
We used AI to help UNICEF identify unmapped schools across Asia, Africa, and South America

Building on our success mapping 23,100 unmapped schools in eight countries.
By: Zhuangfang NaNa Yi, Naroa Zurutuza, Do-Hyung Kim, Ruben Lopez Mendoza, Martha Morrissey, Chuck Daniels, Nick Ingalls, Jeevan Farias, Karito Tenorio, Pilar Serrano, Sajjad Anwar
UNICEF's Giga Initiative endeavors to map every school on the Planet. Knowing the location of schools is the first step to accelerate connectivity, online learning, and initiatives for children and their communities, and drive economic stimulus, particularly in lower-income countries. Development Seed is working with the UNICEF Office of Innovation to enable rapid school mapping from space across Asia, Africa, and South America with AI. In seven months of development and implementation, we added 23,100 unmapped schools to the map in Kenya, Rwanda, Sierra Leone, Niger, Honduras, Ghana, Kazakhstan, and Uzbekistan.
To accomplish this we built an end-to-end scalable AI model pipeline that scans high-resolution satellite imagery from Maxar, applies our highly refined algorithm for identifying buildings that are likely to be schools, and flags those schools for human review by our talented Data Team. You can view our interactive maps of schools before and after the project for all countries we mapped, and examples of unmapped schools we found through the project.
Scanning high-resolution imagery of large sections of the planet is a massive undertaking. Accomplishing an effort of this scale gave us the opportunity to make improvements to our scalable AI tool (will be open-sourced soon), from efficient model training and experiments with Kubeflow on Google Kubernetes Engine, fast model inference with ML-Enabler, and data curation tools. We are proud to contribute these advances with AI for Good communities through advancing open datasets and open source libraries.
This post focuses on tile-based school classifiers. We developed and refined multiple tile-based models: six country-specific models, two regional models (West and East African models), and a global model.
Six country-specific, two regional, and a global school models
Background
Accurate data about school locations is critical to provide quality education and promote lifelong learning. Quality education is a core UN Sustainable Development Goal 4 (SDG4), and directly supports other Goals to achieve equal access to opportunity (SDG10) and eventually, to reduce poverty (SDG1). However, in many countries, educational facilities’ records are often inaccurate, incomplete or non-existent. An accurate, comprehensive map of schools -- where no school is left behind -- is necessary to measure and improve the quality of learning. Such a map, in combination with connectivity data collected by UNICEF’s Giga initiative, can be used to reduce the digital divide in education and improve access to information, digital goods, and opportunities for entire communities. In addition, understanding the location of schools can help governments and international organizations gain critical insights into the needs of vulnerable populations, and better prepare and respond to exogenous shocks such as disease outbreaks or natural disasters.
Aligned with the mission of the Giga initiative, we developed an AI-assisted rapid school mapping capability and deployed it in 8 countries in Asia, Africa, and South America. This capability combines two AI modeling approaches: a) we built a set of tile-based school classifier, which is a high-performing and accurate binary classification convolutional neural network, to search through 71 million slippy map tiles in 60cm of high-resolution Maxar Vivid imagery and identify tiles that are likely to contain schools, and b) a direct school detection AI model. This post focuses on tile-based school classifiers. We developed and refined multiple tile-based models: six country-specific models, two regional models (West and East African models), and a global model.
The East African regional model was trained with data from Kenya and Rwanda. The West African regional model was trained with data from Sierra Leone and Niger. The global models were trained with all countries’ school datasets. Regional and global models were trained to generalize well in the geo-diverse landscape; by testing the East African regional and Kenya tile-based school classifier models in Kenya, we found the regional model outperformed the country-specific models. It indicates that the model that was exposed to diverse looks and school features can outperform the model that only trains with limited features in less geo-diverse backgrounds. You can read detailed results below and in our technical report.
The regional model outperformed the country-specific models, which indicates that the model that was exposed to diverse looks and school features can outperform the model that only trains with limited features in less geo-diverse backgrounds.
The regional model outperformed the country-specific models
Training Datasets
Following our past successful research and school mapping exercise in Colombia (see the past report and blog post), we identified a set of identifiable school features from the overhead high-res satellite imagery. These features can be observed from space and have clear features, e.g. building size, shape, and facilities. Compared to the surrounding residential buildings, schools are bigger in size and the shapes vary from U, O, H, E, or L.
Despite their varied structure, many schools have identifiable overhead signatures that make them possible to detect in high-resolution imagery with modern deep learning techniques.
These identifiable school features were feature-engineered as supertiles. A supertile is 512x512x3 instead of regular slippy map tile of 256x256x3. It contains more spatial information and is also in a higher spatial resolution (see the following figure). We found that supertiles provide more spatial information with higher dimensional imagery and improved the model performance for all countries’ specific models.
