


In Part 3 of this blog series (Part 1, Part 2), we’ll cover which tools we use to configure and keep tabs on our ML experiments, develop our models, export and serve them in applications, and some miscellaneous utilities for increasing the adoption of our models. This post picks up where our Part 2, Data Operations post, left off.
To recap, we‘ve found the following tools to be most helpful for developing, deploying, and sharing ML models in production:
- Hydra for configuring ML models and running experiments.
- TIMM for sourcing a variety of pre-trained models.
- Pytorch Lightning for training ML models for classification, object detection, and segmentation.
- CML for a low-cost CI/CD system for running ML experiments and reporting results.
- TorchServe for deploying models to REST endpoints within more extensive applications.
Once we have a data pipeline that transforms satellite imagery into a form that is ready for use by an ML framework, we do the following:
- Set up a configuration and tracking system
- Move on to exploratory model training and track experiments
- Store and distribute important experiment model artifacts

Fig 1. Our updated ML Tooling diagram, zoomed in on the Model section.
1. Model Configuration and Experiment Tracking
We track our experiments to record what we have learned, inform future experiments, communicate results, and organize versioned model artifacts for later re-use.
To track experiments efficiently, we use a standard configuration format defined by Hydra to access and manage configurations. Hydra is a python library for creating hierarchical configurations out of YAML files and is helpful for complex applications with many knobs to adjust - typically dozens of ML model hyperparameters. To track these configurations and the outputs of the resulting experiments, we use Weights and Biases (W&B), which integrates well with PyTorch-Lightning for logging and visualizing experiment metrics in an informative UI.
Combined with PyTorch-Lightning’s built-in functionality for logging results to W&B, Hydra provides a simple experiment config and logging setup.
├── config
│ ├── __init__.py
│ ├── callbacks
│ │ └── minimal.yaml
│ ├── config.yaml
│ ├── datamodule
│ │ └── sen12flood.yaml
│ ├── model
│ │ └── sen12flood-resnet18.yaml
│ └── trainer
│ └── basic.yamlWith the hydra decorator, we modify our model training function to load the config directory above as a nested dictionary of configs, keeping our modeling code neat and free of hardcoded hyperparameters and arguments we'd like to tweak.
@hydra.main(config_path="config", config_name="config")
def train(cfg: DictConfig):
# loggers
csv_logger = CSVLogger(save_dir="logs", name=cfg.name)
# Pytorch Lightning handles logging to W&B
wandb_logger = wandb_logger = WandbLogger(
project="ml-pipeline",
entity="client-name",
save_dir="logs",
name=cfg.name,
log_model=False,
)
# .... pytorch lightning training logic goes here2. Model Training
We’ve settled on using PyTorch-Lightning as our framework of choice. It has solid documentation, built-in support for quick prototyping of classification, object detection, and segmentation models, is extensible for more complex models, and has the best support we’ve found for parallelization across multiple GPUs. Additionally it has integrations with Hydra for simple model configuration, and W&B for simple model logging.
TIMM is a library with many state-of-the-art and foundational pre-trained models for different detection tasks and good integrations with PyTorch. Albumentations is a library for data augmentations, and we can fine-tune existing models with TIMM for more specific modeling challenges. In the future, we’d like to explore augmentations on the GPU for faster model training, possibly with cuCIM (the GPU version of scikit-image) or kornia.
Because it is so flexible, we've found that PyTorch-Lightning can integrate well with TorchData, the next-generation library for data pipelines that will replace Pytorch’s Dataloader. We’ve seen a lot of advantages to TorchData, as noted earlier in Part II: Data Operations, in the Data Pipelines section. For these reasons, we’ve deprioritized learning TorchGeo’s inheritance-style code patterns for training since they are incompatible with TorchData. We hope that TorchGeo, zen3geo, and TorchData become better integrated.
A note on Hyperparameter Tuning: We typically manually handle hyperparameter tuning (HP tuning) to run the minimal experiments necessary to develop a viable model. While we’ve experimented with automatic hyperparameter tuning tools like RayTune, we believe auto-HP tuning is only useful when you need to gain a few extra percentage points of model accuracy and don’t care about compute costs. Most of our partners want to run the minimal set of ML experiments needed to develop a model and are curious to learn from and advise on the choice of experiments.
