


Doing GeoML correctly and efficiently is hard. Our images are large and complex, metadata is inconsistent, and data come in a variety of geospatial or ML formats. It’s hard to keep track of all the different data and analytics tools for ML for EO. Even if you could, you’d probably be left wanting for your custom ML problem.
To carry out a GeoML project, it helps to build on the shoulders of giants and adopt widely used standards and libraries that leave room for adaptation. However, there are many options for standards and libraries for working with geospatial data and ML methods. So our team is releasing Version 1 of our preferred ML Stack to determine the best tools for our geospatial domain that are reusable and interoperable.
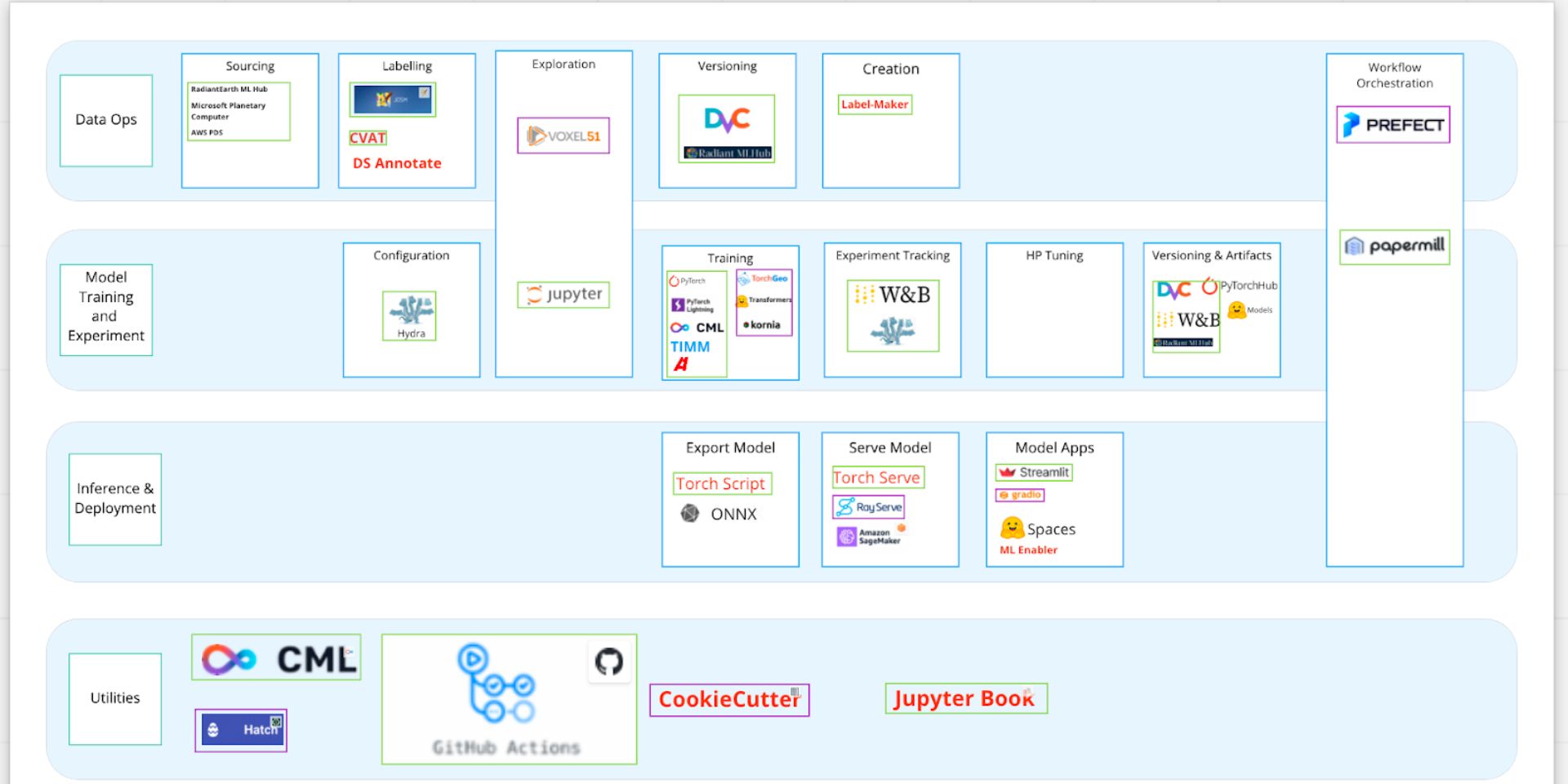
After voting and discussing these, we arrived at Version 1 of our preferred ML Tooling Stack. Green boxes outline tools we have had success with using on projects and want to keep using. Purple boxes outline new tools we intend to use and evaluate going forward. We also list other tools we’d like to keep tabs on, but not prioritize.
Our guiding principles for determining what our stack should be included:
- Adaptable. Our data annotation, modeling, evaluation, and deployment solutions should work for geospatial satellite imagery, street view imagery; or for image classification or image segmentation problems.
- Strong Community. We should expect our tools to be widely used, well documented, well supported, and growing in popularity so that we can use these tools for years to come.
- Open Source. We have a bias toward open source to avoid platform lock-in since we work with clients that prefer different cloud providers or their on-prem servers, different ML frameworks, and different datasets.
So why is this stack particularly suited for GeoML? To summarize, we think that a few recently developed standards and tools show high potential for a cohesive GeoML stack.
- Datasets and metadata as organized and searchable STAC catalogs
- Fetching STAC Catalogs with stackstac
- Xarray for the readily parallel data model: subsetting, processing, statistics, visualization
- PyTorch, Pytorch Lightning, TorchGeo as the set of hierarchical ML frameworks that interface with the geospatial python ecosystem
More and more datasets are being published as STAC catalogs. This enables libraries like stackstac to acquire spatiotemporal imagery without needing to download the data ahead of time. Fetching datasets directly from STAC catalogs = a more cloud native workflow which is easier to reproduce and scale. To harness this geospatial data after it has been accessed with stackstac and represented as an xarray.DataArray, libraries like TorchGeo provide the capability to sample a dataset of rasters by geography or time. There are encouraging developments and discussions in the TorchGeo project to interface with the STAC spec and Xarray. Implementing these features will make it easier to query and load spatiotemporal catalogs for ML efficiently. Besides improving data acquisition and the model training pipeline, we have also identified hydra as an excellent experiment configuration management system that makes it easier to run and track experiments. We’ve also had success with deploying portable PyTorch models to production with AWS Sagemaker and Torchserve. There’s a lot to unpack here and we can’t wait to share all the outcomes of our discussions with you and get your feedback!
In part two of this blog series, we’ll go in-depth about each of these areas and share why we like these tools and how we plan to use them. In the meantime, we’d love to hear your experiences and what your ideal GeoML tool stack might look like.
What we're doing.
Latest