


Moscatel, an internal LLM project, revealed unexpected insights about the evolving AI landscape, the build-vs-buy dilemma, and where our expertise truly shines.

.jpg){kind=link}
Sometimes, the most valuable projects are the ones you decide to stop building. In the fast-evolving world of AI systems, knowing when to pivot can be just as important as knowing how to build.
Our journey with Moscatel, an internal LLM assistant, reinforced three key lessons: failure can be a form of success when it clarifies your direction, the decision to build versus buy is a constantly shifting equation, and the greatest impact comes from applying AI where your expertise is strongest. Here’s how we arrived at these insights — and why we chose to press pause on Moscatel.
Failure can be a form of success when it clarifies your direction
The Origin Story
On a summer evening in Lisbon, Development Seed's machine learning and AI team gathered at the kiosk near the Igreja da Graça to drink moscatel, a sweet Portuguese wine, while watching the sun set over the tile roofs of the city. As we joked around with various uses of the word, we concluded that it would be the perfect name for the project we had been working on earlier that day.

The team enjoying some local Lisbon food and culture.
Why Build Your Own LLM When So Many Already Exist?
The project involved building a tool to manage knowledge within DevSeed using a Large Language Model (LLM). This agent pulls contextual information from GitHub issues, project documentation, and other internal sources to answer a wide range of user questions. The potential use cases are only constrained by the data we can feed it and include generating reports on our work across projects, surfacing valuable information about past project work, tools, and technologies, generating financial reports on the fly, and much more.
We decided to build our own LLM system for three reasons:
Private data accessibility. While commercial LLMs offer impressive capabilities, they can't access our internal knowledge repositories without us explicitly sharing that data, which raises privacy concerns. Even though we work deeply in open source, we have sensitive information about team members and partners that must not be shared externally.
Infrastructure control and cost management. Running your own system means granular control over compute resources. This doesn't always translate to cheaper, but it does mean predictable — an important distinction when API costs can fluctuate dramatically. Additionally, running the models ourselves using Ollama allows us to easily swap the models in order to compare their ability to reason and generate content, and is valuable to understanding the compute and scaling requirements for these types of models.
System integration expertise. Sometimes, you need to build something to truly understand it. By developing Moscatel, we aimed to deepen our knowledge of LLM system integration to better serve partners who need similar solutions or are excited about building LLM components into their applications. This hands-on experience directly informs our work on projects like our collaboration with the Land and Carbon Lab and WRI for language interfaces for maps, where we're building natural language interfaces for geospatial data.
Building Moscatel
The initial iteration of the project is based on retrieval augmented generation (RAG) architecture. RAG is a technique where we create a database with all of the content we want to make accessible to the model. When a user submits a query, this query is first searched against this database to find the bits of text that are most relevant to the user's query, which is then passed to the LLM as context for it to form a more accurate and precise answer.
It's worth noting that the content in the database is first transformed from text that humans can understand into a numerical representation that LLMs can understand, called embeddings, and the database uses a technique called vector search to find the most relevant ones to the user's query. We used LanceDB as our vector database and LangGraph to define the agent's architecture and workflow. We used FastAPI as the API layer between the user interface and the agent, and we built a very quick prototype interface using Streamlit, a handy python library for quickly creating data-driven interfaces.
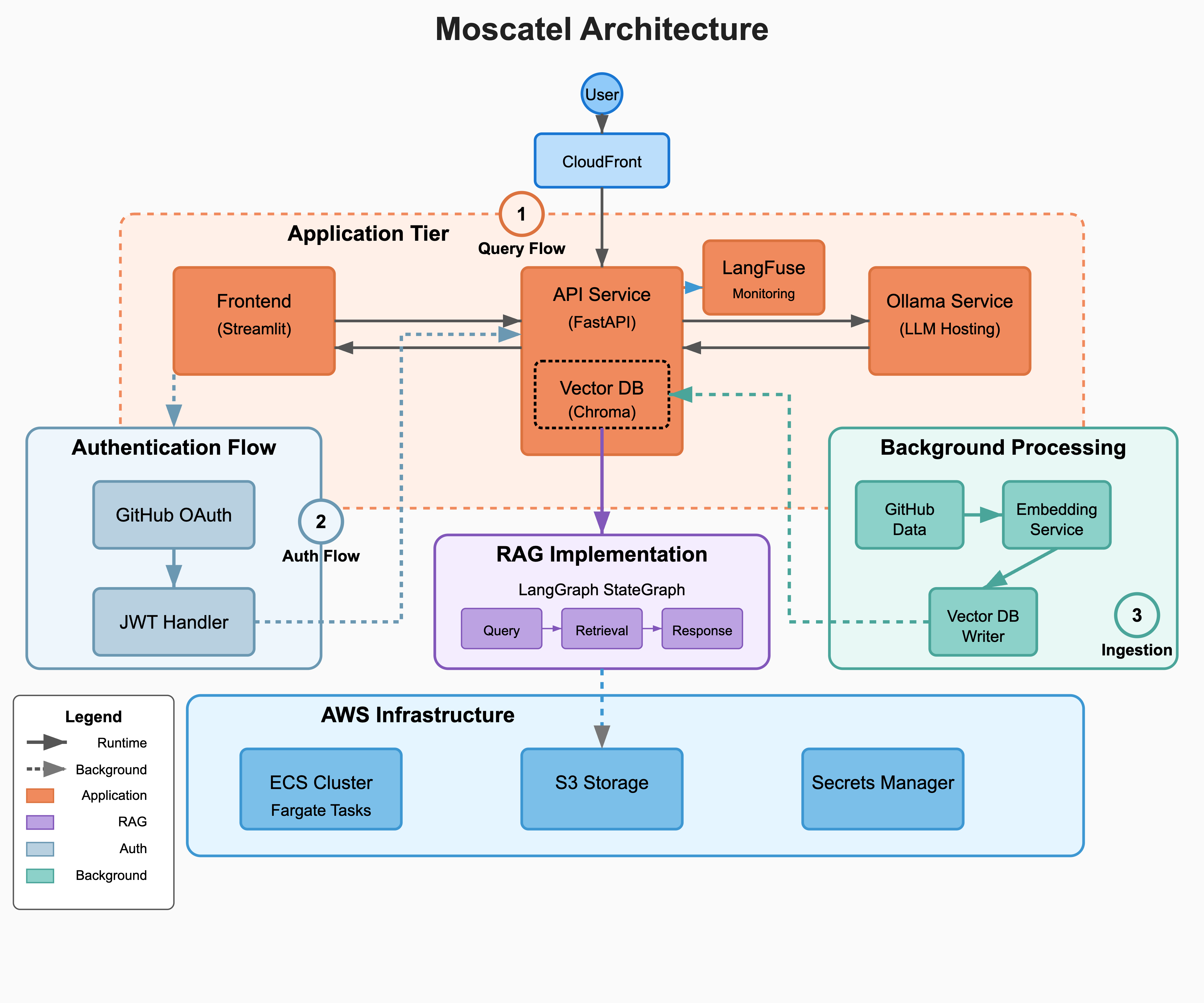
