
Over a year ago, we published ML Enabler — a machine learning integration tool in partnership with the Humanitarian OpenStreetMap Team. ML Enabler is a registry for machine learning models in OpenStreetMap and aims to provide an API for tools like Tasking Manager to directly query predictions. Today, we want to share some of the new and most exciting features of ML Enabler, including on-demand machine learning predictions and a user interface.
Managing models, predictions and infrastructure
ML Enabler makes it incredibly easy to spin up infrastructure to run your model along with all necessary resources. Through the new user interface, you can upload new models, spin up AWS resources, generate and preview predictions. Previously, there was a minimal CLI tool to upload models and fetch predictions.
 ML Enabler Project Overview
ML Enabler Project Overview
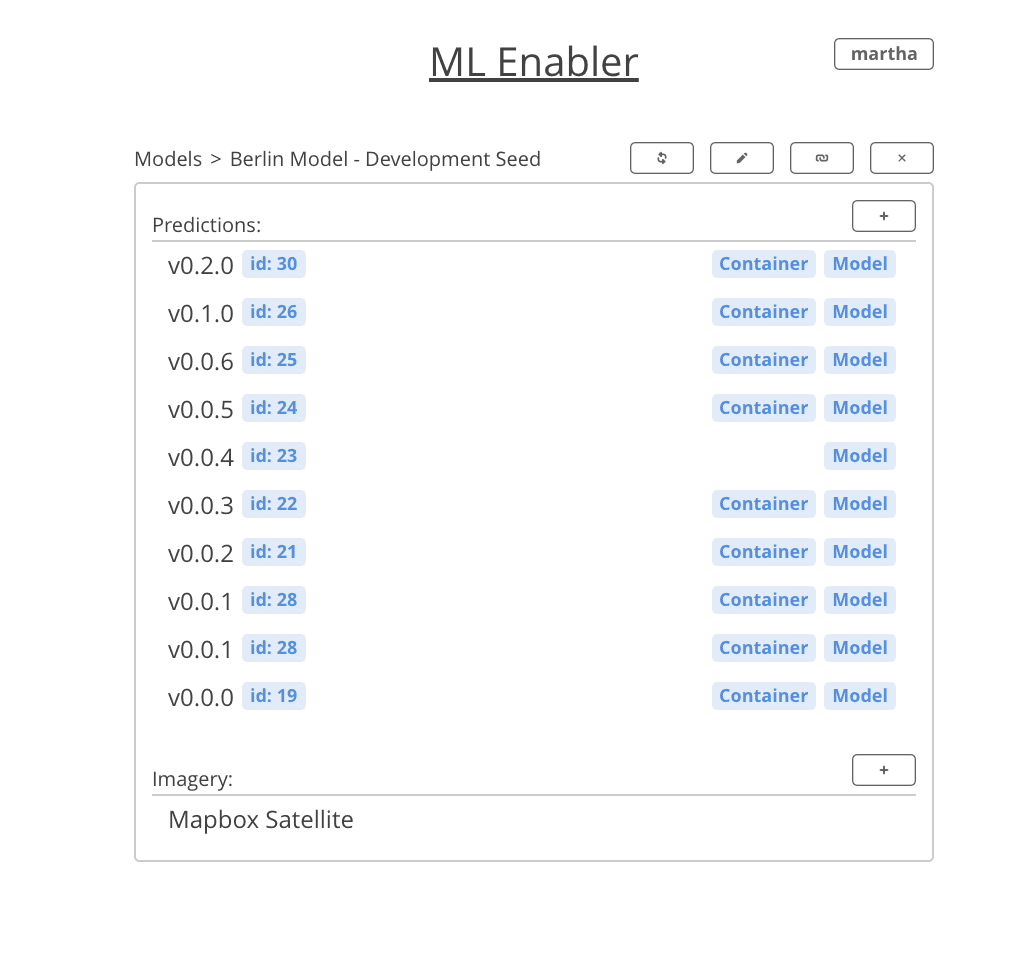 ML Enabler Project Page
ML Enabler Project Page
Behind the scenes, ML Enabler uses AWS Cloudformation and will work with any AWS account. A few key infrastructure choices like instance count, and concurrency can be made directly from the ML Enabler interface. ML Enabler uses lambda functions for downloading base64 images for inference from the specified Tiled Map Service (TMS) endpoint and writing inference outputs into the database.
