
Comparing RNNs and Transformers for Imagery#
A guide for selecting deep-learning architectures for land use / land cover mapping and change detection in satellite imagery.
Objectives#
Understand RNNs and the differences in structure from CNNs
Cover a short history of RNNs for time series forecasting and prediction
Cover challenges with trianing RNNs and deploying
Cover CNN and Transformer models for time series prediction and how they address RNN challenges.
RNN Architectures for Forecasting and Change Detection in 1-D and Imagery Sequences#
Until now, our discussions have centered on fixed-length datasets composed of 3-band images. While CNNs excel with these types of datasets, understanding the relationship between images in a sequence requires a more intricate structure that takes into account interactions along the time dimension.
Recurrent Neural Networks (RNNs) are tailored for modeling variable-length sequences, whether they’re text, 1-dimensional time series, or sequences of images like videos. Unlike CNNs, RNNs maintain a “hidden state” at each time step, representing the outcome from all hidden layers within the RNN. This state, along with the sequence input, is fed into the subsequent RNN time step. To illustrate, consider the task of predicting the next letter in the word “dogs” using an RNN:
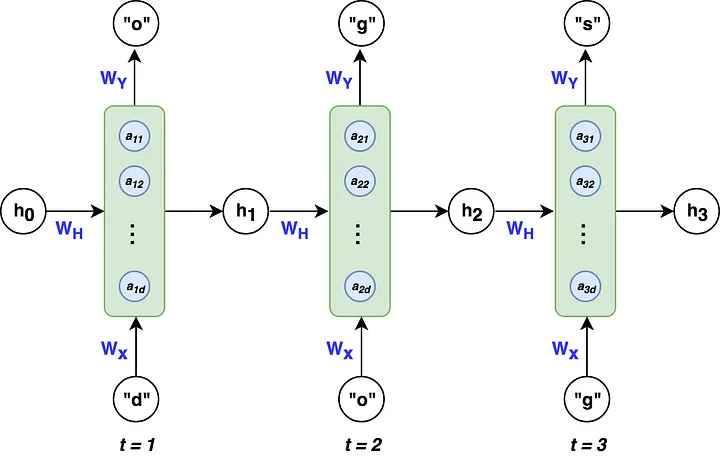
Fig. 38 Ben Khuong, The Basics of Recurrent Neural Networks (RNNs)#
Here, the hidden states, represented by “h”, are derived from individual sequence samples. The nodes of the hidden layers, “a”, embody the learned weights and biases for each state. Because each state depends on its predecessor, states must be computed sequentially, not in parallel.
The computational demands of RNNs are substantial due to their sequential nature. Furthermore, the direct links between adjacent time steps give the network a short-term memory biased towards length t=1. While inputs farther than t=1 can influence a hidden state, conventional RNNs grapple with the vanishing (or exploding) gradient issue. As a remedy, Long Short-Term Memory networks (LSTMs) were crafted to tackle more complex sequence modeling challenges and combat the vanishing gradient problem. We’ll delve into LSTMs shortly.
Long Short-Term Memory Networks (Hochreiter and Schmidhuber, 1997)#
LSTMs introduced the concept of “memory cell state” to RNN computations, termed the “memory block”. This memory block empowers LSTMs to determine which learned contexts to retain or discard and how much of it to relay to the next step. These decisions are steered by gates, which mitigate the vanishing gradient issue by ensuring that only informative gradients are computed. Think of the memory block as the RAM of your computer, always keeping relevant short term or long term information updated and ready for the LSTM. In contrast, a regular RNN has no memory cell, so they have difficulty accessing information in the distant past.

Fig. 39 Long Short-Term Memory (LSTM) from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
The figure above depicts:
An input gate, determining how much of the input should influence the current memory cell. A forget gate, deciding the extent to which the input hidden state affects subsequent states. An output gate, which influences the final output based on the current memory cell. LSTMs, along with architectures like bi-directional RNNs, dominated sequence prediction between 2011 and 2017. Transformers would soon dethrone them. However, the intrinsic limitation of RNNs—that they don’t support parallel training—renders them less favorable for training sizable models on extensive image datasets. We’ll soon explore how Transformers and other architectures overcome this shortcoming.
The Transformer (Vaswani et al. 2017)#
For decades, CNNs have reigned in computer vision, while LSTMs have led natural language processing. Despite numerous advancements in activation functions (like ReLU), training methodologies (e.g., Batch Norm), and architectural refinements (such as residual connections), these classic architectures persisted. However, the Transformer’s introduction marked a significant shift in foundational computing architectures, ushering in the era of self-attention.
Initially, Vaswani and colleagues (2017) introduced the Transformer for transduction tasks—converting input sequences into output sequences. By 2020, Dosovitskiy et al. demonstrated that Transformers could achieve near state-of-the-art results in image classification, surpassing complex CNN-based models in terms of computational efficiency.
