
Comparing deep learning architectures for different computer vision tasks on satellite imagery#
A guide for selecting deep-learning architectures for land use / land cover mapping and change detection in satellite imagery.
LeNet (LeCun et al. 1998)[i]#
In 1998, LeCun et al. introduced the first Convolutional Neural Network (CNN) known as LeNet. This marked the introduction of the convolutional layer which is a three-part process involving convolution, pooling, and nonlinear activation functions. The LeNet model utilized the tanh activation function, though later networks would replace this with the Rectified Linear Unit (ReLU) to address the vanishing gradient problem. It also uses average pooling, though later research found max pooling performs better. Despite its innovative design, LeNet was not popular during its inception, mainly due to the lack of software and hardware compatibility for training large networks. At that time, Support Vector Machines (SVM) were still competitive with LeNet in terms of detection capabilities.

Fig. 29 LeNET Image from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
AlexNet (Krizhevsky et al. 2012)[ii]#
2012 marked the breakout moment for CNNs with the introduction of AlexNet. It significantly outperformed its competition, achieving an error rate that was 10.8 percentage points lower than the next runner-up in the ImageNet Large Scale Visual Recognition Challenge. One of the primary takeaways from AlexNet’s performance was that deeper networks tended to yield higher performance. The computational demands of AlexNet were made feasible primarily because of GPUs. The network improved upon LeNeT by utilizing the non-saturating ReLU function, which showed better training performance than the tanh or sigmoid activations, max pooling instead of average pooling, and a regularization layer called dropout, which reduces overfitting by Randomly setting nodes to 0 so that they do not contribute to training. Finally, the largest difference between AlexNet and LeNet is that AlexNet was trained on a massive amount of data, millions of images, which was enabled by a combination of GPU hardware, and the aforementioned changes to the architecture: ReLU for faster training and dropout for improved regularization. AlexNet’s impact is undeniable, as evidenced by its citation in over 120,000 papers on Google Scholar.

Fig. 30 AlexNet Arch Image from “Understanding AlexNet” by learnopencv.com#
Below are the features learned by the initial layer of AlexNet. Note how some convolutional kernels learn textural information, like lines, and others learn color.