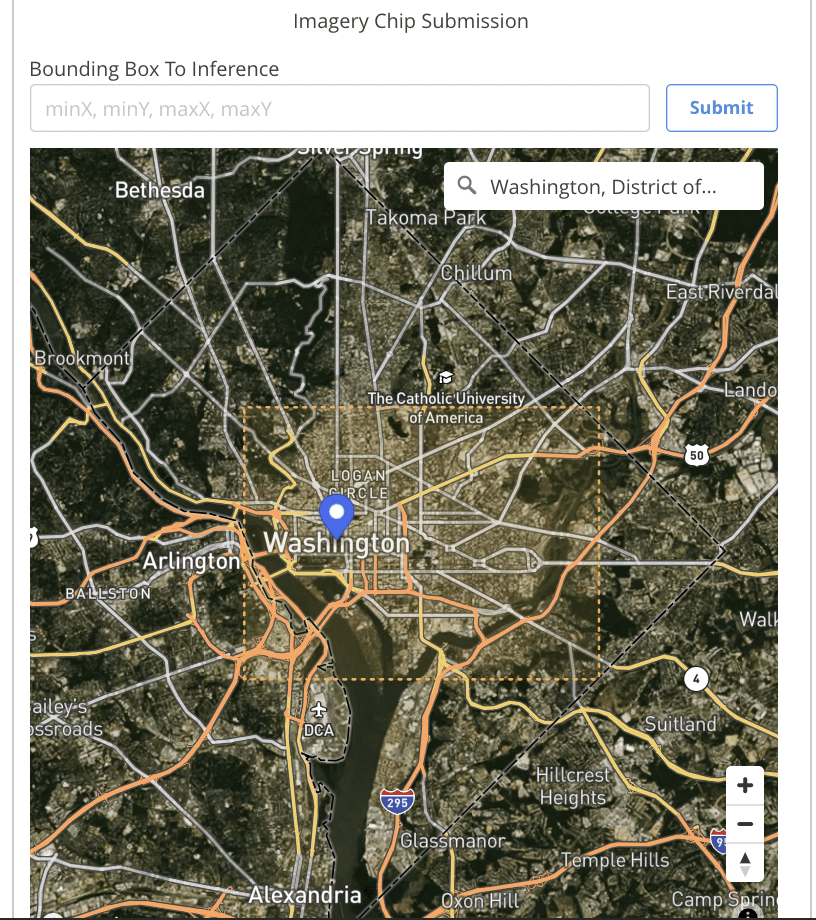 BBOX Inference Submission
BBOX Inference Submission
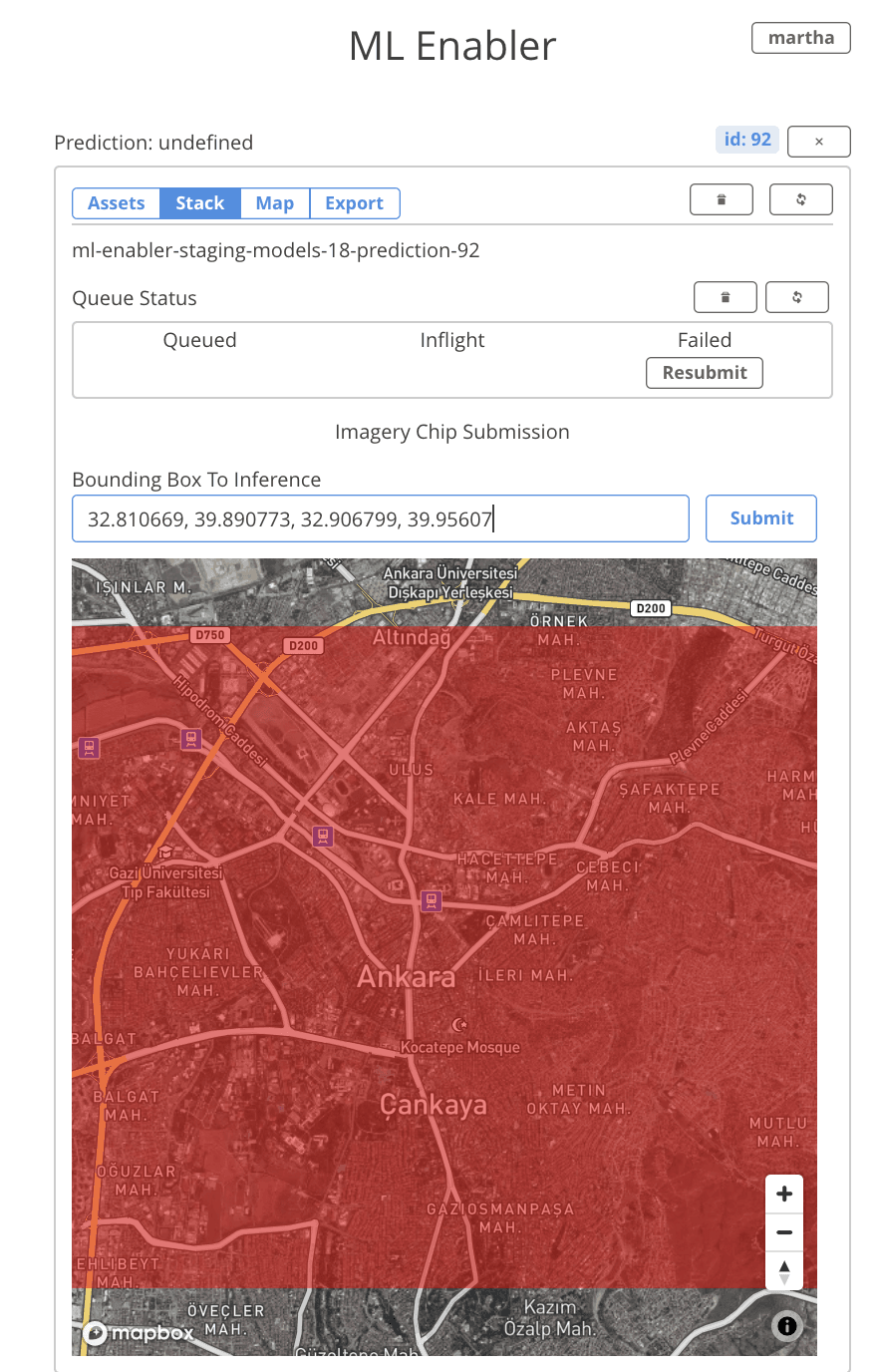 Running Inference Stack
Running Inference Stack
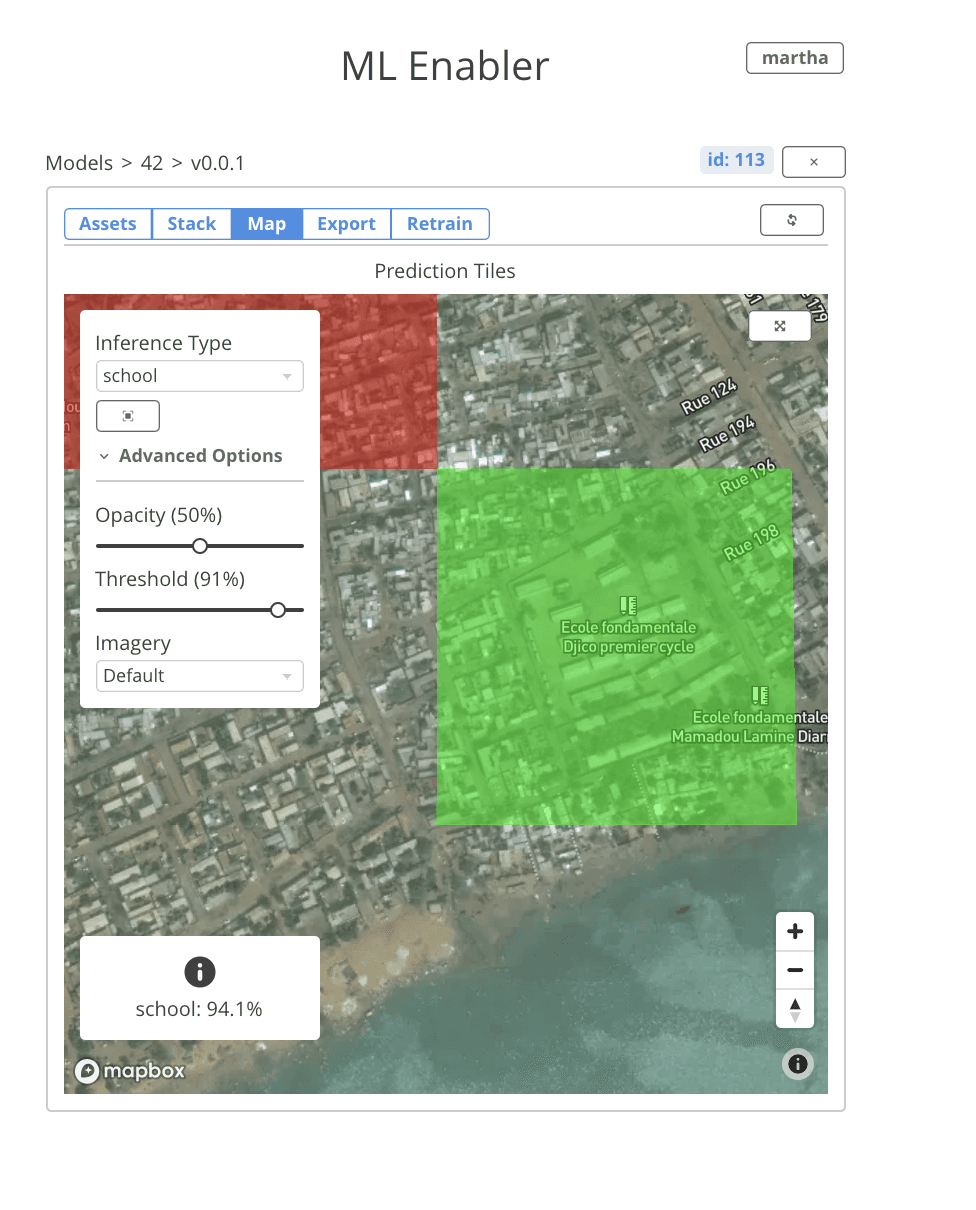
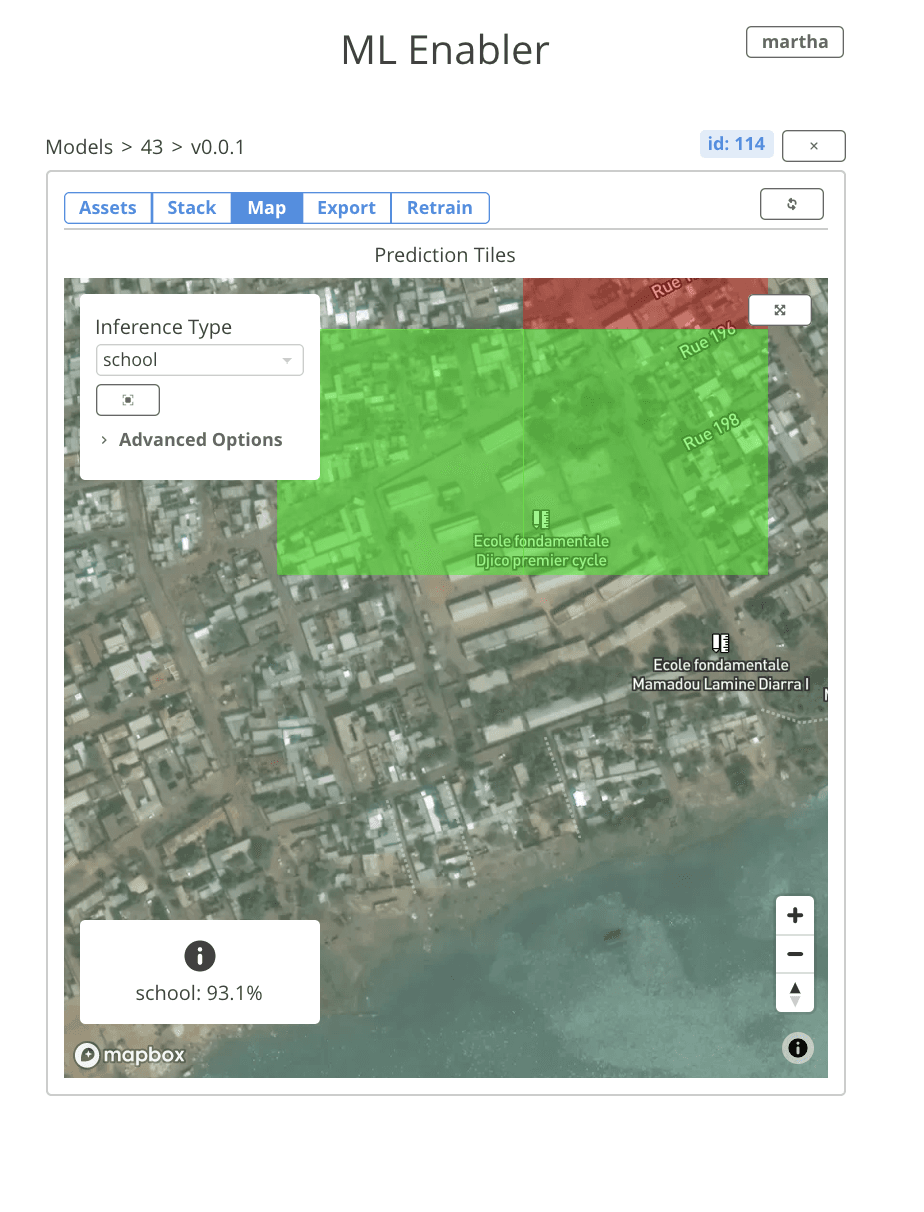
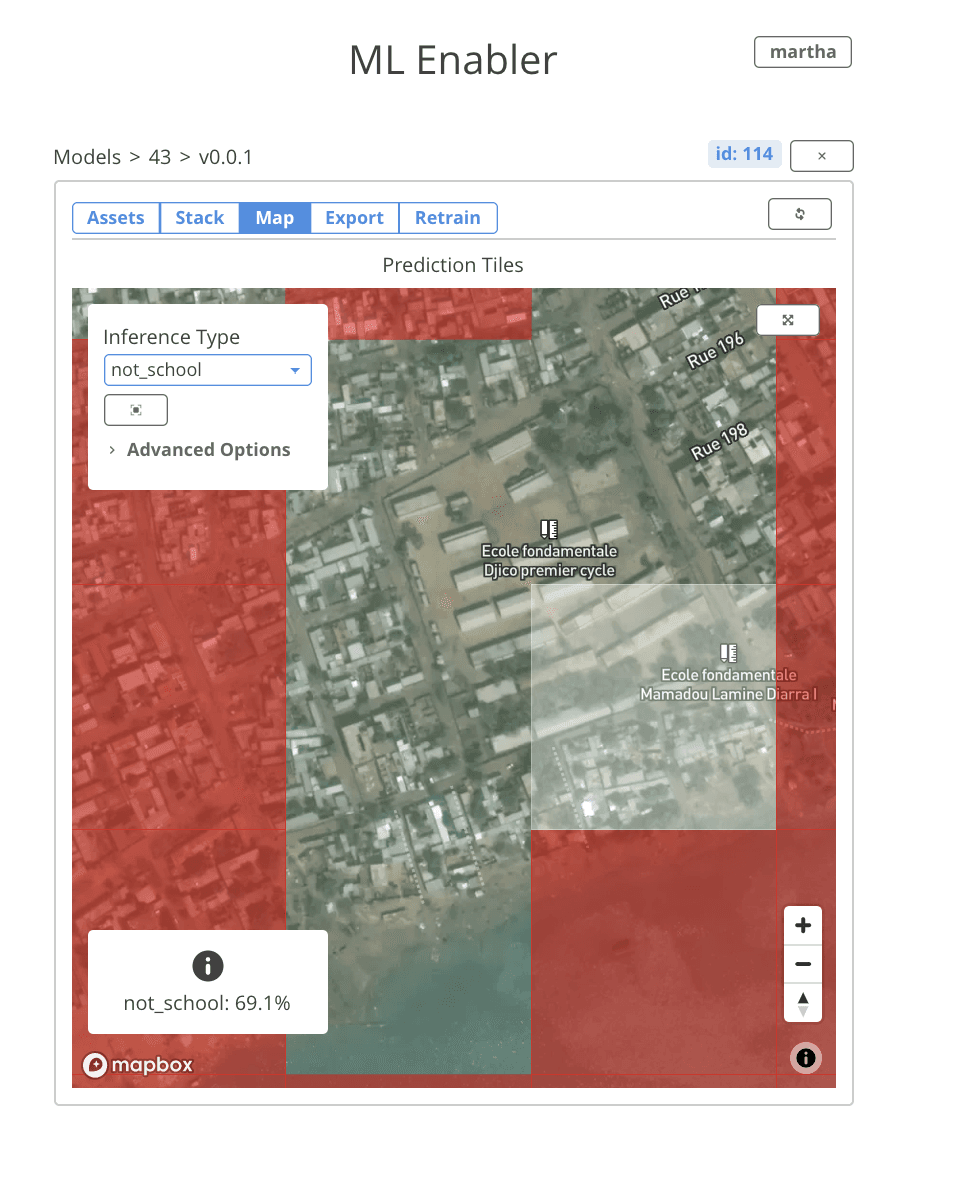
You can monitor the tile prediction queues right from the UI. When the processing is complete, predictions are automatically displayed in the map tab. It’s easy to toggle between different classes in your model, and filter predictions based on confidence threshold. Over each tile, the model’s raw output and the confidence score is displayed. This makes it really convenient to explore spatial patterns within the inferences.
