

Today we are releasing sat-api-pg, a flexible way to serve metadata for massive satellite imagery archives. sat-api-pg improves on a three year effort to build light and performant tools for applications and AI processes to manage data across huge and diverse planetary imagery holdings.
What is STAC? Why should I care?
Every day hundreds of satellites capture the globe collecting petabytes of data about our planet. This data contains tremendously valuable insights for understanding our world and for addressing critical global challenges like climate change, sustainable agricultural production and natural disaster response. These insights often go unused because they aren’t accessible to planners and doers in these sectors.
Development Seed builds tools for extracting insights from satellite imagery at scale — from helping the World Bank understand the structure of national electrical grids to advancing the UN’s Sustainable Development Goals by mapping vulnerable housing to helping NASA predict hurricane intensity with AI. To accomplish this in a sustainable, scaleable way, we rely on automated ways to scan across multiple imagery archives.
SpatioTemporal Asset Catalog (STAC) is a lightweight approach to managing metadata that provides consistent programatic access across imagery archives from different providers. Recognizing a need for a common approach to metadata archives, a forward thinking group of developers gathered under the guidance of Chris Holmes to advance a community-led approach to collaborate on a STAC Specification.
STAC at Development Seed. How did we get here?
Our team works across data, tech and utilization to expand the Earth observation capabilities available to developers, scientists and decision-makers. We partner with national agencies and satellite data providers to streamline the creation and delivery of their satellite products to ensure users receive data optimized for their needs as rapidly as possible. Simultaneously, we work with organizations who obtain insights from Earth observation data to help achieve their goals. Throughout our work, we follow a guiding principle to distill the technical lessons we have learned during these projects into open source libraries that the wider development community can then utilize as building blocks in their own work. All of this work is undertaken with the overarching goal of making Earth observation data more accessible to users without the need for highly specialized knowledge.
Many Development Seed projects share a common requirement: interacting with massive archives of Earth observation data. We have built several iterations of platforms to expose these archives as queryable APIs that developers can leverage to create powerful analysis applications. This pattern of creating and rebuilding Earth observation data APIs also exists in many government and commercial organizations where evolving ideas and technology have resulted in an large number of disparate solutions making new consumer application development difficult.
Creating a comprehensive conceptual model to represent and understand huge archives of Earth observation data is a challenging task. Thankfully, the STAC community is an expanding group of knowledgeable people who have volunteered their time and experience to tackle this challenge with an iterative, implementation driven approach.
Because of our involvement with a variety of Earth observation projects, and the hard experience we have gained while working on them, it was an obvious choice for us to get involved with the STAC community. Because STAC is an implementation-driven specification we set out adapting previous work on the sat-api to make it compliant with the emerging STAC specification. The results of this work were the first open source reference implementation of the STAC API specification.
What is sat-api-pg? Why should I care?
Sat-api-pg is a new implementation of the STAC API specification that doubles down on the things that make STAC great — flexibility and ability to be quickly and easily understood by developers. The sat-api has served us well on a variety of Development Seed projects. However, several considerations have led us to iterate and build an updated version, one which leverages Postgres as its main data store.
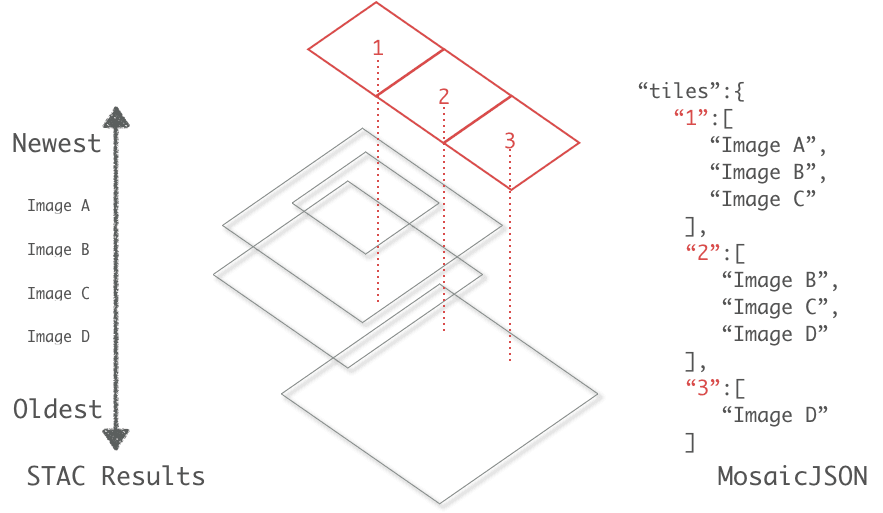
- More advanced spatial operations. STAC items are spatial in nature, and although the core STAC API specification supports spatial query options, many projects often require the more advanced spatial aggregations which PostGIS can provide. The most obvious example of this is our use of the mosaicJSON specification to generate mosaic tiles for a large number of images. The first step in this process is querying a large archive of images with a STAC API query to find candidate images which meet a certain criteria. We then transform the GeoJSON results of the STAC API query into mosaicJSON which can then be used directly by the tiler. This approach works well for smaller result sets but data transfer latency can be problematic when dealing with large geographic areas that contain a huge number of results. The default of our mosaic tiler is to use the first available pixel from the candidate images when rendering a tile. In this situation we can drastically reduce the size of the mosaicJSON file by using PostGIS operations to aggregate by tile index and iteratively add images until the tile is covered. We plan to include a mosaicJSON API endpoint which can utilize standard STAC query and filter logic which will allow our ML pipelines to request large volumes of imagery with certain characteristics distilled into a single tiling endpoint.