3. Storing and Distributing Models
Model Versioning and Artifact Storage
Weights and Biases helps us version and store models, keeping model artifacts close to logs and metrics. We’ve also used CML (an iterative.ai tool, like DVC) and GitHub Actions to kick off experiments with Pull Requests and post model experiment results directly to Pull Requests as Comments. Overall we like CML as a no-cost option for automating workflows like logging confusion matrices, generating TensorBoard logs, and kicking off training scripts with pull requests. However, we prefer Weights and Biases to be able to compare experiments with each other in a single dashboard more easily. Deciding between CML + GitHub Actions vs. using the W&B dashboard is primarily a matter of preference and cost.
Model Export
Because we use PyTorch-based frameworks, we use the TorchScript model format when we need a portable, CPU optimized model that encapsulates all the model weights and logic. TorchScript works well with TorchServe.
Serving Models
We use TorchServe’s .mar archive format and TorchServe docker images to create REST services from our models. The .mar archive is a straightforward format that packages a model file with a handler.py, which handles input preprocessing (resizing, test time augmentation) and model prediction post-processing (non-max suppression to reduce spurious bounding box detections).
For efficiently scaling models to large geographic regions, we use ml-enabler, an open-source tool we developed that uses AWS Batch to simplify the process of running inference on extensive archives of image tiles.
We’ve also developed PEARL, a human-in-the-loop (HITL) application that allows you to annotate, (re)train an ML model, run model inference on geospatial imagery, and tweak model inferences to generate more training data. In the future, we’d like to unify three tools we’ve developed: DS-Annotate for advanced annotation functionality, ml-enabler for scaling ML models, and PEARL for the HITL interface. We're working on integrating Facebook AI Research's Segment Anything to make it easy to annotate complex segments on satellite imagery.
Model Utilities
The following are some final recommended tools that help us distribute the results from ML projects.
To handle the myriad of dependencies and configurations in an ML project, we prefer defining multiple environments in a single pyproject.toml file. We often find that we need to create separate virtual environments within a project:
- A core environment containing dependencies for our data pipeline, model training, and evaluation.
- An inference environment if we need a slimmer set of dependencies or particular model optimizations.
- An interactive data exploration environment that registers an ipython kernel for jupyter notebook.
- A docs environment to build a webpage documenting the project, usually with Jupyter Book.
One such packaging tool we use is Hatch - which allows us to define a base environment from which all other envs inherit dependencies and keep track of all environments in one pyproject.toml file rather than multiple requirements.txt and setup.py files. Hatch also has a CLI for managing environments and pushing python packages to PyPI.
For documentation, we prefer Jupyter Book since it presents both Jupyter notebooks and python module documentation in an interactive and navigable website. Since we often create interactive tutorials for our project partners, Jupyter Book helps us serve these notebooks with Google Colab or Binder Hub so that organizations we work with can step into the code with minimal setup.