Encoder-Decoder Models and the Self-Attention Mechanism#
When processing image time series, our primary goals are either:
do pixel-wise segmentation of the time series at each time step, producing an equivalent length time series of maps
predict a change map for the time series, which can will be of a different variable length depending on how we measure change.
In either case, we are converting an image sequence to another image sequence. Even in the case of single date imagery, we are converting a sequence of bands to a sequence of length one. Sequence to sequence models can be addressed by Encoder-Decoder architectures, where an encoder computes image features and a decoder uses those image features to make a prediction. Encoder-decoder models are powerful because each section can be trained and used for inference independently. Transformer models make use of an encoder-decoder structure rather than the stem, body, head of a CNN-based architecture. In a transformer, the encoder returns a fixed length feature sequence called “embeddings”. These embeddings are of the same length as the input sequence (the time dimension of an image time series in this case), and a decoder uses a mechanism called self-attention to selectively incorporate learned features at informative points of the feature sequence, ignoring uniformative points of the feature sequence.
Below is a figure describing the connections between sequence elements to each other within 3 different networks, an RNN, a CNN, and self-attention.

Fig. 40 A Comparison of Self-Attention to CNN and RNN based methods for Sequence Processing from “Dive into Deep Learning” by d2l.ai, used under CC BY-SA 4.0#
In the RNN, as we have described in the previous section, inputs X1, X2, and so on must be processed independently. In contrast, for the CNN and self-attention, inputs may be processed in parallel. The primary difference between CNNs and self-attention is that self-attention has a shorter path length when computing between different points in a sequence. But, self-attention requires quadratic computational complexity (a problem addressed by GoogleNet in 2014). This increase in computational complexity when training self-attention models is important to keep in mind. Even though the representational power of these models may be higher than CNNs given enough training data and compute, you may not have the resources needed to take advantage of self-attention when training models from scratch.
Vision Transformer (Dosovitskiy 2020)#
Notably, the Vison Transformer, or ViT, has been shown to greatly outperform Resnets given enough training data (Dosovitskiy 2020).

Fig. 41 An image is worth 16x16 words: Transformers in Image Recognition at Scale#
However, because transformers have less assumptions of local structure in images than CNNs, they can still underperform CNNs when pretrained on datasets on the scale of ImageNet (under 2 million images). Since ViT’s introduction, developments in transformers for vision are moving quickly to address computational challenges and input requirements of the architecture. Notably, the SWiN Transformer addresses the quadratic complexity problem, producing state of the art results on Imagenet classfication by introducing CNN-like priors (Liu et al. 2021). And a very recent development, NaViT (Dehghani 2023) removes a common input constraint of CNNs and older ViT implementations where the aspect ratio and resolution of images must be the same as what was used during training. There is still much investigation to be done on the transferrability of ViT-based models to the remote sensing domain given most are pretrained on natural images, and to develop foundational models in the remote sensing domain on satellite imagery.
ConvMixer is an alternative with lower computational burden, that is CNN and MLP based, available from the Keras team: https://huggingface.co/keras-io/convmixer
Foundational Transformer Models#
Because of their higher computational complexity and high performance, a recent trend in deep learning has been to focus efforts on training foundational models. Foundational models are large models in the sense that they have a large number of parameters, have been exposed to data from many different domains, and can be fine-tuned for a variety of tasks across text, vision, speech, or even between these disparate domains.
While foundational image models have been developed, the image domains they have been trained on are typically limited to natural images, i.e. street view scenes, photographs, and other imagery that is not in the top-down sensor domain we typically deal with. Yet there have been some very recent releases of foundational models that are relevant in the top-down sensor domain.
Segment Anything#
In March 2023, Facebook AI Research released Segment Anything Model (SAM). SAM was trained on a massive dataset of 1 billion masks—data that is 100 times the order of magnitude of ImageNet or COCO, two other popular pretraining datasets in computer vision.
With SAM, users can drop a point on objects in satellite imagery and, in many cases, automatically generate great segmentation predictions. This model uses a two-stage prediction approach. First, an encoder converts an image to image features (embeddings). Then, a decoder takes an encoded prompt and a user supplied input (point(s), bounding box, or text), converting them into segmentation masks that delineate the boundary of an object or objects (Figure 1).
