

How the Amazon Sustainability Data Initiative is Redefining Access to Scientific Datasets and Overcoming Discoverability Challenges

The Amazon Sustainability Data Initiative (ASDI) provides free public access to massive scientific data, including satellite imagery, weather measurements, and climate model outputs. The magnitude and diversity of these datasets present a big challenge for discoverability and interoperability.
Say you are a researcher needing synthetic aperture radar (SAR) data to perform deforestation detection work. You must first discover available datasets tagged as “synthetic aperture radar” manually. After finding the ESA Sentinel 1 dataset, If you wanted to locate products for a specific time period and location, you would need to research, understand, and interpret the unique file key structure used for this specific dataset. Using any other dataset in your analysis would require the same manual search and investigation effort to be used for analysis. ASDI tools, built on eoAPI, aim to improve the discovery and use of these datasets, making it easier for users to harness the full potential of open data. Now, you, the researcher, can use the common language of STAC to discover and access multiple datasets for a region and time period of interest.
FAIR as a framework
Through partnerships with a range of data providers, ASDI has made huge contributions to data Accessibility. (For a crash course on FAIR Principles (Findability, Accessibility, Interoperability, and Reuse), see Ryan Abernathy’s excellent presentation on the future of science data infrastructure). However, the magnitude and diversity of the ASDI open datasets present a big challenge for the Findability and Interoperability pillars.
Over the years, the earth observation (EO) community has made numerous attempts to solve this problem in a unified, consistent way. The STAC Specification has made enormous gains by providing a common language for describing and discovering EO data.
We’ve been working in the STAC ecosystem since its early days, and we’ve distilled that work into eoAPI, a cloud-native backend for modern, open geospatial data infrastructures. You can read more in our recent blog post on how and why we built eoAPI.
We’ve been using eoAPI for several planetary-scale projects with similar data discovery and interoperability challenges, so it was an easy choice for our work with ASDI. eoapi-cdk gave us the packaged infrastructure as code needed to rapidly deploy the STAC API backend and dynamic tiling services on AWS that provide the foundation for discoverable and interoperable ASDI data.
But simply providing the backend STAC API supporting this common language is insufficient. Thousands of new Sentinel 1 files are published to AWS every day for just this dataset alone. How can we create and manage cloud-optimized formats and STAC metadata for all these continuous streams of new data in a scalable way?
Streamlining Data Transformation
The datasets provided through ASDI are managed by external organizations in partnership with AWS. Sentinel 1, from our earlier example, is distributed as Cloud-Optimized GeoTIFFs by Sinergise. However, the bulk of the datasets are only available in archival formats with product-specific metadata. Transforming these archival formats into cloud-native formats, generating STAC metadata, and publishing the STAC metadata in our centralized STAC API are the first steps toward improving discoverability and interoperability.
This process is streamlined by leveraging the knowledge of the data community embedded in the stactools packages, which provide a consistent code interface for generating STAC metadata and cloud-native formats. Collaborative efforts to produce these stactools packages, such as those from Microsoft and Element84, are essential, and are key to the broader adoption of these standards and formats across open data programs.
To transform millions of existing files and continuously streamed data on AWS, we've developed stactools-pipelines. stactools-pipelines is designed so data providers can use a simple configuration and code template that leverages standard AWS S3 tools like event notifications and bucket inventories to drive massively scalable transformation and ingestion pipelines. Data providers write a basic pipeline configuration that wraps a stactools package, and `stactools-pipelines handles deploying and executing it at scale behind the scenes.
Our first external contributor/tester, Frederico Liporace, manages the Amazonia-1 and CBERS datasets on AWS. He followed our development documentation and created an Amazonia-1 Stactools package and a corresponding Stactools pipeline. After deploying this pipeline, STAC metadata is created and ingested into our API in real time as new Amazonia-1 images become available. We want to foster wider adoption of STAC and cloud-optimized formats for datasets stored in the ASDI program, so if you are a data provider, please contact us if you’d like some assistance getting started.
If you are a data provider, please feel free to contact us for some assistance getting started with STAC and cloud-optimized formats for ASDI datasets.
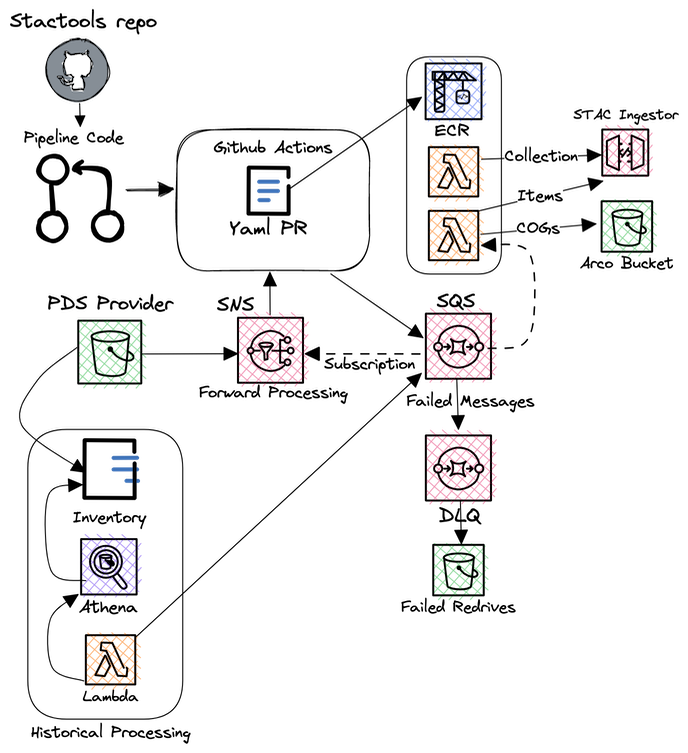
stactools-piplines
From Sparse Earth Observations to Multi-Dimensional Insights
Two primary categories emerged in reviewing the ASDI datasets, each demanding distinct cloud-native formats and metadata approaches.
The first category, satellite earth observation data, is characterized by its sparse measurements in space and time. Observations of small, defined areas at specific times are best represented using Cloud Optimized GeoTIFFs (COGs) with STAC metadata. For users who need to determine which files (or portions of files in the case of COGs) to retrieve bytes from for a particular time, area, and search criteria, the STAC API provides an excellent index. After finding relevant items, they can use geospatial data access libraries such as Rasterio or GDAL to efficiently read data from the underlying files modeled as STAC assets.
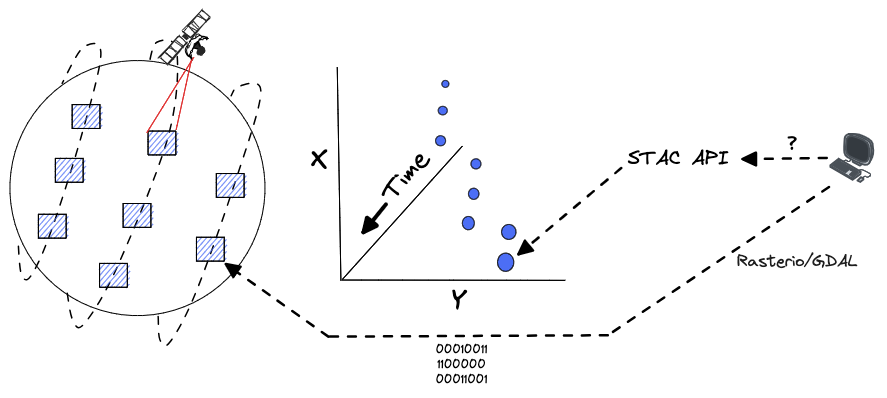
STAC API data access
The second category, multi-dimensional datasets, offer multiple variables for a single spatial extent at discrete time intervals and are typically distributed as netCDF files. Climate model output or global sensor measurement data are often distributed this way.
The scientists and data professionals using these n-dimensional datasets rely on tools like xarray, which makes working with multi-dimensional data a seamless experience. While xarray allows users to load and interact with a netCDF file easily, in most cases, this would only provide a single snapshot of the earth in time. Scientists often want to analyze changes in a system over time.
To support this type of analysis, many organizations are now distributing complete, multi-dimensional datasets with a full temporal range using Zarr.

