

When people talk about “the cloud”, Amazon Web Services (AWS) is often a big part of what they mean. AWS allows you to run complex web applications on a vast array of cloud computers around the world. Most web developers are familiar with AWS’s S3 buckets for file storage and EC2 instances for running applications. However, there is more beyond S3 and EC2 — higher level services that can greatly simplify cloud services, at a cheaper cost, and requiring little maintenance.
We recently worked with the Missing Maps OpenStreetMap Project to create real-time user pages, badges, and leaderboards for all Missing Maps contributions to OSM. We built software to track all OSM contributions and an infrastructure on AWS to process and aggregate this data in real time. Most of the contributions for the Missing Maps project occur during mapathons where hundreds of volunteers submit edits and additions over a couple of hours. This means that the system needs to handle large spikes of activity when thousands of edits are added. Outside of mapathons there is far less activity. Because of these spikes and lulls, we wanted an alternative to constantly running multiple EC2 instances. Lambda functions proved to be the optimal solution to solve this problem.
Here we will show you the benefits of using Lambda and how to implement and deploy Lambda functions on AWS.
Aren’t lambda functions a [insert most any language here] thing?
The term originates from the lambda calculus, a logic system developed in 1936 by Alonzo Church, a mathematician and Alan Turing’s Doctoral advisor. Developers will likely be familiar with the term lambda function since it has become a feature of most major programming languages. A lambda function is an anonymous function (that is, it has no name), that takes in a single variable input. They are used when a function is made for a one-time or limited use and are able to be described with a more concise syntax than a regular function.
 Alonzo Church, explaining the Entscheidungsproblem
Alonzo Church, explaining the Entscheidungsproblem
AWS Lambda functions
An AWS Lambda function is a collection of code with a single entry point, or handler, and can be written in either Node.js (0.10.26), Python (2.7), or Java (8). While AWS Lambda functions do take a single input, they are of course not anonymous functions or else there would be no way to invoke them from the outside world. A Lambda function, generally, can be thought of as a simple function taking a single input and performing some transformation. Yet they are not restricted to simple operations. They can be quite complex, since libraries can be uploaded to the function. The Lambda function works by being configured to fire in response to some event, such as data added to a Kinesis stream, or files uploaded to an S3 bucket. Behind the scenes, Amazon stores the Lambda function code and configuration on S3 and when an event fires, it creates (or possibly reuses) a container, and passes the event data to the function handler.
With this architecture AWS handles the management of the function and gives users three main advantages:
Serverless (simple)
Lambda functions don’t require the maintenance of a server. The resources a lambda function uses is set only by specifying it’s memory usage, from 128 MB to 1536 MB. CPU speed is scaled as memory goes up and the memory allocation can be changed at any time.
Auto-scaling (smart)
There is no scaling to enable or to configure. Lambda functions spawn as necessary to keep up with the pace of events, although bandwidth may be restricted depending on other services accessed (e.g., bandwidth to a Kinesis stream is based on number of shards in the stream).
Cost-effective (cheap)
Compared to an EC2 instance which is up 24/7 and incurring costs, you are only charged based on how much the function runs, with no costs when it is not running. Furthermore, a function that has been allocated 512 GB of memory only costs 3 cents for every hour of computation. For a function that takes 1 second, those 3 cents can buy you over 3000 invocations of your function. Even for large scale operations, that are performing millions of functions a month, the cost will still typically be less than $20.
Deploying Lambda functions with Python and boto3
The AWS console is a great way to get started on Lambda functions. It steps you through the process of creating one and includes templates for different languages. However the AWS console lacks an automated way to add new functions and update existing ones. The AWS CLI (command line interface) can be automated, however when the Lambda functions are complex (for instance, when they require event source mappings and IAM roles and policies) doing these actions in Python scripts using boto3 is easier.