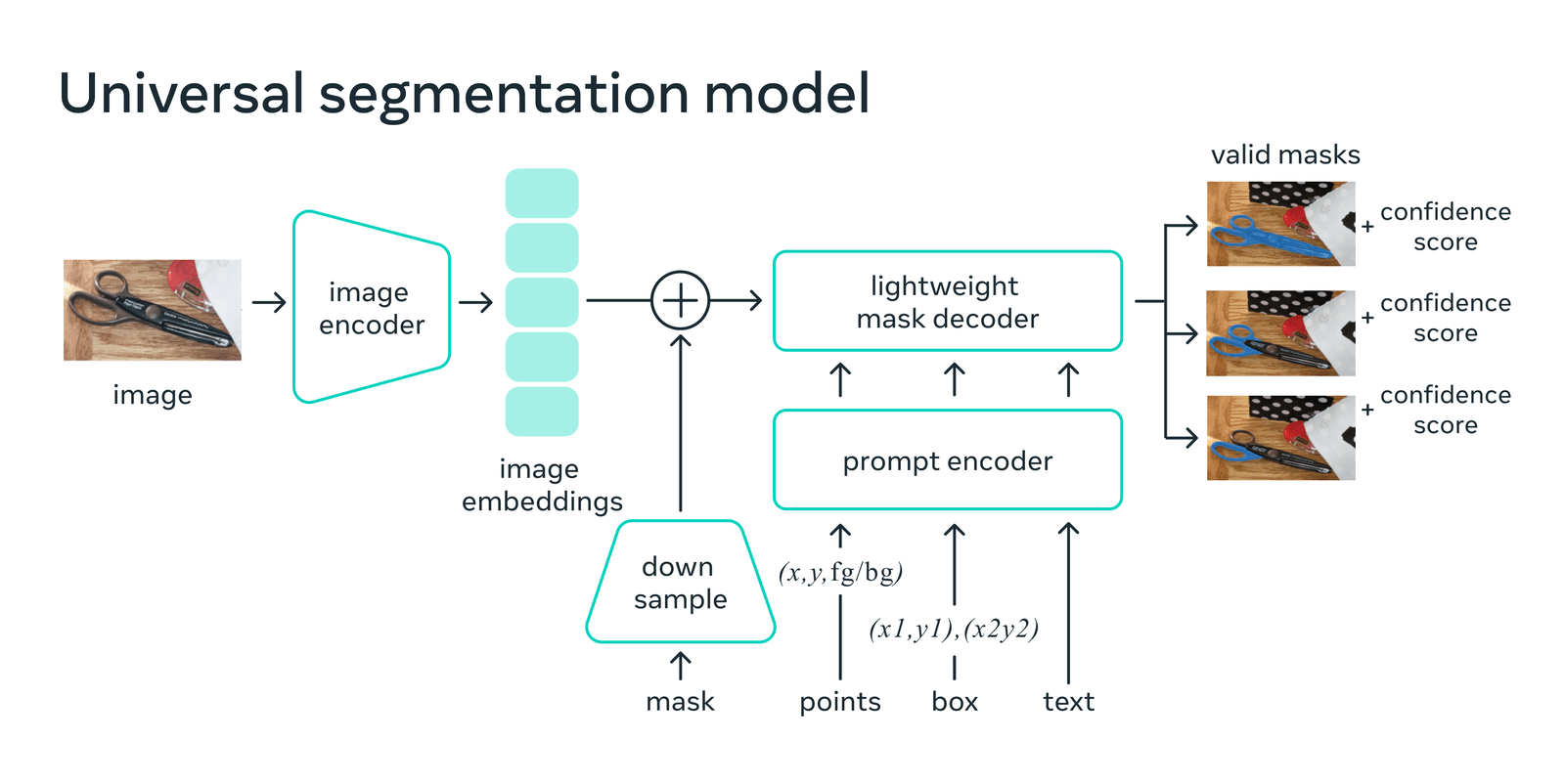
Fig. 42 The Segment Anything Model Architecture from “Introducing Segment Anything: Working toward the first foundation model for image segmentation” by Meta.#
In our initial explorations, SAM is more robust and has better domain adaptability than Imagenet or COCO pre-trained weights out of the box. What’s more, SAM can be adapted on the fly for particular detection problems through user prompting! With prompting, as a user supplies inputs that relate to objects of interest, the model adapts to get better at generating segments for the problem at hand.
We at Development Seed and other in the GeoAI community have tested SAM on satellite images and found remarkable performance with no out of the box training when SAM is used in model-assisted annotation workflows. Fine-tuning SAM is still an active area of research, but results in the medical imaging community show strong performance on domain specific benchmarks.
The SAM model is open sourced under a permissive Apache 2.0 license. We’ve released a deployable, containerized version of the model, announced here: https://developmentseed.org/blog/2023-06-08-segment-anything-services
Alternatives to Vision Transformers#
While vision transformers are powerful architectures, a big limitation is the lack of foundational models trained in the remote sensing domain. Because of the lack of CNN priors, vision transformers can learn more helpful image features but can also be more difficult to train with limited data. Because of this, be aware of other approaches that can work with limited labeled datasets that are typical in remote sensing. In the next section, we’ll cover approaches we’ve used at Development Seed for change detection and mapping, including U-Net and TinyCD. We’ll also cover state of the art pixel based approaches that have recently demonstrated strong performance in the remote sensing domain.
References#
[iii] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., … Guo, B. (2021). Swin transformer: hierarchical vision transformer using shifted windows. Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 10012–10022).