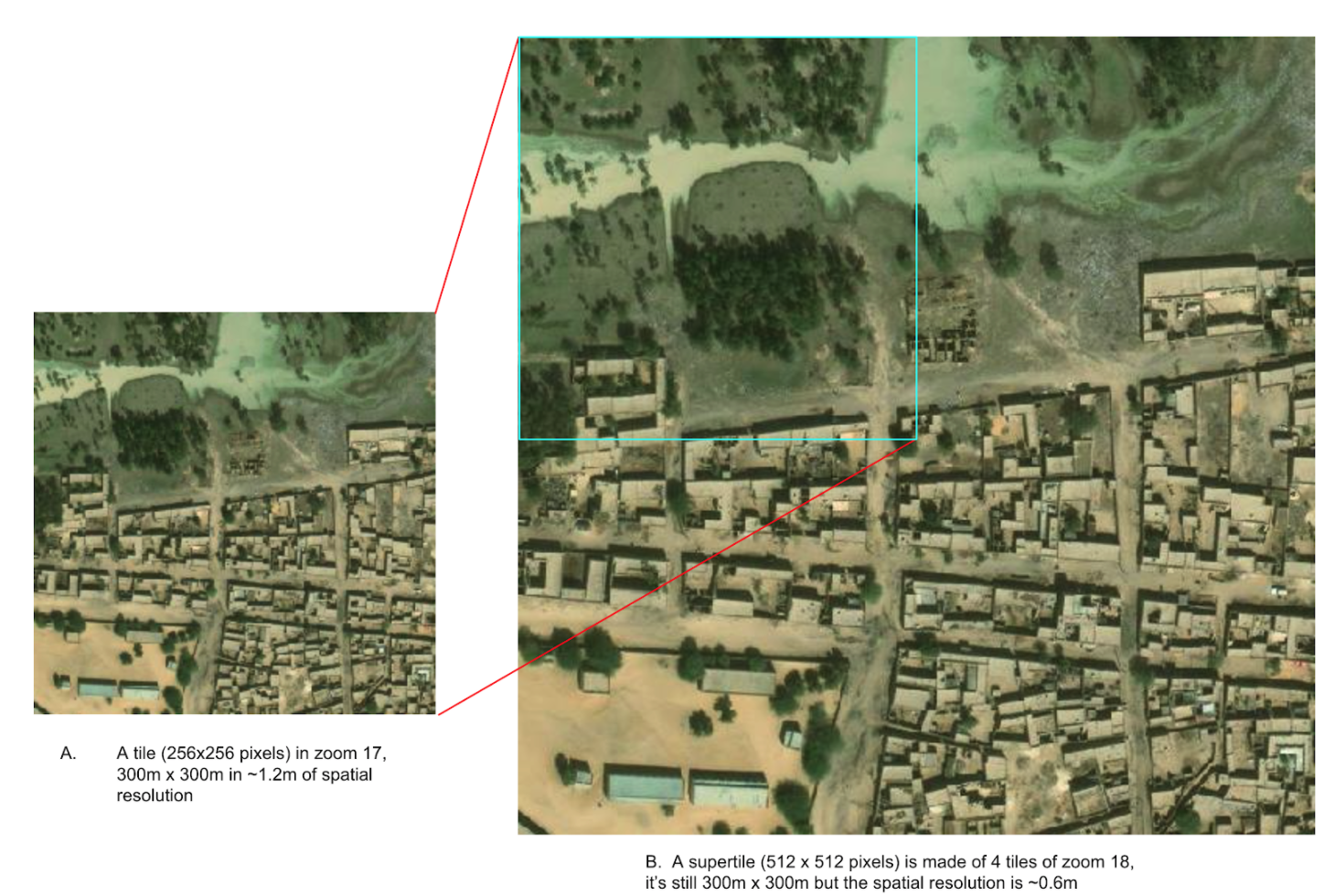
A supertile of zoom 17 (on the left) is made of 4 zoom 18 tiles (on the right). The supertile represents higher spatial resolution and higher image dimension (512x512 pixels) compared to the original 256x256 pixels tile in zoom 17.
Results
We trained six country models, and kept aside two countries as test. The trained country models performed well with the validation dataset such that their F1 scores were above 0.9 except for the Niger country model (0.87). The detailed model evaluation metrics, including precision, recall and F-beta scores can be visualized through the following table.
| Model | Training supertiles | Tensorboard link | Best scores from model evaluation |
|---|---|---|---|
| Honduras | 8,528 | Tensorboard | F_beta: 0.90, Precision: 0.90, Recall: 0.90 |
| Sierra Leone | 15,394 | Tensorboard | F_beta: 0.91, Precision: 0.92, Recall: 0.91 |
| Niger | 8,195 | Tensorboard | F_beta: 0.87, Precision: 0.89, Recall: 0.89 |
| Rwanda | 6,411 | Tensorboard | F_beta: 0.94, Precision: 0.94, Recall: 0.94 |
| Kazakhstan | 11,993 | Tensorboard | F_beta: 0.92, Precision: 0.93, Recall: 0.92 |
| Kenya | 12,200 | Tensorboard | F_beta: 0.90, Precision: 0.92, Recall: 0.92 |
| West Africa | 23,589 | Tensorboard | F_beta: 0.91, Precision: 0.91, Recall: 0.91 |
| East Africa | 18,611 | Tensorboard | F_beta: 0.92, Precision: 0.91, Recall: 0.92 |
| Global model | 62,721 | Tensorboard | F_beta: 0.85, Precision: 0.85, Recall: 0.84 |
All the country models and regional models under tile-based school classifier performed well over the validation datasets. Click on the “Tensorboard” dev links to scrutinize F1, recall and precision scores.
Despite their varied structure, many schools have identifiable overhead signatures that make them possible to detect in high-resolution imagery with deep learning techniques. Approximately 18,000 previously unmapped schools across 5 African countries (Kenya, Rwanda, Sierra Leone, Ghana, and Niger), were found in satellite imagery with a deep learning classification model. These 18,000 schools were validated by expert mappers and added to the map. We also added and validated nearly 4,000 unmapped schools to Kazakhstan and Uzbekistan in Asia, and an additional 1,100 schools in Honduras. In addition to finding previously unmapped schools, the models were able to identify already mapped schools up to ~80% depending on the country. To facilitate running model inference across over 71 million zoom 18 tiles of imagery, our team relied on our open-source tool ML-Enabler.
The detailed findings from tile-based school classifier country models are in the following table:
- the column “Known school” is validated school geolocations that have clear school feature;
- column “ML threshold” is the model confidence score threshold from each country model;
- the column “Total detected” are the total number of detected schools with the given ML threshold scores;
- “ML output validation” indicates after the expert mappers validation of the ML outputs, the number of confirmed schools “Yes”, unrecognized schools “Un-reg” and “No” schools;
- “True capture” is the percentage of known schools that is correctly predicted by ML model and then confirmed by our expert mappers. The higher the percentage means the country ML model performed better;
- “Difference” is the number of schools that ML models did not find but are in “Known school”;
- “Reconfirmed” are the number of schools detected by ML models, validated by the expert mappers and are also in the “Known school”;
- Unmapped schools are the schools that currently are NOT on the map or in “Known school” but detected by ML models and validated by the expert mappers.
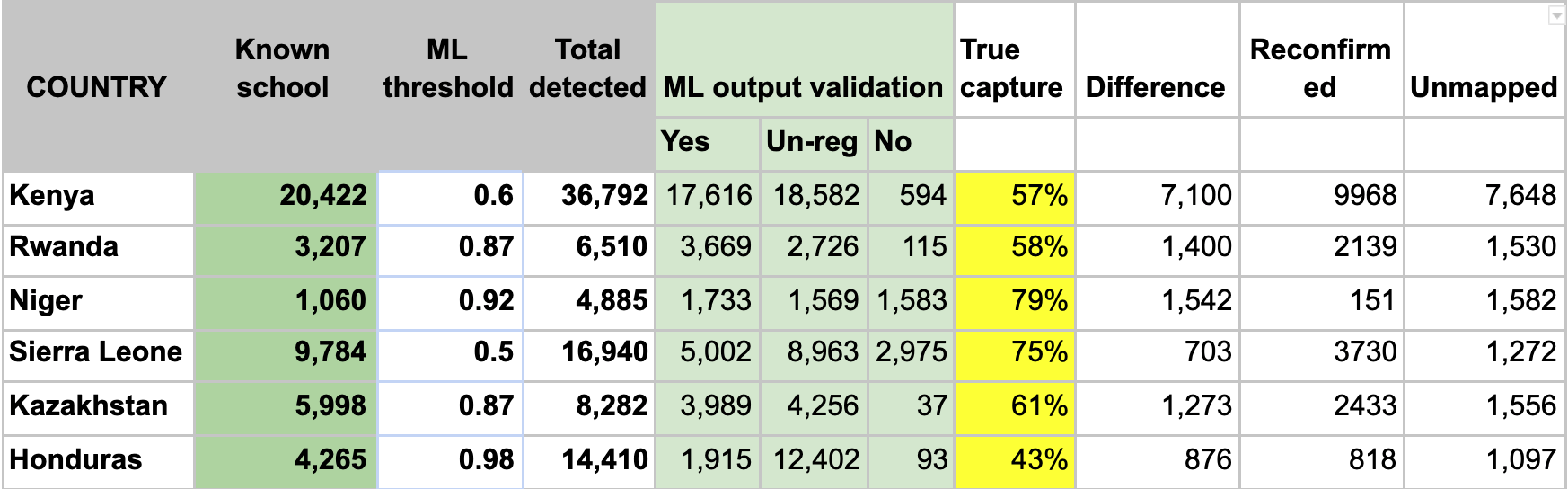
The six country models we trained obtained high F1 scores in test datasets. The models were able to identify already mapped schools up to ~80% depending on the country. At the end of the project, we added 18,000 unmapped/missing schools in Africa, 4,000 to Asia, and more than 1,100 in Honduras.
