
We launched developmentseed.org this week on GitHub pages and Jekyll. This may come as a surprise — unlike a CMS or a webapp Jekyll generates static HTML pages that can be served the old-fashioned way like it’s 1995. It turns out that Jekyll is a simple and subtly powerful way to make websites.
An introduction to GitHub pages and Jekyll
The players in this story are very simple.
GitHub pages is a set of conventions and tools that make it easy to get files from a GitHub repository onto the web. All you do is
-
Create a git repo with your user/org name like
developmentseed.github.com. -
Add some files to it like
index.htmland an image. -
Push your changes.
-
Your website is now live at developmentseed.github.com.
Jekyll is, according to its wiki,
… a simple, blog aware, static site generator. It takes a template directory (representing the raw form of a website), runs it through Textile or Markdown and Liquid converters, and spits out a complete, static website suitable for serving with Apache or your favorite web server.
Translation:
-
Jekyll is a converter, not a server. It runs any time you want to update your site but doesn’t need to be running for your website to be live.
-
You give it a source directory of random stuff and it will turn it into a site directory containing HTML and other static files.
GitHub pages will run jekyll whenever you git push, converting your markdown, templates, and posts into shiny HTML that's live on the web.
Jekyll’s rules
Jekyll follows four simple rules when converting your source into a website:
-
Any file in the source directory is copied directly into the site directory.
-
Unless the file that has a YAML header. These files can make use of the Liquid templating language.
-
Unless the file is in
_posts.These files build up a data object representing all of your site's content that can be referenced when templating. -
Posts can specify a
permalinkto generate a page at a different location than where the post resides in the source directory.
Once you get the hang of these four simple rules you can do some surprising things.
Can it prototype?
We began rebuilding our website by prototyping with HTML pages — we wanted to experiment with different ways of presenting our projects and ourselves without being limited by implementation or technology details.
Once we were ready to commit to our prototypes Jekyll made it easy to start turning a single project exhibit into a pattern for more. Rule #1 — Jekyll copies source files directly to your site — means that a static website is already a valid Jekyll site. It’s entirely up to you how much and where you want to use Jekyll’s post, metadata, and templating functionality. In our case, experimental prototype pages started as specific HTML pages and slowly became templates for a broader set of content as we became more confident in them.
Can it be more than a basic blog?
The YAML header used by Jekyll provides for amazing flexibility. There are a few predefined fields that can be used tactically but you are free to add your own fields at will. Using these YAML fields you can add custom fields and create relations between content in a simple, straightforward, manner.
Here is an example of what the post for my team profile looks like:
`---
layout: team
category: team
permalink: /team/young-hahn
title: Young Hahn
subtitle: UI Lead + Developer
image: /images/team/young.jpg
twitter: younghahn
github: yhahn
---
Young not only heads our design team ...`The custom field twitter is used as a variables in templates to link my twitter account and image is used to show my picture. The predefined fields categories and tags are especially important because they are used by Rule #3 - posts belong to a data object of your entire site - to structure content. From any template I can iterate over all posts in the category team with the variable site.categories.team.
By tagging a blog post like this one with Dave Cole
`---
layout: blog
category: blog
title: The Local Impact of Unemployment and Recovery
subtitle: See your county's local unemployment rate and recovery spending
author: Dave Cole
---
Tonight at 7:00pm President Obama will ...`we can use that tag to look up Dave’s profile in site.categories.team and then show his picture, name and byline on his blog post. Conversely, we can look up all blog posts by Dave by accessing site.tags['Dave Cole'] if we want to list them on his profile.
Can it help you manage content?
While Jekyll doesn’t require you to use git, it was meant to work hand in hand with it. By keeping your content under version control you can leverage all of git and GitHub’s tools for managing your content.
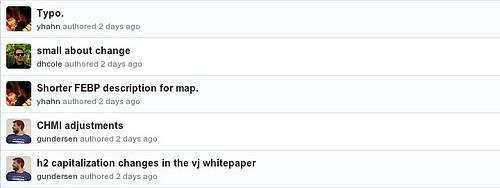
History of all changes
Git keeps track of all of your content changes. You’ll never lose your writing and everyone can see who changed what and why. As the final content editing for the launch of developmentseed.org was occurring, we had half a dozen people editing copy, sometimes on the same page, all at the same time.
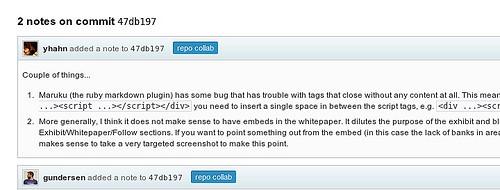
Issues and commit notes
The same tools that coders on GitHub use work wonderfully for managing content. Through the launch process we created GitHub issues, assigned them to team members, and closed them via commit messages. To get the details right commit notes are perfect for discussing specific changes inline.
Can it aggregate CSS and JavaScript?
Aggregated CSS and JavaScript is a good idea for any website in production. Doing this with Jekyll turned out to be a snap. We put our individual CSS and JavaScript in the _includes directory. Then leveraging Rule #2 - any file with a YAML header (even an empty one) can use Liquid templating - we made a file called all.css with the following:
---
---
{{ "{% include reset.css " }}%}
{{ "{% include grid-framework.css " }}%}
{{ "{% include miscellaneous-framework.css " }}%}
{{ "{% include my-styles.css " }}%}Jekyll combines the included CSS files into a single file. Ditto for JavaScript.
Can it search?
While there are some search plugins for Jekyll, GitHub pages doesn’t support custom Jekyll plugins as of yet. We found an alternative, elegant solution by implementing a smart client-side JS autocomplete rather than a traditional keyword search.
There is a light JSON index of our recent content at search.json that is a JSON file with an empty YAML header like this:
`---
---
[
{{ "{% for item in site.categories.about " }}%}
{{ "{% include post.json "}}%},
{{ "{% endfor "}}%}
{{ "{% for item in site.categories.projects " }}%}
{{ "{% include post.json "}}%},
{{ "{% endfor "}}%}
{{ "{% for item in site.categories.team " }}%}
{{ "{% include post.json "}}%},
{{ "{% endfor "}}%}
{{ "{% for item in site.categories.blog limit:200 " }}%}
{{ "{% include post.json "}}%},
{{ "{% endfor "}}%}
false
]`Once templated we have an abbreviated array of all of our posts, including title, category and date for showing our results. Note that we throw in a false at the end rather than trying to use large amounts of templating logic to prevent a trailing comma in JSON. We throw out the false in our client side autocomplete code.
Next up for Jekyll at Development Seed
We aren’t sure yet when Jekyll is the right tool for the job but we are sure of this: we’re excited about Jekyll and the concept of converters rather than servers (so is MailChimp, apparently). Jekyll has made our website:
-
Easy to work with. Everyone on our team knows HTML and Markdown and working with YAML is a breeze.
-
Extremely fast. It’s hard to beat the speed of serving static files.
-
Worry free. There are no entry points to hack and there is no live webapp to go down.
If you have any questions or are interested in using Jekyll for your next big project, feel free to ask us any questions you have about our build.
What we're doing.
Latest