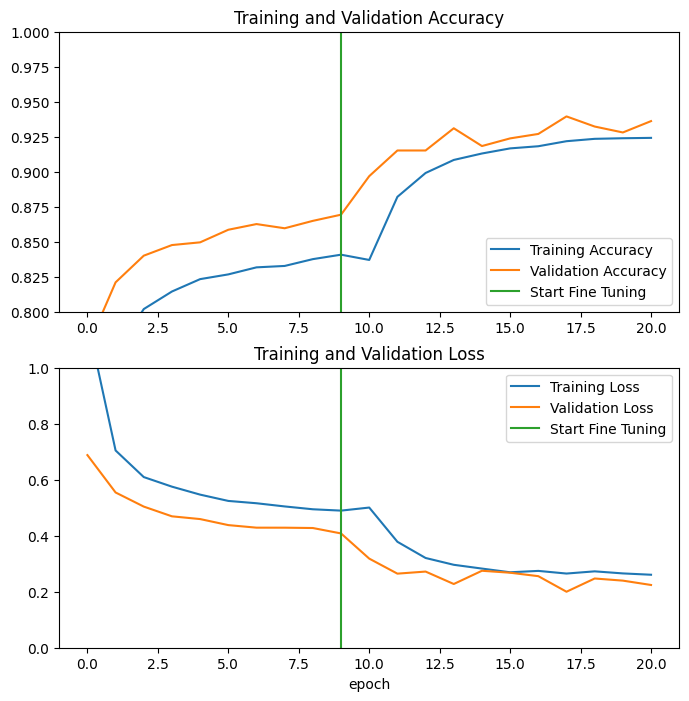
Evaluation and prediction#
Now let’s measure the performance of the fine-tuned model on new data from the test set.
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
608/608 [==============================] - 5s 8ms/step - loss: 0.2487 - accuracy: 0.9259
Test accuracy : 0.9259259104728699
With this model, we can predict the probabilities of an image belonging to one of the 10 classes.
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
print(len(predictions.numpy()), len(label_batch))
Hyperparameter Tuning#
To use the Keras tuner library, we have to format our model in a model builder function. All this takes is enveloping the constituent layers we defined above in a function, ensuring that any arguments such as INPUT_SHAPE have been defined outside of the function.
We will tune the learning rate in the following experiment, with the goal of selecting the optimal value from a range between [0.0001, 0.01].
The function will return the compiled model using the selection of hyperparameters defined.
base_model = tf.keras.applications.MobileNetV2(input_shape=INPUT_SHAPE,
include_top=False,
weights='imagenet')
base_model.trainable = False
def model_builder(hp):
inputs = tf.keras.Input(shape=INPUT_SHAPE)
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
# Tune the learning rate for the optimizer
# Choose an optimal value from between 0.0001 to 0.01
# hp_learning_rate = hp.Float('learning_rate', min_value=1e-4, max_value=1e-2)
# Choose an optimal value from 0.01, 0.001, or 0.0001
hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=hp_learning_rate),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
Now we will instantiate the tuner algorithm, in this case one called Hyperband. Herein, we have to specify the objective to optimize for and the allowable number of epochs to train an experiment for (usually this is to a large value and safeguarded by an early stopping callback which we’ll define next). Note that the project_name argument defines a folder that will hold all of the checkpoints and logs from the trials in this experiment. By default, if the search is rerun with this same directory, the search will resume from the state captured in those checkpoints. This can be changed by including overwrite=True.
tuner = kt.Hyperband(model_builder,
objective='accuracy',
max_epochs=4,
project_name='exp_hp_0')
We will also include a callback function that halts training when convergence has been achieved, despite whether the number of epochs defined is still in excess. This is a useful strategy to improve the resource efficiency of our models and prevent overfitting.
stop_early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=2)
Commence the tuning process. Note that the arguments for tuner.search are the same as those for Keras’ model.fit method.
From this, we will find out which value is optimal for the learning rate.
tuner.search(train_dataset, epochs=20, callbacks=[stop_early])
# Get the optimal hyperparameters
best_hps=tuner.get_best_hyperparameters(num_trials=1)[0]
print(f"""
The hyperparameter search is complete. The optimal learning rate for the optimizer
is {best_hps.get('learning_rate')}.
""")
Now that we know the best hyperparameters from our tuning experiments, let’s train the model and determine the best performing epoch.
# Build the model with the optimal hyperparameters and train it on the data for 4 epochs
model = tuner.hypermodel.build(best_hps)
history = model.fit(train_dataset, epochs=8)
acc_per_epoch = history.history['accuracy']
best_epoch = acc_per_epoch.index(max(acc_per_epoch)) + 1
print('Best epoch: %d' % (best_epoch,))
Finally, let’s evaluate our tuned model on the test dataset.
eval_result = model.evaluate(test_dataset)
print("[test loss, test accuracy]:", eval_result)
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#@title MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.