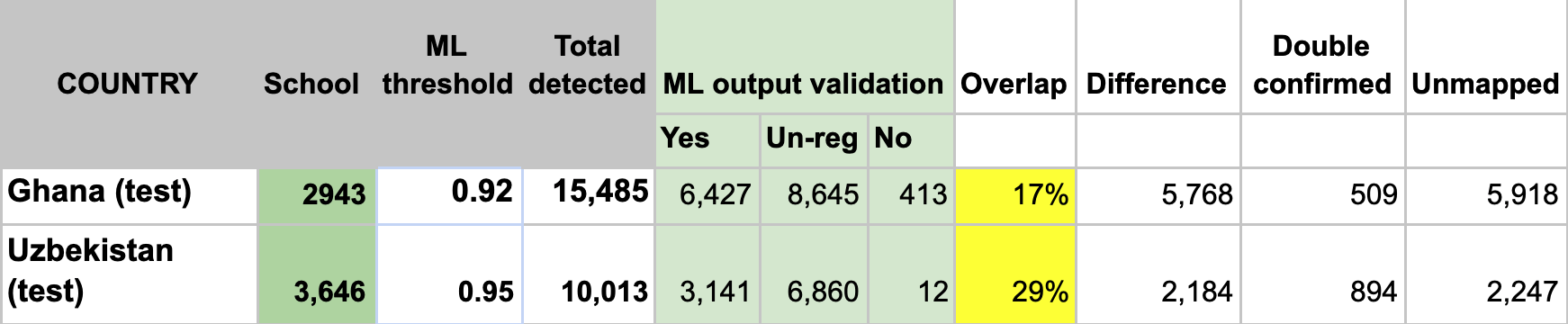
The two test countries, Ghana and Uzbekistan don’t have their own country model trained. We ran model inference in Ghana with the West African regional model that trained with Niger and Sierra Leone and applied the Kazakhstan country model to Uzbekistan. Even though the ML confidence scores were high to filter the ‘predicted’ schools tiles for both countries (see ML threshold column), we were able to identify a fair amount of double confirmed and unmapped schools in both