

Development Seed partnered with Microsoft to create PEARL: Planetary Computer Land Cover Mapping , an AI Accelerated Land cover Mapping Platform on the Microsoft Planetary Computer.
The Microsoft Planetary Computer puts global-scale environmental monitoring capabilities in the hands of scientists, developers, and policy makers, enabling data-driven decision making. PEARL combines open data and open source software available on the Microsoft Planetary Computer along with Microsoft Azure to allow scientists and mappers to create land cover maps faster.
Faster, more accurate land cover mapping
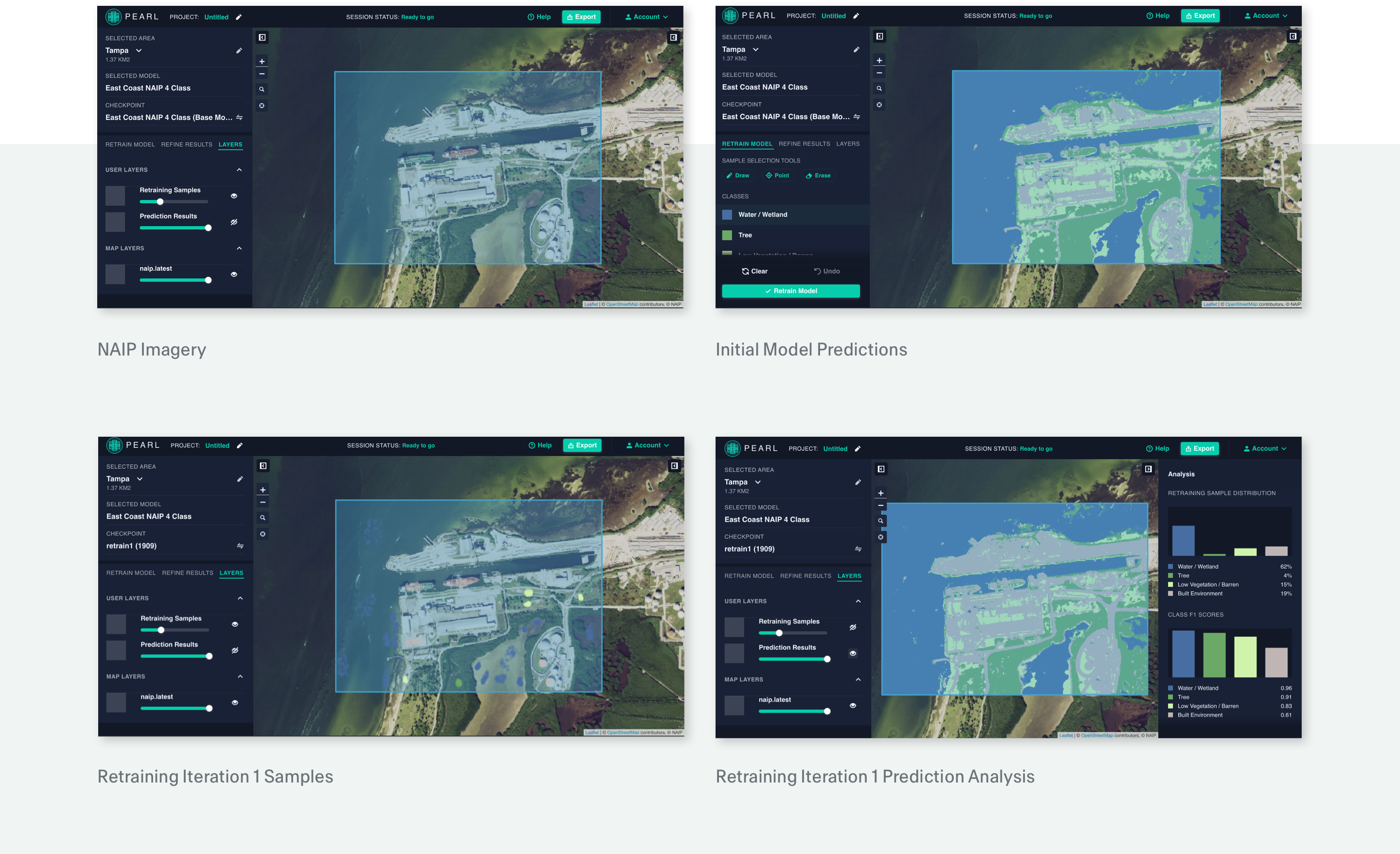
PEARL, the Planetary Computer Land Cover Mapping Platform, uses state of the art ML and AI technologies to drastically reduce the time required to produce an accurate land cover map. Scientists and mappers get access to pre-trained, high performing starter models, and high resolution imagery (e.g. NAIP) hosted on Microsoft Azure. The land cover mapping tool manages the infrastructure for running inference at scale, visualizes model predictions, shows the model’s per class performance, allows for adding new training classes, and allows users to retrain the model. The tool helps harness the power of expert human mappers and scientists through immediate model evaluation metrics, easy retraining cycles and instant user feedback within the UI.
PEARL allows users to quickly create accurate land cover maps by incorporating machine learning into a web-browser based mapping workflow. Here, mapping is an iterative process where users can 1.) run inference over new imagery with a deep learning model and 2.) refine the model’s output and add new classes with a retraining function. This is enabled by a system composed of: a web based front-end, a “Dynamic Map Tile Service”, and GPU workers on a Kubernetes cluster that communicate through REST APIs and websockets.