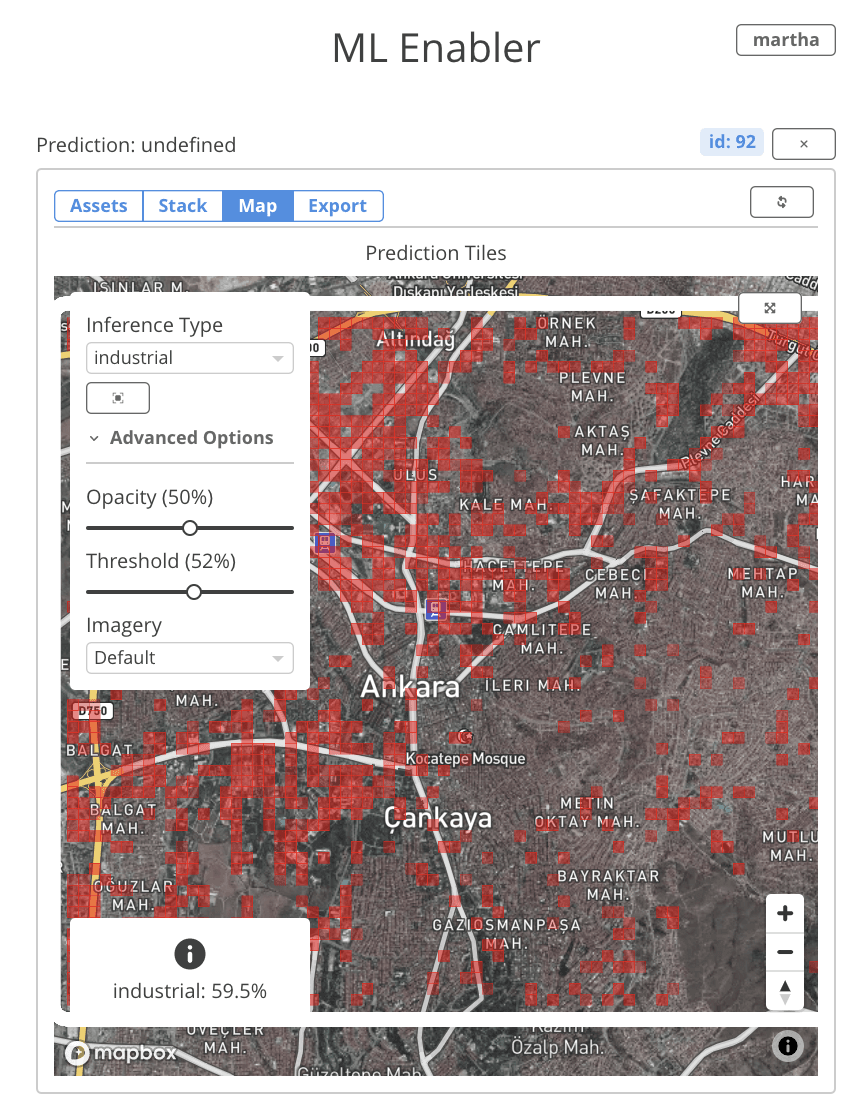 Inference Results Page
Inference Results Page
On-demand predictions
ML Enabler generates and visualizes predictions from models that are compatible with Tensorflow’s TF Serving, on-demand. All you need is to drag and drop a zip with trained classification or object-detection model, provide a TMS end point, and an AOI for the inference. ML Enabler will spin up the required AWS resources and runs inference to generate predictions. Running a classification model inference over a medium sized city, which is divided into approximately 4,000 zoom 18 tiles takes approximately 2 minutes.