Fig. 31 AlexNet FilterImage from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
Network in Network (NiN) (Lin et al. 2013)[iii]#
This architecture addresses a fundamental problem with AlexNet, LeNet, and other CNNs with fully connected layers: the last fully connected layers have hundreds of millions of parameters. NiN solves this by replacing the last fully connected layers with 1x1 convolutions and global average pooling. It also replaces linear convolutional layers with mini multi-layer-perceptrons appended to convolutional layers.
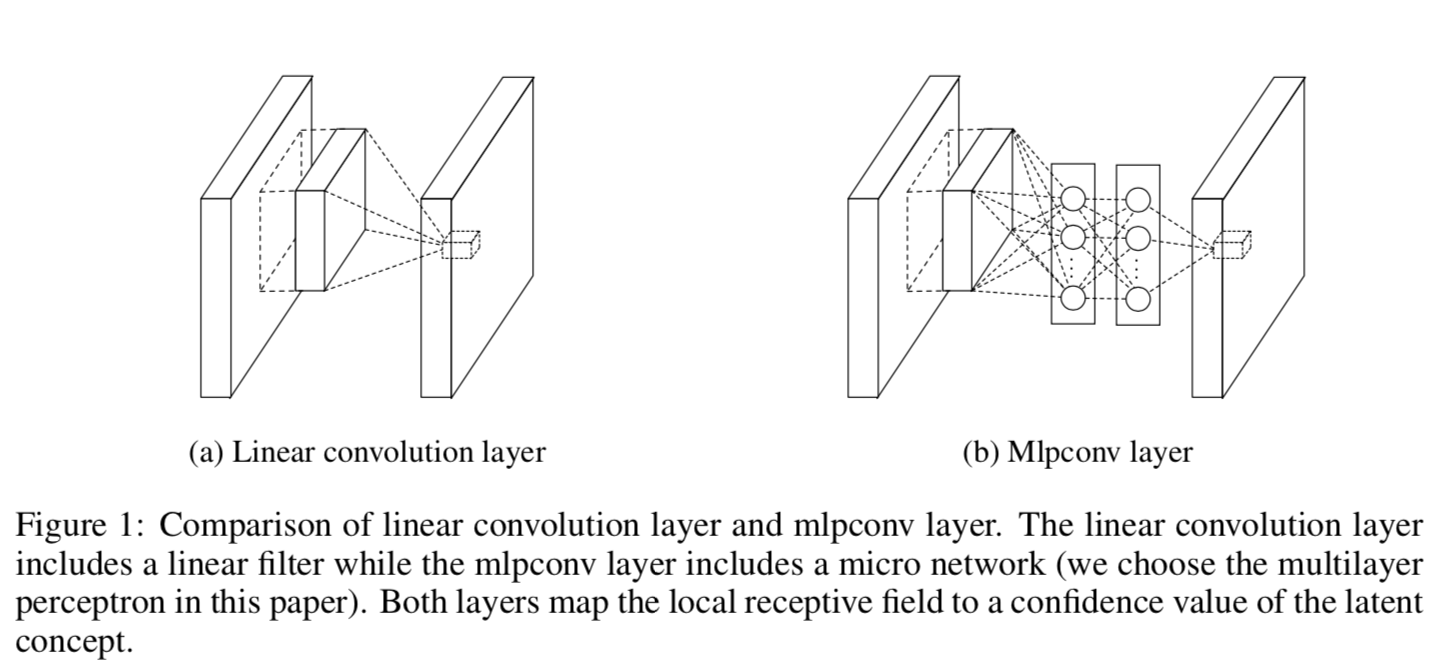
Fig. 32 NiN Block from “Network in Network” by Lin et al. 2013#
{kind=link}
Effectively this creates many smaller fully connected layers at each pixel location that in total have many fewer parameters than the linearly stacked fully connected layers of AlexNet. Notably, NiN can increase the training time for the network to converge to a minimum loss.
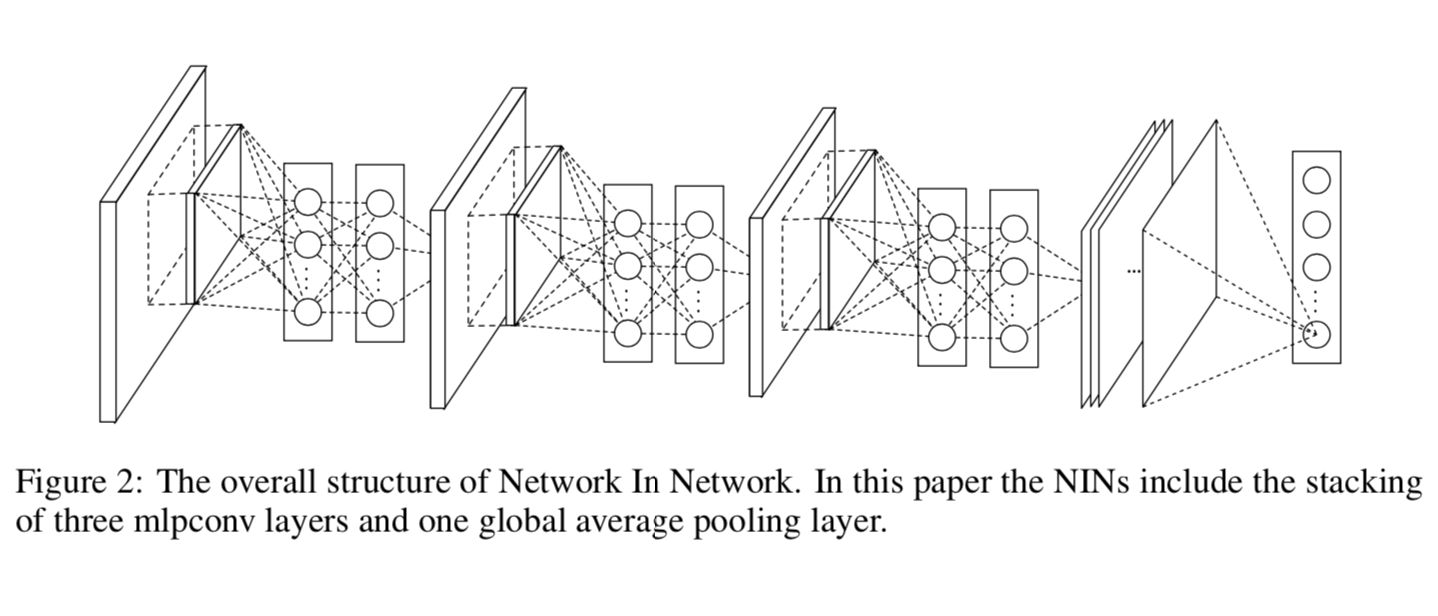
Fig. 33 NiN Architecture from “Network in Network” by by Lin et al. 2013#
{kind=link}
Networks Using Blocks, VGG (Simonyan and Zisserman 2014)[iv]#
While VGG still maintains fully connected layers that NiN addresses, it introduces a solution to a different key limitation of AlexNet: CNN based networks with stacked blocks of Conv > Relu > Max Pooling can only be as deep given the second logarithm of the number of dimensions in the input. The authors introduced the VGG Block, which replaces single convolutional steps with multiple convolutional steps. For example, two stacked 3x3 convolutions followed by max pooling produces a similar computation burden to a single 5x5 convolutional layer. They find that deeper and narrower networks can be trained to higher performance, while accepting higher parameters counts.