countries. The high ML threshold scores indicate a lower false-negative rate, but we may also potentially miss a lot of true schools.
The country-specific unmapped schools can be explored via the GIFs or our online map viewers that we use basemap by © Mapbox.
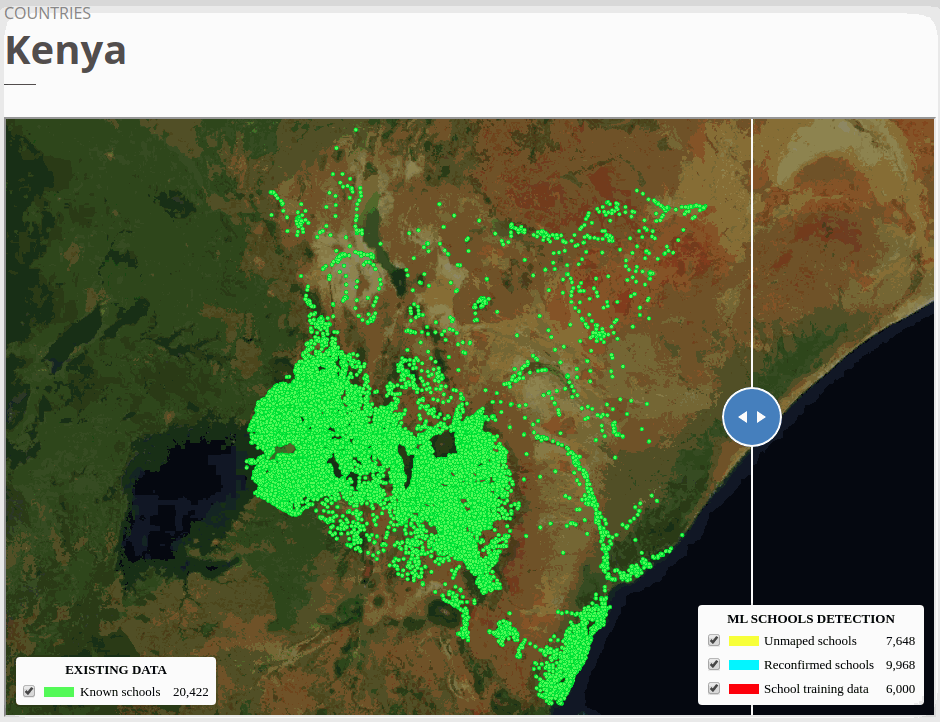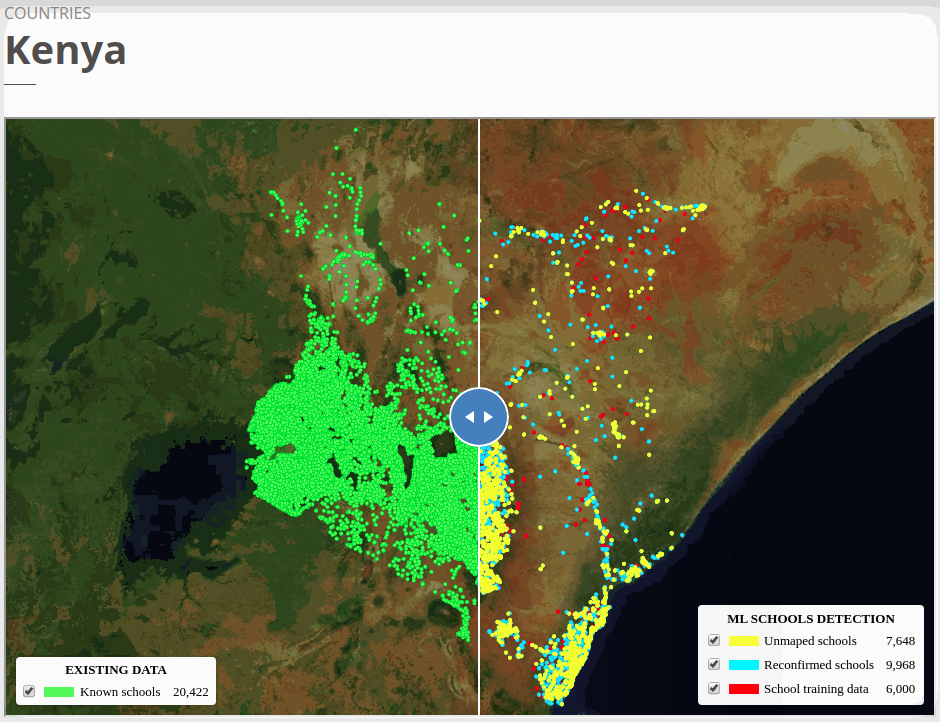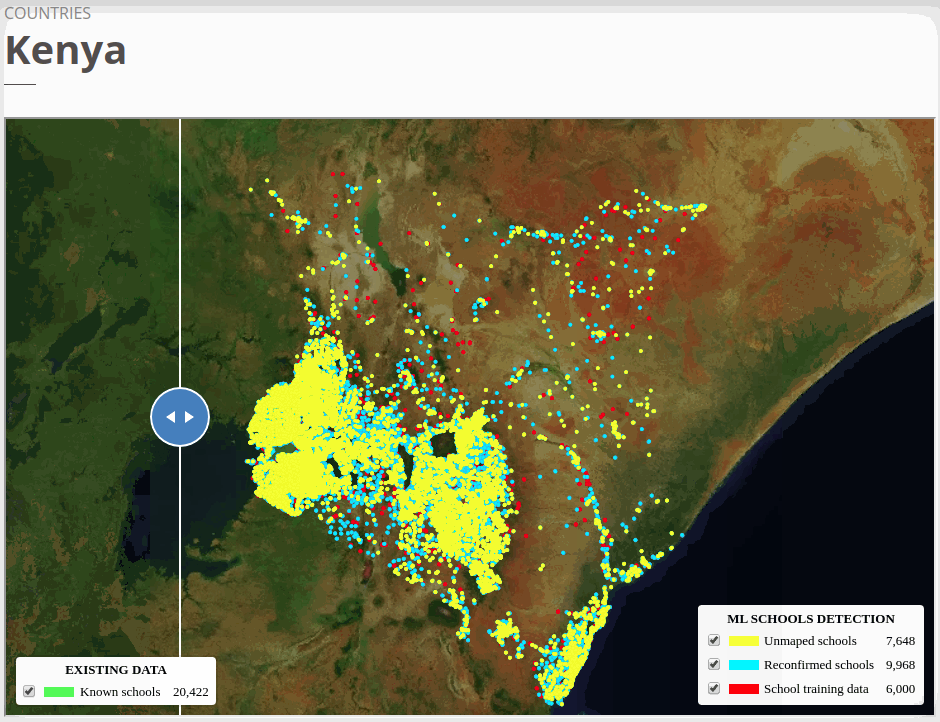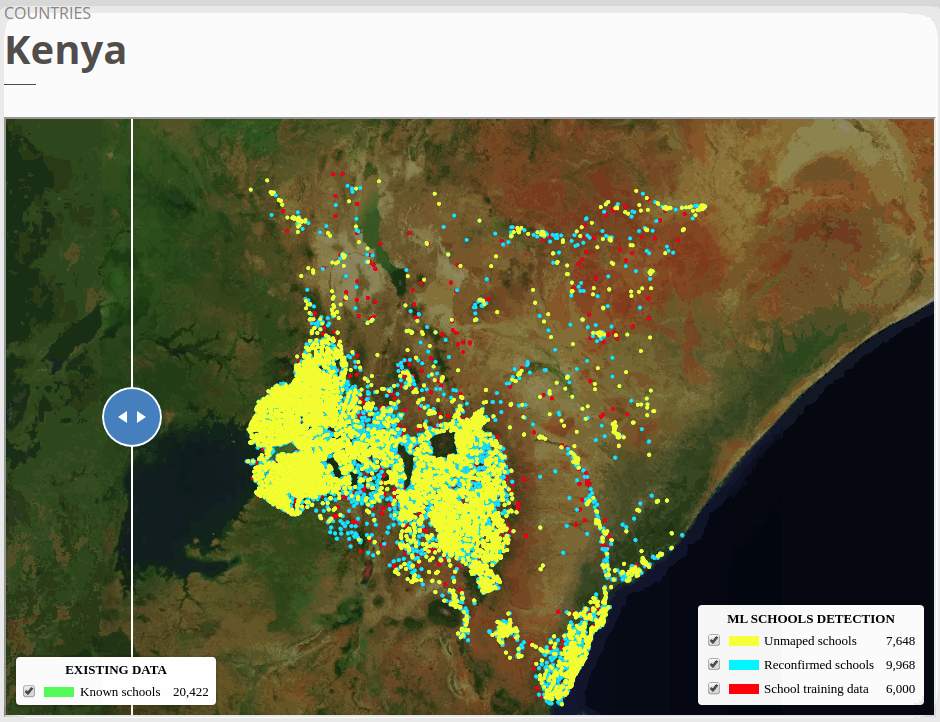
To view the online school map for Kenya, please go to the Kenya school map viewer. Basemap by © Mapbox.