Using a simple example, I’ll demonstrate how to use boto3 to create a function with an associated role and policies, and how to update that code via Python scripts. We’ll start with a simplified version of one of the AWS Lambda example templates in the file lambda.py.
`import base64
import json
def lambda_handler(event, context):
print("Received event: " + json.dumps(event))
for record in event['Records']:
# Kinesis data is base64 encoded so decode here
payload = base64.b64decode(record['kinesis']['data'])
print("Decoded payload: " + payload)
return 'Successfully processed {} records.'.format(len(event['Records']))`Next, create a zip file containing the code including any additional dependencies needed in the same directory (boto3 is already included).
`$ zip lambda.zip lambda.py`We’ll then use a python script to create a Kinesis stream, an IAM access role, create a Lambda function with the zip file, then finally map the stream to the Lambda function.
`#!/usr/bin/env python
import time
import json
import boto3
kinesis = boto3.client('kinesis')
iam = boto3.client('iam')
l = boto3.client('lambda')
def create_stream(name):
""" Create kinesis stream, and wait until it is active """
if name not in [f for f in kinesis.list_streams()['StreamNames']]:
print 'Creating Kinesis stream %s' % (name)
kinesis.create_stream(StreamName=name, ShardCount=1)
else:
print 'Kinesis stream %s exists' % (name)
while kinesis.describe_stream(StreamName=name)['StreamDescription']['StreamStatus'] == 'CREATING':
time.sleep(2)
return kinesis.describe_stream(StreamName=name)['StreamDescription']
def create_role(name, policies=None):
""" Create a role with an optional inline policy """
policydoc = {
"Version": "2012-10-17",
"Statement": [
{"Effect": "Allow", "Principal": {"Service": ["lambda.amazonaws.com"]}, "Action": ["sts:AssumeRole"]},
]
}
roles = [r['RoleName'] for r in iam.list_roles()['Roles']]
if name in roles:
print 'IAM role %s exists' % (name)
role = iam.get_role(RoleName=name)['Role']
else:
print 'Creating IAM role %s' % (name)
role = iam.create_role(RoleName=name, AssumeRolePolicyDocument=json.dumps(policydoc))['Role']
# attach managed policy
if policies is not None:
for p in policies:
iam.attach_role_policy(RoleName=role['RoleName'], PolicyArn=p)
return role
def create_function(name, zfile, lsize=512, timeout=10, update=False):
""" Create, or update if exists, lambda function """
role = create_role(name + '_lambda', policies=['arn:aws:iam::aws:policy/service-role/AWSLambdaKinesisExecutionRole'])
with open(zfile, 'rb') as zipfile:
if name in [f['FunctionName'] for f in l.list_functions()['Functions']]:
if update:
print 'Updating %s lambda function code' % (name)
return l.update_function_code(FunctionName=name, ZipFile=zipfile.read())
else:
print 'Lambda function %s exists' % (name)
for f in funcs:
if f['FunctionName'] == name:
lfunc = f
else:
print 'Creating %s lambda function' % (name)
lfunc = l.create_function(
FunctionName=name,
Runtime='python2.7',
Role=role['Arn'],
Handler='lambda.lambda_handler',
Description='Example lambda function to ingest a Kinesis stream',
Timeout=timeout,
MemorySize=lsize,
Publish=True,
Code={'ZipFile': zipfile.read()},
)
lfunc['Role'] = role
return lfunc
def create_mapping(name, stream):
""" add a mapping to a stream """
sources = l.list_event_source_mappings(FunctionName=name,
EventSourceArn=stream['StreamARN'])['EventSourceMappings']
if stream['StreamARN'] not in [s['EventSourceArn'] for s in sources]:
source = l.create_event_source_mapping(FunctionName=name, EventSourceArn=stream['StreamARN'],
StartingPosition='TRIM_HORIZON')
else:
for s in sources:
source = s
return source
name = 'alonzo'
# create kinesis stream
stream = create_stream(name)
# Create a lambda function
lfunc = create_function(name, 'lambda.zip', update=True)
# add mapping to kinesis stream
create_mapping(name, stream)`If it runs without error, you should have an IAM role named alonzo_lambda, and a Kinesis stream and lambda function named alonzo.