Zarr data access
We want to provide users with an optimized, Zarr-like experience without forcing data providers to alter their distribution formats or duplicate all the raw netCDF data as a Zarr archive.
Kerchunk provides a mechanism for creating “references” which act as virtual Zarr datasets and provide an index of data chunks across multiple source files. In this way, users can interact with all the data in the underlying source files through a Zarr-like interface as if it were a single dataset.
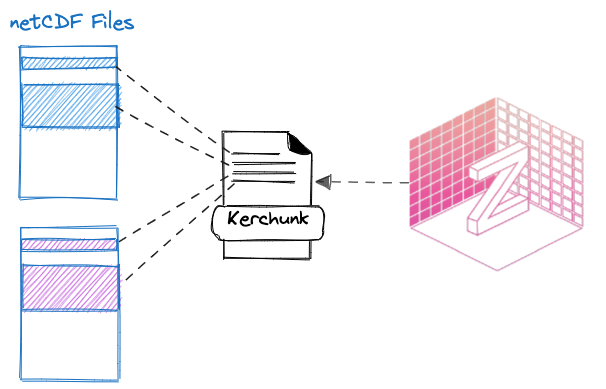
Kerchunk for netCDFs
We utilize the highly scalable Pangeo Forge (read more on its origins) platform to generate these kerchunk references. We build recipes that describe the structure and layout of source netCDF files and how Pangeo Forge can combine them into a kerchunk reference.
The Pangeo Forge platform fosters collaboration and review and identifies and documents data quality issues. While kerchunk references enhance data interoperability, STAC remains essential for data discoverability. Tools like xstac generate STAC metadata for these virtual Zarr datasets, detailing their variables and dimensions and making them available through the STAC API.
ASDI Data in Action
We're developing a central STAC API to enhance the accessibility and interoperability of ASDI datasets. While the current STAC API is experimental and subject to changes, it's available for investigative use. We've created an asdi-examples repository showcasing how to utilize this STAC API and the eoAPI Raster API, with demonstrations in AWS Sagemaker Studio Lab's Jupyter notebooks. As we expand the STAC API, we'll update these examples and welcome community feedback on dataset additions, example improvements, and streamlining the stactools pipeline creation for ASDI data providers.
Are you a researcher or a data consumer? We want to know the next datasets you’d like to see added to the API and get feedback on how we can improve the documentation. If you are a data provider, how can we make it easier for you to build a stactools pipeline? Reach out to Sean and let us know.
What we're doing.
Latest