The prediction tiles are indexed using quadkeys for easy spatial search. To help facilitate these on-demand predictions ML Enabler has integrated in many of the components of Development Seed’s Chip-n-Scale project.
Support for classification and object detection models
Currently, ML Enabler supports two common machine learning model formats — classification, and object detection. ML Enabler works with binary as well as multi-label classification models. The infrastructure setup and prediction visualization adapts automatically based on the model format. For object detection models, ML Enabler converts coordinates in the pixel space to geographic space for every prediction along with bounding box and confidence score.
 New Prediction Page
New Prediction Page
Additionally, for classification models, ML Enabler supports a custom lambda function to create supertiles. Supertiles are incredibly useful to overcome objects that may lie across tile edges. For example, zoom 18 tiles offers a higher resolution than zoom 17, but one draw-back is that sometimes buildings get split between multiple tiles. Supertiles allows for the aggregation of the four zoom 18 tiles within the zoom 17 footprint to create a (512, 512, 3) training chip, instead of the typical (256, 265, 3) training image chip.
 Inference Validation
Inference Validation
 Inference Validation
Inference Validation
 Inference Validation
Inference Validation
Collecting feedback about predictions and retraining
Another exciting feature we added to ML Enabler is the ability to collect feedback about predictions from within the interface. Users can tag a tile as valid or invalid. Predictions tagged as valid switch to green, predictions tagged as invalid switch to white, and predictions that haven’t been manually validated stay red.
 Inference Validation
Inference Validation
ML Enabler can then convert these validated predictions back into labeled training data matched up with imagery to allow users to easily re-train a new model with the validated model predictions.
Future
We think that it can make the integration between mapping tools and model infrastructure easy and less intimidating. There are an increasing number of internal and partner projects that rely on ML Enabler and we will continue developing and maintaining.
Some of our immediate plans include ability to run inference over imagery sources other TMS, automate re-training workflows, and the ability to add more detailed model metadata to the registry. We hope you get the chance to experiment ML Enabler for yourself. Please reach out with any questions or comments on Github or Twitter!
What we're doing.
Latest