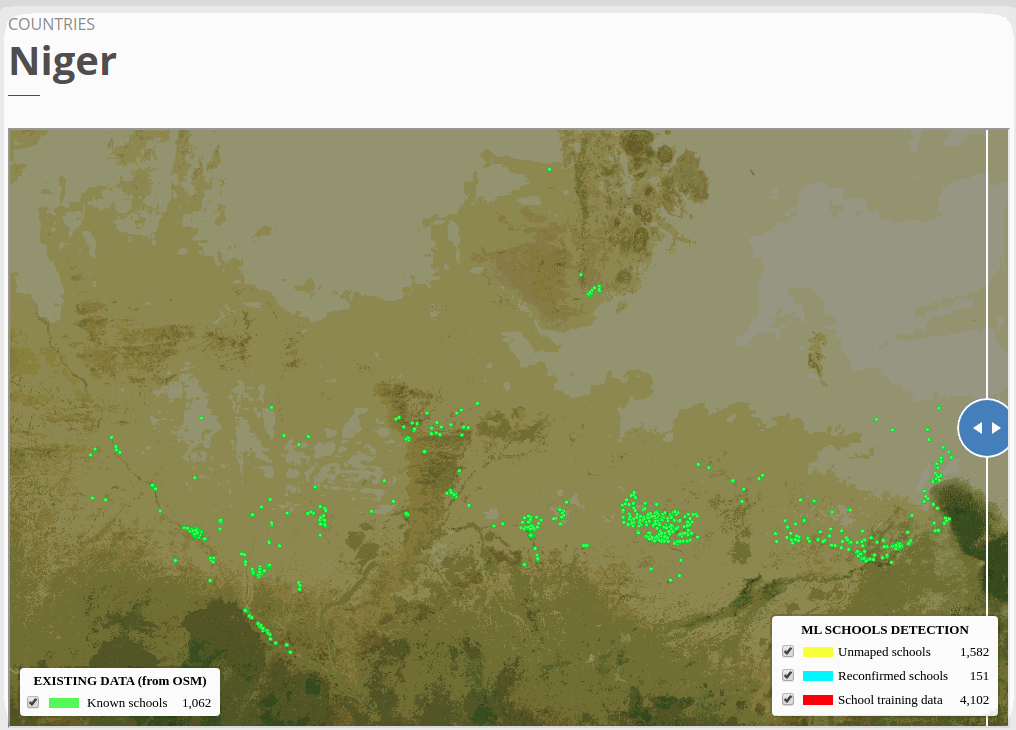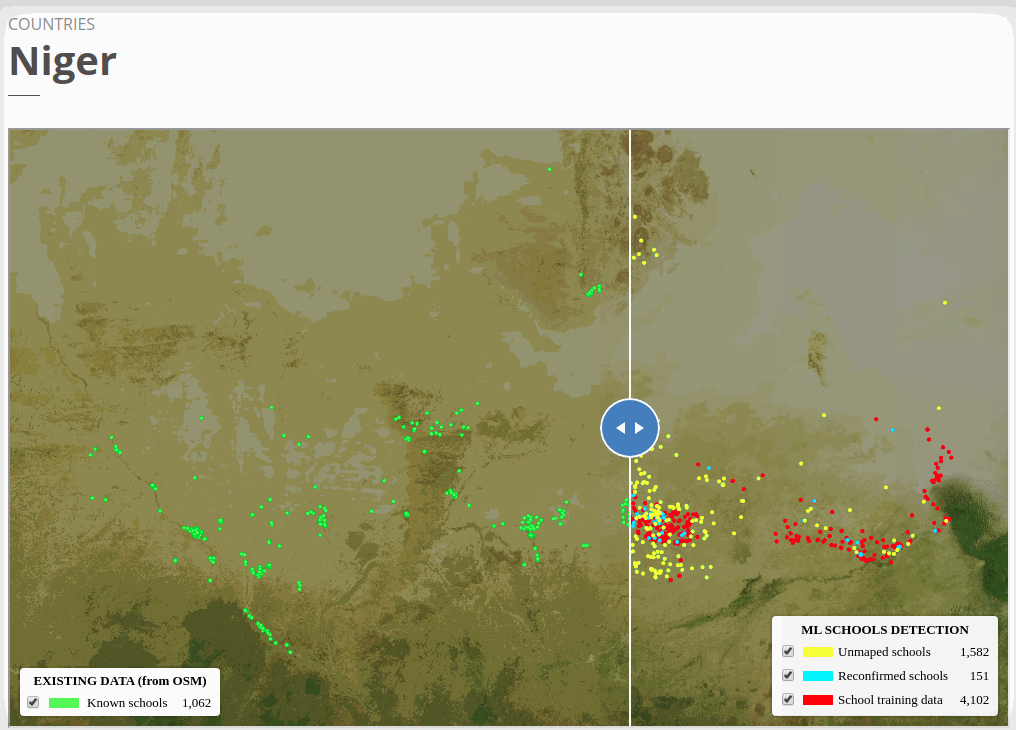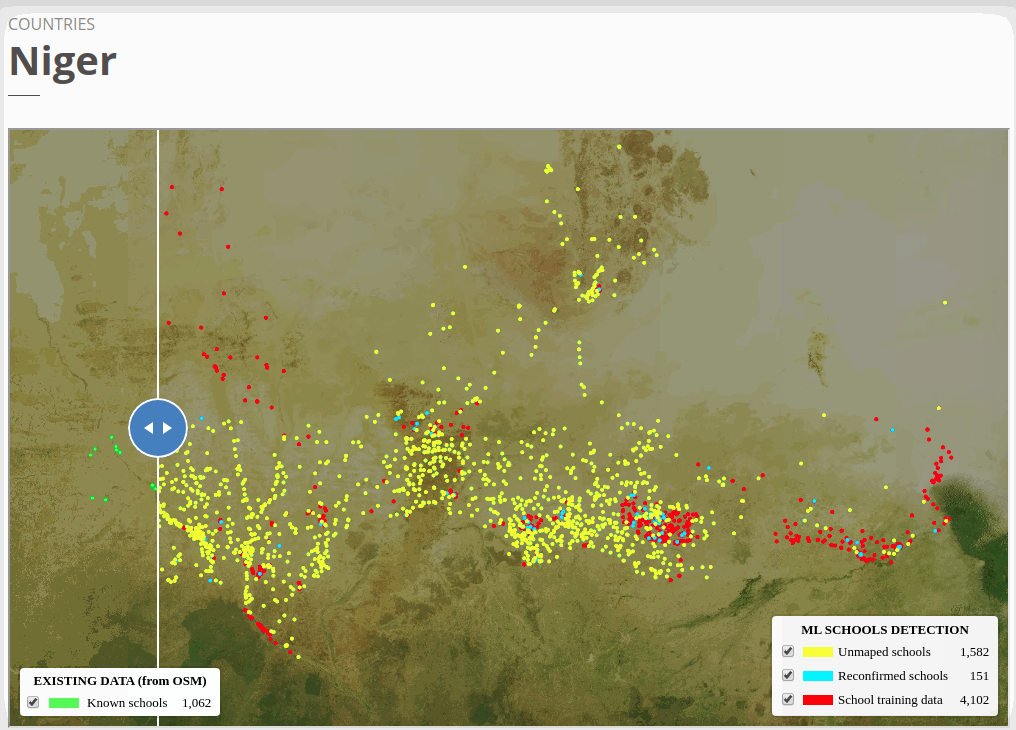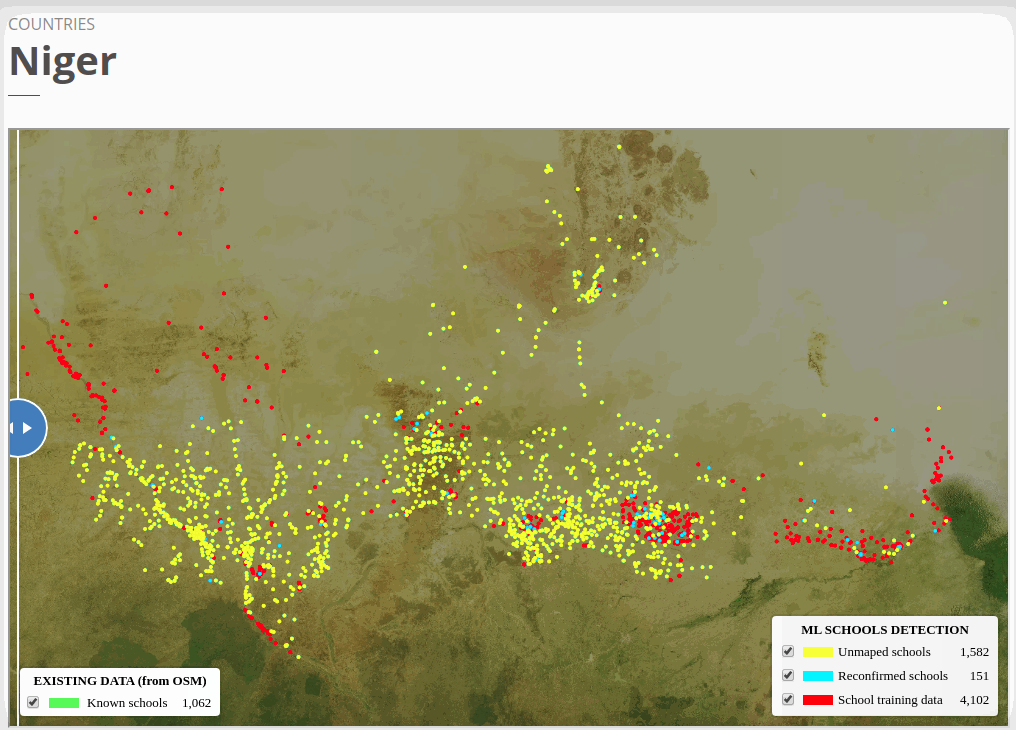
To view the online school map for Niger, please go to the Niger school map viewer.Basemap by © Mapbox.
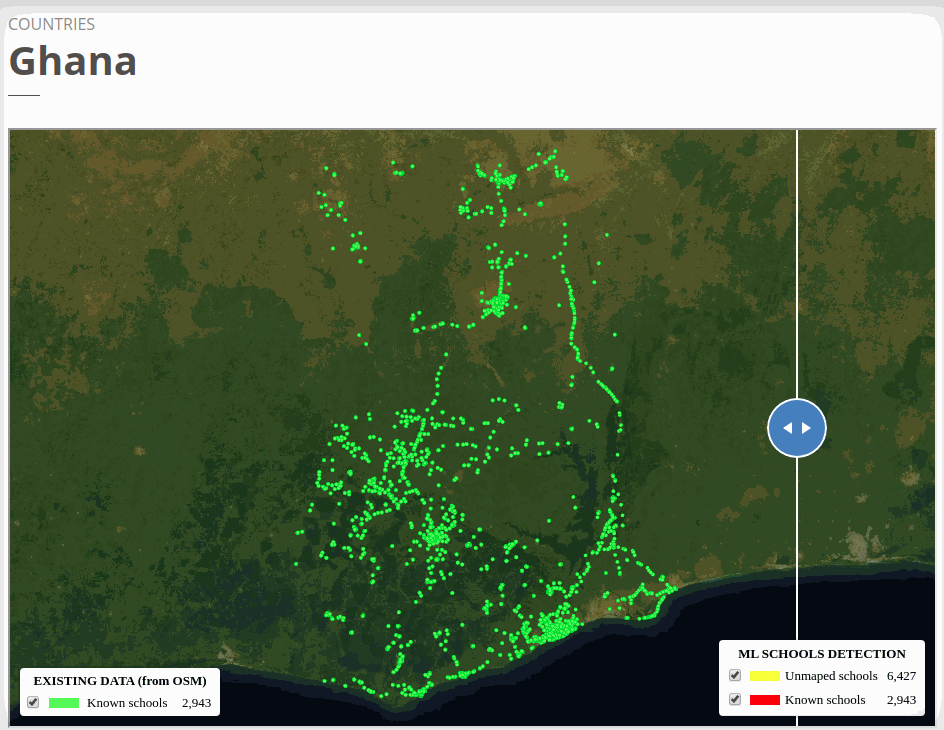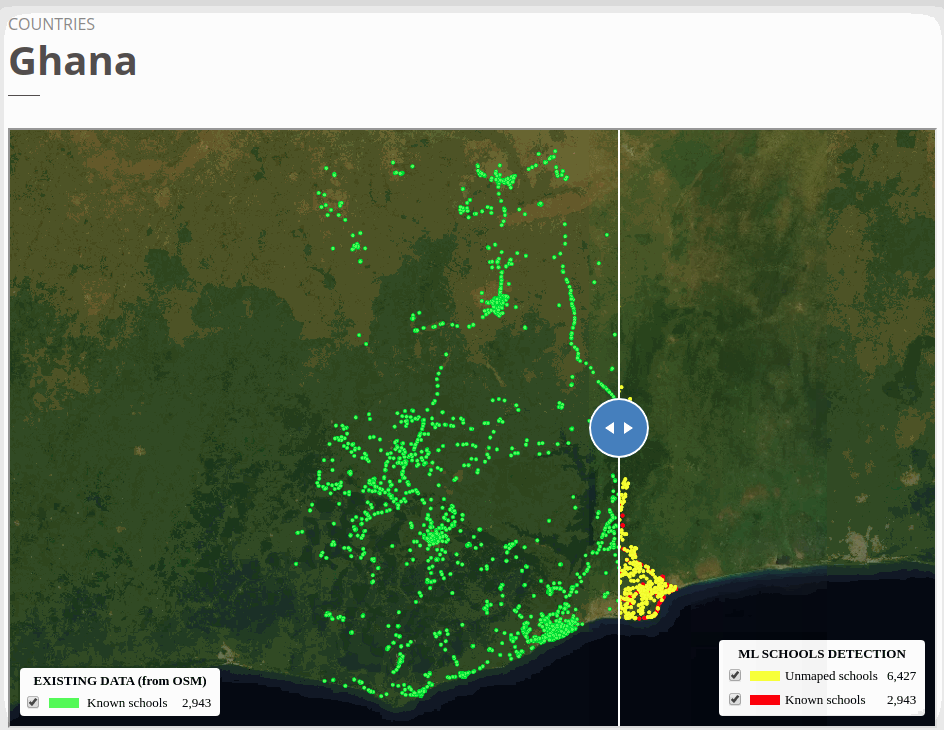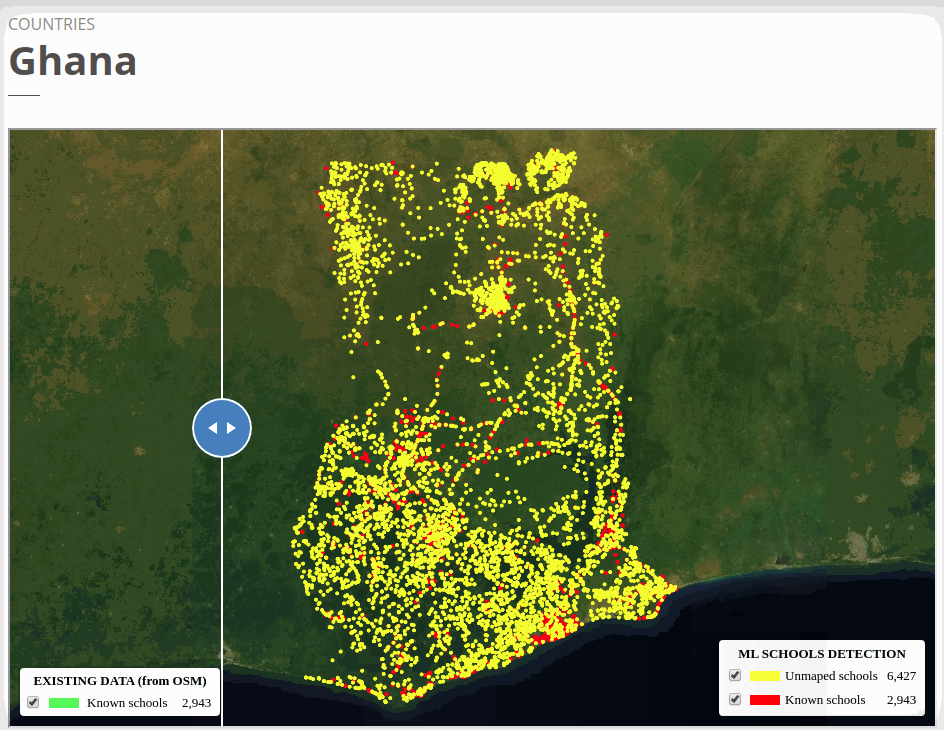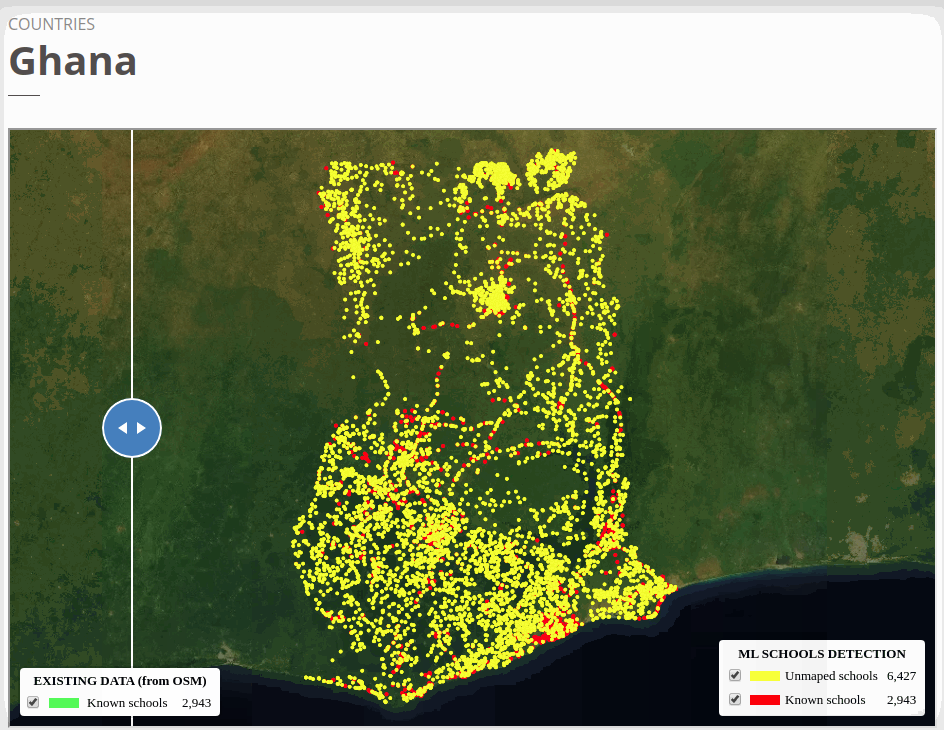
To view the online school map for Ghana, please go to the Ghana school map viewer. Basemap by © Mapbox.
What’s new in our scalable AI toolbox?
Scalable AI Model Training with Kubeflow
To quickly train the tile-based school classifier, we created a deep learning python package called “School-Classifier''. It is a deep learning package that utilizes pre-trained models from ImageNet, Xception.The package is designed to quickly install, transfer-learn, and fine-tune image classifiers with the built-in pre-trained models that can be deployed to Google Cloud Kubernetes Engine (GKE) with Kubeflow. Kubeflow is a tool that makes deployment of ML workflows on Kubernetes easier, simpler, portable, and scalable. The model training and experiment were deployed with a TFJob YAML file. Our school classifier pipeline can also be used to train other classifiers rather than just school mapping. The model was written using Keras, a high-level python package that allows users to quickly build neural networks with Google's TensorFlow as a backend.
The training dataset for each country model was split into train, validation, and test sets using a 70:20:10 ratio, respectively. When a model training was kicked off to a GKE Cluster with TFJob, the model was trained and validated with train and validation sets using F1, precision, and recall scores (see the above table with Tensorboard links). The training is tracked and monitored by Tensorboard. TensorBoard is a TensorFlow's visualization toolkit that is tracking and visualizing metrics such as loss and accuracy during model training. For more information please refer to our technical report.