Moscatel system architecture overview. The architecture is organized into application, authentication, background processing, and infrastructure layers. It supports a retrieval-augmented generation (RAG) workflow using LangGraph, FastAPI, and Chroma, with GitHub-based authentication and LangFuse monitoring.
We deployed this RAG agent to an AWS cluster, where we are also running the LLM. Typically, projects like this are built against an LLM running on remote servers owned and managed by companies such as OpenAI, Anthropic, etc. This makes a lot of sense in most cases, as it gives access to much larger models that are much more expensive to run quickly and are typically much cheaper, as you only pay per request rather than having to pay for the compute instance costs when running it ourselves.
To ensure the information would be secure in the Moscatel interface, we added Github authentication so that only members of the Development Seed organization on Github could submit queries.
Limitations We Encountered
Moscatel was a promising prototype, but to become a fully functional internal tool, it needed much more — dynamic data integration, continuous updates, and broader instruction sets. Right now, it relies on static documents and a single prompt flow and runs slowly on limited compute resources.
These gaps highlight what many organizations are learning in 2025: While AI-powered knowledge tools hold great potential, they’re only as effective as their data sources, system integration, and performance. Trust and reliability are especially critical, as we’ve seen in our work on language interfaces for maps, where understanding where information comes from is as important as the answer itself.
Though these limitations could be overcome, we realized the real value of Moscatel was in what it taught us, not in pushing it further.
Pressing Pause
Going forward, we've decided to pause development on Moscatel. Most of the tools we use in our knowledge management workflows, such as Google Drive and Slack, are rapidly rolling out their own LLM-powered extensions. Why reinvent the wheel? While Moscatel has the advantage of enabling search across these platforms, we're starting to see some open-source solutions, such as Onyx, which offers a self-hosting option or a cloud solution for a monthly subscription fee. This cost would be far lower than the infrastructure and time costs associated with continuing to develop Moscatel.
Our decision reflects a broader industry trend toward strategic reassessment of build-versus-buy for AI knowledge tools. As we discussed options within the team, we agreed that sometimes the most strategic move is recognizing when external solutions have matured enough to outpace internal development efforts, and if it’s open-source, even better!
We'll start looking into some of these tools to create a central knowledge management hub for the DevSeed team. Moscatel was a very valuable exercise that allowed us to explore agentic frameworks, and we will keep it around as a sandbox for further experimentation!
What We Learned
Pausing Moscatel wasn’t a failure. It clarified the direction in which our energy was best spent. In building our own LLM assistant, we gained hands-on experience that reinforced three key takeaways: the importance of staying agile in a fast-moving AI landscape, the value of reassessing build-vs-buy decisions, and the power of focusing on what we know best — geospatial data and Earth observation.
Rather than pursuing general-purpose assistants, we’re now channeling those lessons into domain-specific, composable AI components that enhance our GeoAI projects. These include NLP interfaces for generating STAC queries (available to all eoAPI-based projects), context-aware dataset explainers, recommendation engines, interactive LLM-driven visualizations, and tools for automated metadata and data validation.
This shift aligns with our core approach: use LLMs to orchestrate analysis but let trusted tools carry it out. We're doubling down on building AI systems that are transparent, reproducible, and grounded in domain expertise — a vision already taking shape in our work on language interfaces for maps and foundation models for Earth observation.
Want to dive deeper into how we’re applying these insights? Explore our other blog posts or reach out to see how our AI experience can support your geospatial work.
What we're doing.
Latest