-
Simplifying document ingestion. When sat-api was initially developed the STAC specification focus was building easily indexable static document catalogs rather than queryable APIs. To build an API we needed an efficient way to ingest these catalogs into a data store to provide search operations (ElasticSearch in the case of sat-api), which we accomplished by crawling the large hierarchical tree structure represented by the STAC catalog, collection and item links. But when dealing with extremely large volumes of data (such as the Earth on AWS buckets) it quickly became apparent that using documents on S3 as a single source of truth introduced difficulties with optimistic locking and concurrency. With sat-api-pg we have simplified document ingestion to focus on using Postgres as the initial data store, which allows us to then periodically synchronize static catalogs atomically when required.
-
Institutional Postgres knowledge. ElasticSearch is a powerful search provider and other STAC API implementations like stacatto also leverage it because if its performance and scalability when indexing millions of documents. Development Seed is a small, lean team, and we often engage in shorter duration projects where we must deploy infrastructure that will be straightforward for our partners to maintain themselves in the future. In many cases, Postgres provides this simple deployment and maintenance while still providing a strong potential for scalability but we still have significant work ahead on query optimization to reach the turnkey scalability provided by ElasticSearch.
Design Approach
Development Seed has built a lot of APIs (both spatial and non-spatial). Across teams we’ve experimented with a lot of approaches to create simple, maintainable, performant REST APIs that easily model our projects’ business domains. One solution that has worked well for us on several projects is PostgREST. It allows us to build clean representations of a business domain as a database schema in Postgres and then seamlessly expose that schema as a fully featured REST API which clients can leverage with standardized, well structured HTTP requests. At its core the STAC API specification is a REST API specification and we choose PostgREST to take advantage of all the native features it supports when building out an API.
-
Results filtering with a url based query structure.
-
Pagination using HTTP headers.
-
HTTP insertion with JWT based authentication.
-
A great development community which provides excellent support.
PostgREST is ideal when building new APIs from the ground up but in the case of STAC we are dealing with a well defined specification. Given the evolving nature of the STAC specification, we want to have some flexibility in how we define our underlying data and query models, rather than be tightly coupled to STAC definition. This requires a translation layer between our client HTTP request and PostgREST, which can translate the STAC endpoint, query and filter logic into a syntax which PostgREST can use against the database. Nginx provides a great approach for proxying HTTP traffic to the internal service in a structured way. Luckily other developers have previously encountered this situation and built the postgrest-starter-kit, which provides a set of tools and a template project and demonstrates how to use a lightweight, scriptable nginx layer to control traffic to the PostgREST API.
In our case we need to accomplish things like:
-
Wrapping results which return a set of features as an ItemCollection.
-
Mapping STAC API specification urls to internal PostgREST urls.
-
Setting response headers depending upon the result type. For instance, differentiating between content-type application/geo+json and application/json.
The postgrest-starter-kit also provides useful tooling for integration tests. This provides a a great framework to build out a suite of API behavior tests which we can use to validate our API over time as the STAC specification evolves.
At the database level, Postgres and PostGIS provide an efficient way to model STAC metadata which supports structure, indexing and validation all in a compact description. Using a database rather than a document indexing solution like ElasticSearch also helps solve the long standing issue of normalization. Due to its lineage as a static document model, STAC allows implementors to move common fields from individual items up to the collection level. This normalization can be difficult to accomplish in document indexing stores but can be achieved in Postgres with a simple view.
Next Steps
This release of sat-api-pg is a definitive beta one. Though it provides support for much of the STAC specification there is still a significant amount of work to be done, including:
-
Query performance profiling. I have limited knowledge of Postgres query profiling and a majority of this project was developed rapidly to support some working prototypes. There is a lot of refactoring to be done to improve query execution plans when dealing with large datasets.
-
Index recommendations. Given STAC’s flexible extension based schema I have intentionally avoided including predefined indexes. But since many consumers will be creating similar queries it makes sense to provide some guidance on indexing best practices.
-
jsonSchema validation. The STAC extensions have well defined jsonSchema documents that allow us to use triggers to validate property sets when an item is inserted. There is an existing Postgres extension to accomplish this which just needs to be incorporated and tested.
Community
The STAC specification is a community driven effort which relies completely on the work and dedication of the developers who continue to push its evolution. Development Seed as an organization strongly believes that organic, community driven efforts are the best way to build powerful technology which can bring satellite data insights to the people who need them. We look forward to working with developers and earthdata users to continue to improve the ecosystem for massive earthdata analysis.
What we're doing.
Latest