Now, to test it. Use the AWS CLI to add a JSON record to the stream.
`$ aws kinesis put-record --stream-name alonzo --data "{'0': 'the', '1': 'lambda', '2': 'calculus'}"`You should get back JSON indicating the ShardId. Take a look at the logs in CloudWatch to see if the function worked. Under Logs there should be an “/aws/lambda/alonzo” log group. Within that are different log streams. New log streams will be created periodically, but a single log stream may hold the logs from more than a single invocation of the function. You should see the output of the event and the decoded JSON we went into the stream.
 Memory usage and duration to help plan memory allocation and expected costs
Memory usage and duration to help plan memory allocation and expected costs
caveat emptor: While Lambda functions cost nothing when not running, it is typically used in a system where there are other resources which do cost something. Kinesis streams are charged per hour per shard. This example only creates a single shard so your alonzo stream will cost you $0.36 a day. When your done playing, make sure you delete the resource through the AWS management console.
Security Considerations
In order for Lambda functions to access other AWS services, such as S3, a Kinesis stream, or a Virtual Private Cloud (VPC), they must be granted access through policies using the Identify Access Management (IAM) service. A role should be created specifically for your Lambda function, and then policies added to that role to grant access to the services mentioned above.
If your lambda function requires access to an EC2, RDS or other resource inside a VPC and those have restricted access, more work is required to access them with the Lambda function. Just granting a policy to allow VPC configuration is not enough (although that too is required). The Lambda function must be assigned at least one security group (as shown below), and then you must add an Inbound Rule to the EC2 or RDS security group to allow access to the Lambda function security group. To keep organized, it is recommended to create a security group specifically for each service (e.g., Lambda, EC2 instance) and give it the same name as your service name (e.g., alonzo_lambda).
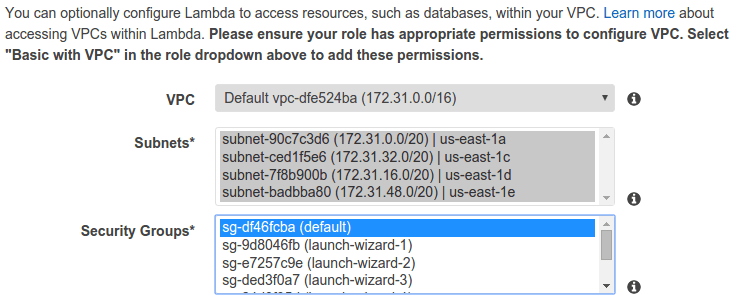 Assign a VPC, subnets, and at least one security group to the lambda function
Assign a VPC, subnets, and at least one security group to the lambda function
A drawback when doing this is once ‘placed’ within your VPC, the function will be unable to access any other resource outside of your VPC (as if it is within the internal network). To gain access to the outside a NAT gateway must be set up to route responses back to the Lambda function.
Conclusion
The example above uses a pull model where it pulls data from a Kinesis stream. Other services, such as S3, can invoke the Lambda function directly, which is the push model. See the Lambda documentation for a full list of event sources. An example of how the push model works is when monitoring additions to an S3 bucket. To do this an event is added to the bucket directly and the Lambda function is invoked when the criteria is met. In addition to this, you could have the Lambda function automatically update metadata in a database, process the new data, or even deploy newly uploaded code to additional Lambda functions. The possibilities are endless.
Breaking down problems into a series of functions that each operates on discrete variables is exactly what the lambda calculus was all about. Even if AWS Lambda functions aren’t lambda functions in the truest sense, no doubt Alonzo Church would find it in the spirit of the lambda calculus.
What we're doing.
Latest