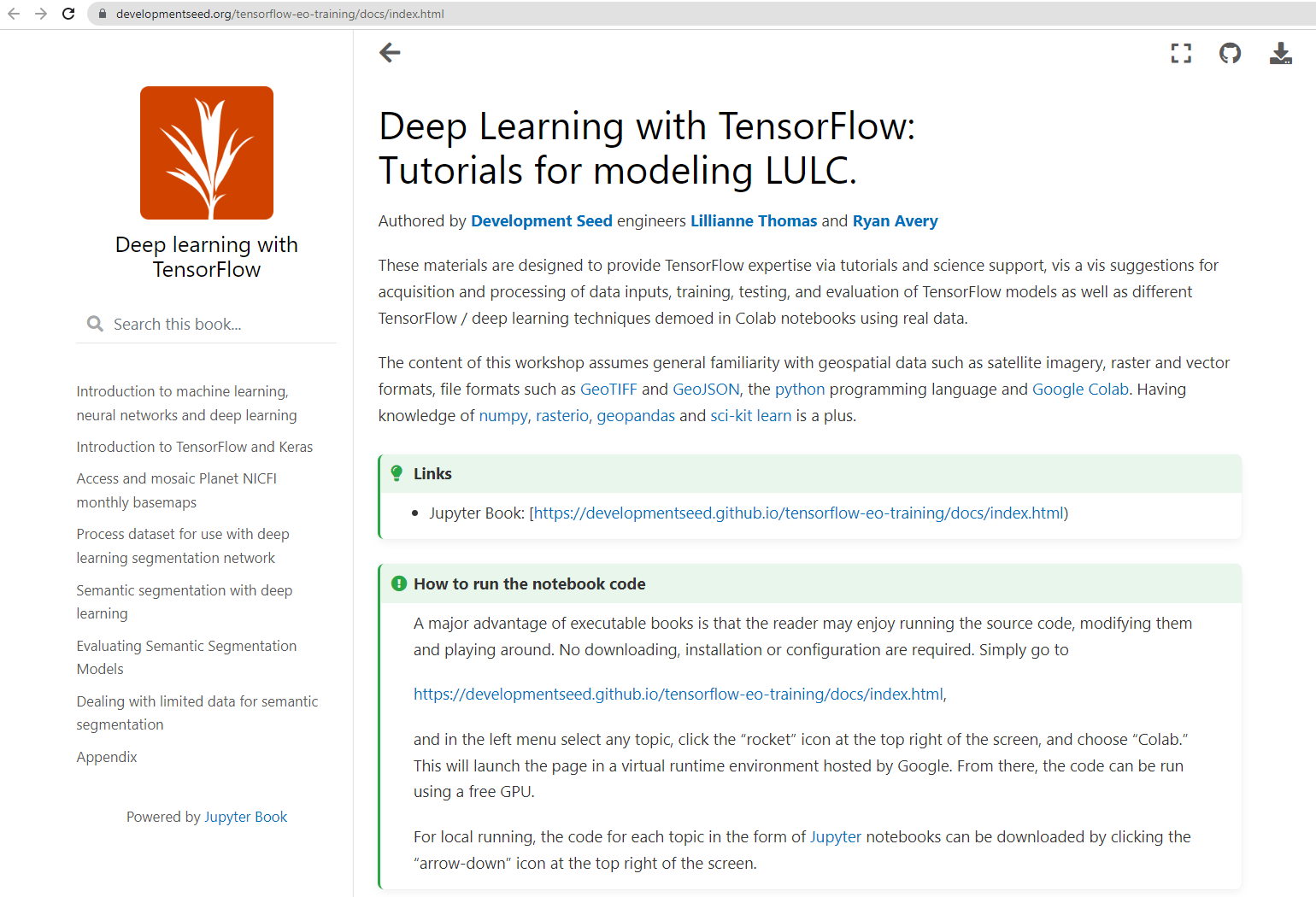
Fig 2. Check out this Tensorflow tutorial, served from GitHub pages and built with Jupyter Book.
Conclusion
If all those tooling recommendations made you feel dizzy, you’re not alone. My head’s spinning a bit just thinking about the universe of options for data management, model training, model tracking, and publishing code and model results. So let’s zoom out a bit.
For production ML systems, we think it’s essential to find tools that empower you to accomplish the following:
1Run unique and informative experiments
2Reproduce those same experiments, including producing evaluation metrics and model artifacts
3Store model artifacts and record their versions for internal use and comparison
4Serve models in performant applications that offer easy deployment and flexibility for models with various compute resource requirements and detection types
For non-production ML, you certainly don’t need all these tools. Pick the tools that solve your problem and minimize your most significant pain points!
We hope these recommendations for open-source software across the full GeoML stack have been helpful! Stay tuned for an upcoming post showcasing a working example of this ML stack on satellite imagery. If you’d like to dig into any of these examples with us a bit more or have questions about your own GeoML problem, feel free to contact me at ryan(at)developmentseed(dot)com.
What we're doing.
Latest