The front-end exposes users to a browsable map interface that displays imagery and model predictions in two layers. It also exposes a UI for running model inference, providing new training samples to the model, defining new classes to add to the model, retraining the model, and saving/loading model checkpoints. The “Dynamic Map Tile Service” uses Titiler to serve the basemap and data tiles (that, importantly, need not be constrained to RGB images) in a format that can be consumed by the front-end and GPU workers. The backend infrastructure provides persistent sessions to each user though a REST API and websocket connection. Each front-end session will directly connect to a GPU server on a Kubernetes cluster, where their associated model is loaded in memory. The Kubernetes cluster enables multiple users to perform large scale inference with a trained model.
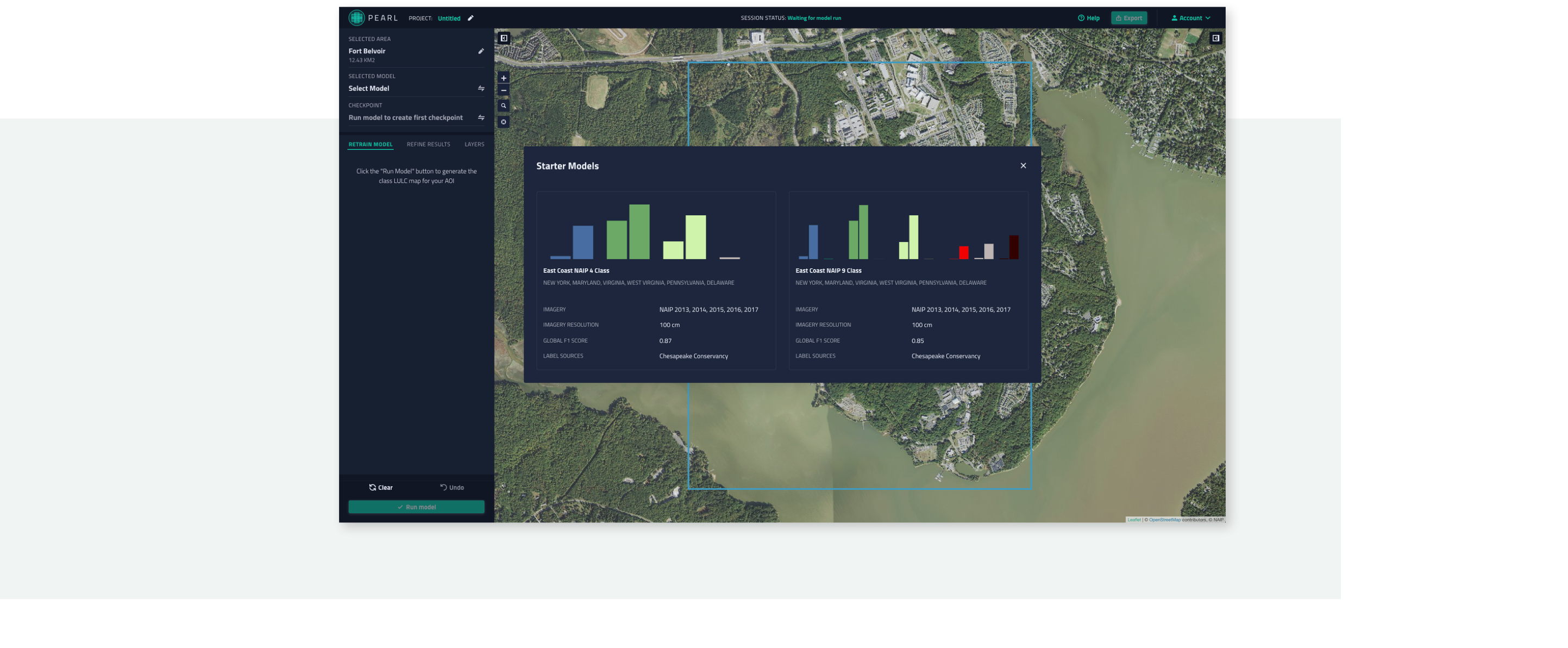
Currently, the tool contains two starter models trained with nine and four land-cover classes based on labeled data from the Chesapeake Conservancy’s dataset and imagery from the National Agricultural Imaging Program (NAIP). Both of these starter models have a global F1 score of approximately 80%. Retraining is done by updating the parameters of the last layer of the model using point labels provided by the users within a session. Through this functionality, users will be able to improve the performance of the model for a local area and even define new LULC classes. A cloud free mosaic of 4 band, red, green, blue, near infrared, NAIP imagery that covers the United States is currently available in the tool for users to run inference over.
The Future of PEARL
This tool has interesting future research and engineering directions. On the research side, the retraining methodology is open for innovation. Different retraining strategies will trade-off between speed of training, efficiency (how many points a user must label to get their desired outcome), and capacity (the best possible performance the model can achieve). For example, updating the parameters in the last layer of the model is very fast and efficient, however has a reduced capacity compared to updating all parameters of the model. More elaborate strategies such as spatial ensembles of local models could provide desirable results over all three properties. Future work will allow users to bring their own land cover models and training data to the platform and offer additional imagery sources e.g. Sentinel-2 that supports customizable LULC mapping outside of the United States.
Related content
More for you
Have a challenging project that could use our help?
Let's connect
We'd love to hear from you.