Fig. 34 VGG Architecture Image from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
Inception/GoogleNet (Szegedy et al. 2014)[v]#
Inception, also known as GoogleNet, combines the best features of VGG and NiN to reduce the parameter size of the model and learn features more efficiently. It does so by using a 3 part structure for a CNN composed of the following:
a simple stem network for learning low-level features
a body for learning higher level features with more intricate network structure
a head network for a particular kind, or kinds, of detection (classification, segmentation, object detection).
This 3-part structure reflects many of the modern networks we use today and allowed GoogleNet to learn more informative features with fewer parameters. The main star of GoogleNet, the inception block, occurs in the body, and uses multiple branches to allow the network to implicitly select the correct convolution filter shapes for a particular detection problem. This means parameters are allocated to the most important convolution filters that map to different extents of an image. A noteworthy statement from the authors is, “For most of the experiments, the models were designed to keep a computational budget of 1.5 billion multiply-adds at inference time, so that they do not end up to be a purely academic curiosity, but could be put to real world use, even on large datasets, at a reasonable cost.” (Szegedy et al. 2014).

Fig. 35 Inception Block Image from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
The Inception model also includes some other notable features. The stem module resembles AlexNet and LeNet, but with added 1x1 convolutional filters after the max pooling layers also addressed concerns that many max pooling layers result in the loss of high-resolution spatial information.
This inception module addresses a prevalent issue with deep neural networks: models with a large number of parameters are more susceptible to overfitting, especially when the dataset size remains fixed. Another challenge tackled by Inception was the computational burden of deep vision networks. When two convolutional filters are chained together, a uniform increase in their filter count results in a quadratic increase in computation. In contrast, inception blocks are more computationally efficient.

Inception increased both the depth and width of the network but did so with fewer parameters. Interestingly, it possesses fewer parameters than AlexNet, reflecting a broader trend towards creating smaller yet high-performing deep neural networks. The advantages of having fewer parameters include faster training times, reduced memory consumption, and more efficient learned features.

Fig. 36 GoogleNet Image from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
Batch Normalization (Ioffe and Szegedy 2015)[vi]#
Training neural networks can take a long time, even when using GPUs (hours, days, even weeks!). Larger networks, in the 100s of layers, used to be intractable to train and fine-tune on consumer-grade hardware (1 or 2 GPUs). Recall that while VGG improved network accuracy with deeper and narrower networks, it increases parameter counts. VGG-11 only had 8 convolutional layers and 3 connected layers, but today, it’s common for networks to have over 100 convolutional layers. As deeper networks are trained, weights and biases in one layer may be magnified or minified compared to the values in another layer by orders of magnitude, making it more difficult for intermediate layers in the network to update parameters with fixed learning rates and step sizes. This problem is sometimes referred to as “internal covariate shift” indicating that the relationship between parameters in intermediate layers can drift and introduce inaccuracies.
Batch normalization addresses this by subtracting the mean and dividing by the standard deviation for each minibatch. For convolutional layers, this entails taking the channel-wise means and standard deviations across all pixel locations and using them to normalize each channel. Batch norm can be applied to all convolutional layers, or some convolutional layers. Normalization can also be applied ber sample rather than per-batch, which is called layer normalization.
Batch normalization was shown to improve deep model training via regularization and improving numerical stability during training.
Resnet (He et al. 2015)[vii]#
Following the trend of increasing network complexity, the paper “Deep residual learning for image recognition”, investigated how to increase the expressivity of layers in very deep networks, rather than adding parameters that don’t improve the model (it’s been shown mathematically that larger models aren’t guaranteed to lead to better results than smaller models, all else being equal). He et al. sought to improve upon architecture designs by allowing the input to a block to pass through to be added to the activations of the output of the block. Effectively, this means that a block learns the residuals (the differences) between the input and desired activations.

Fig. 37 GoogleNet Image from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
Therefore, inputs can pass through the network much more quickly, allowing for networks with hundreds of layers (like Resenet-152). With these large networks, inputs can pass through layers that are not needed, since they effectively can learn weights and biases that contribute 0 to the activation, allowing for faster learning.
Residual connections are now a primary component of non-CNN architectures in domains beyond computer vision. The Transformer architecture, which we will learn more about later, also uses residual connections.
Concluding Remarks#
Importance of using well-established architectures.
Importance of using well-established implementations, or understanding your own implementation.
Value of leveraging popular libraries and ML frameworks for practical applications, see next lesson.