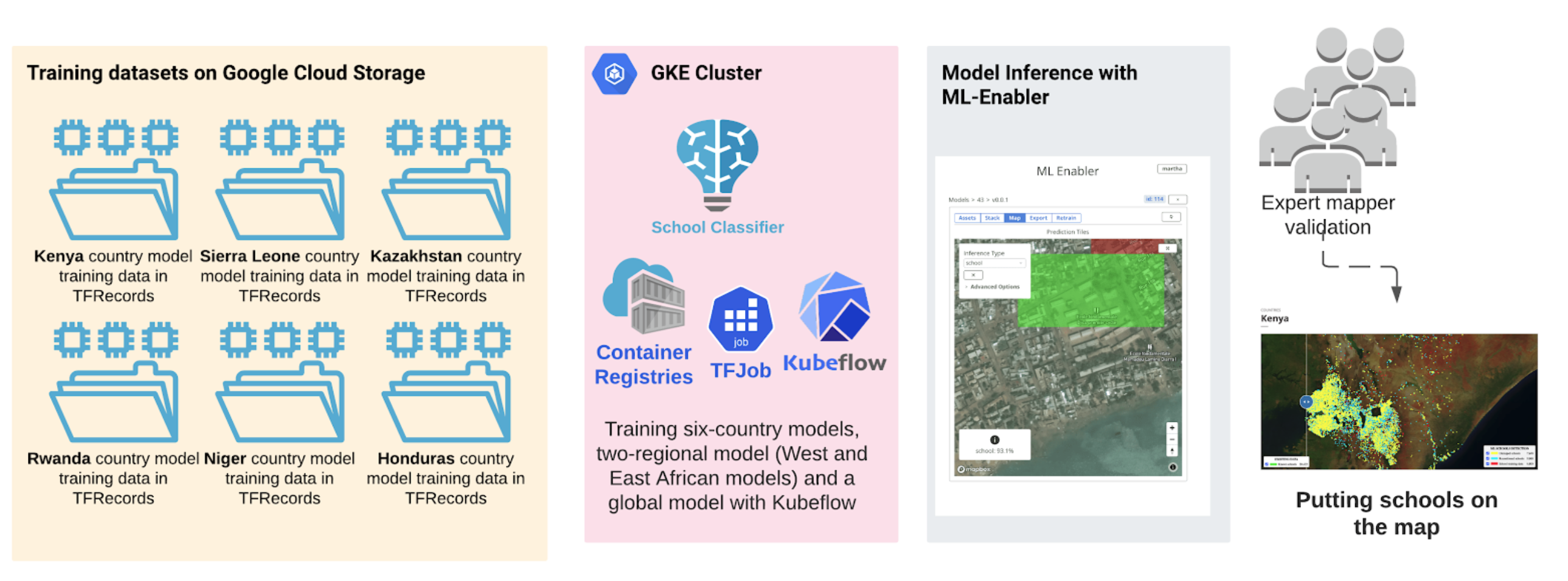
We trained six country models (Kenya, Sierra Leone, Kazakhstan, Rwanda, Niger and Honduras), two regional models (West and East Africa regional models) and a global model under tile-based school classifier model training. The model training and experiment were deployed to GKE with Kubeflow and TFJob.
Scalable Model Inferences with Development Seed ML-Enabler
We use ML-Enabler to apply our models to imagery. ML-Enabler provides a model repository and allows us to quickly select a model, run inference at scale on the cloud, and save and compare results between different model versions. ML-Enabler was developed in partnership between Development Seed and the Humanitarian OpenStreetMap Team as a tool to speed up human mappers in the OSM community. ML-Enabler is very fast. For our tile-based school classifier model, ML-Enabler processes up to 2000 supertiles per second (120,000 supertiles per minute). Running inference over 18 million supertiles in eight countries took us about 25 hours. This is a super-efficient way to scan through millions of tiles and look for given school features.
ML Enabler generates and visualizes predictions from models that are compatible with TensorFlow’s TF Serving, on-demand. All you need is to drag and drop a zipped trained model, provide a Tile Map Service (TMS) endpoint, and polygon of your area of interest (AOI) for the inference. ML-Enabler will spin up the required Amazon Web Services (AWS) resources and run inference to generate predictions.
With more than 113,000 candidate schools detected across our 8 target countries with the AI models, validation took us 105 hours instead of 450 hours.
Tools to maximize the speed of data curation
Data Curation Tools
The ultimate goal of this project is to develop six country tile-based school classifier models that would be generalized and well-performing to accomplish school mapping tasks. The tasks not only include whether or not the models can identify known schools but also can find “school-like” building complexes in Asia, Africa and South America. To be able to do so, the high-quality training datasets that have very distinguished schools feature on the overhead imagery is the key.
We've invested heavily in tooling that allows our Data Annotator and Data Validator to maximize speed while maintaining the extremely high accuracy that our models demand. We created Chip-Ahoy (will be open-sourced), to validate ML output schools into three categories: yes, no, and un-recognized schools. Our past speed for ML school validation was 250 schools/hour, and we could validate 1083 tiles/hour (a school may cover >= 1 tile) with Chip Ahoy now, which is more than four times faster. The data validation pipeline is applied twice, once for creating training data and again for validating the predictions of the AI model. With more than 113,000 candidate schools detected across our 8 target countries with the AI models, validation took us 105 hours instead of 450 hours.
Development Seed is engaged in active research and development of human-in-the-loop active learning methods that allow non-expert human mappers and AI to work more efficiently together and improve the model prediction power.
Using a human-in-the-loop active learning process is critical
Discussion and Challenges
An effort as ambitious as detecting every school is bound to have challenges. We've made useful progress on some of these but others remain.
We made important contributions around the technical challenges of scaling school classifier in very high-resolution imagery to the country- and continent-wide applications. We were able to solve model scalability issues by mindfully designing the internal data validation, model training on Google Kubernetes Cluster Engines (GKE) with Kubeflow, and model inference with our open-sourced tool, ML-Enabler. We are delighted to be contributing these improvements to open tools. The discussion section of our technical report describes a roadmap for addressing remaining technical challenges around model scalability, AI model selection, and human-in-the-loop and active learning methods.
A significant limitation of our approach is that it relies on human validators for both the training data creation and school validation. As a result, we acknowledge that we have introduced a bias for schools that follow common patterns and are recognizable from space. In the end, the model may be able to recognize schools that are in distinguished building complexes, similar buildings rooftop, having swimming pools or basketball courts, but may perform poorly at recognizing schools that have smaller building size, are in densely populated urban areas, or are house in "non-traditional" structures. It is reasonable to assume that this bias might disproportionately miss schools that serve poorer neighborhoods or already underrepresented communities. This bias would not exist in alternative (and likely more costly) approaches like field surveys and supporting community mapping.
Using a human-in-the-loop process is critical, especially leveraging people with local knowledge about local school features. Such knowledge is harder to transfer to expert mappers who may grow up in a different culture and architectural context of schools. Development Seed is engaged in active research and development of human-in-the-loop active learning methods that allow non-expert human mappers and AI to work more efficiently together and improve the model prediction power. By creating greater accessibility to provide human input into these models, we hope to increase the diversity of human knowledge contributing to these models and reduce sources of bias.
What we're doing.
Latest