
Open sourcing PEARL — human-in-the-loop AI for land cover mapping
- Estimated
- 5 min read


Today, we are open sourcing PEARL, the AI-accelerated platform for fast land cover mapping. PEARL allows researchers to train and improve a land classification AI model without writing a single line of code. PEARL draws on applied AI research at Microsoft Research and at Development Seed to create an entirely new approach combining human intelligence and scalable AI for fast, accurate land cover mapping. An experimental version of PEARL is available on Microsoft's Planetary Computer.
By open sourcing the code behind PEARL we hope to accelerate AI for land classification. Even more, we believe that the underlying approach to PEARL has tremendous potential to make AI more accessible across multiple other domains. PEARL provides a solid foundation for a "codeless" AI experience — a scalable infrastructure for on-demand and seamless GPU integration, fast model retrains using user input, and an intuitive approach to human-in-the-loop products. We are excited to see how you leverage and extend PEARL’s open source codebase in land mapping and beyond.
While building PEARL, we focused on solving a few key challenges — a scalable infrastructure for on-demand and seamless GPU integration, fast model retrains using user input, and an intuitive approach to human-in-the-loop product. PEARL’s open source codebase can be used by anyone to take advantage and grow these areas of work or train new models, support custom imagery sources, and standup an instance of the platform.
PEARL today
Land cover maps are essential for urban planning, climate research and understanding the human footprint. While free global land cover maps do exist, these are often not up to the task. Global models make tradeoffs and are often inaccurate. They may not be at the right resolution or cover the right land classes for a particular research effort. They are produced infrequently, representing a snapshot in time, and aren’t helpful for modern monitoring applications or for research that fuses data that may have been collected on a different cadence.
As a result, scientists and analysts currently rely on costly and time-intensive processes to generate bespoke land cover maps. Using ML to speed up the process requires even more efforts — processing satellite imagery, preparing training datasets, provisioning and maintaining expensive infrastructure, and validating the map data.
PEARL provides scientists and researchers easy access to infrastructure that is otherwise hard to setup and manage. A PEARL user can connect their browser directly to a CPU or GPU that runs models and does all the computation. PEARL has a powerful API and flexible infrastructure that creates a mapping experience similar to using desktop software that uses dedicated local GPU. PEARL infrastructure uses Kubernetes for managing multiple services (API, Tiles, on-demand GPU/CPU) and to provision custom compute resources.
A key innovation of PEARL is fast model retraining. The regional models are just a starting point. Users can retrain the model on the fly in the browser to produce checkpoints to incrementally improve the model in a direction they are interested in. A common issue with land cover mapping is shadows being predicted as water. This can be addressed by retraining the model to correctly predict shadows as part of the built environment class instead of water.
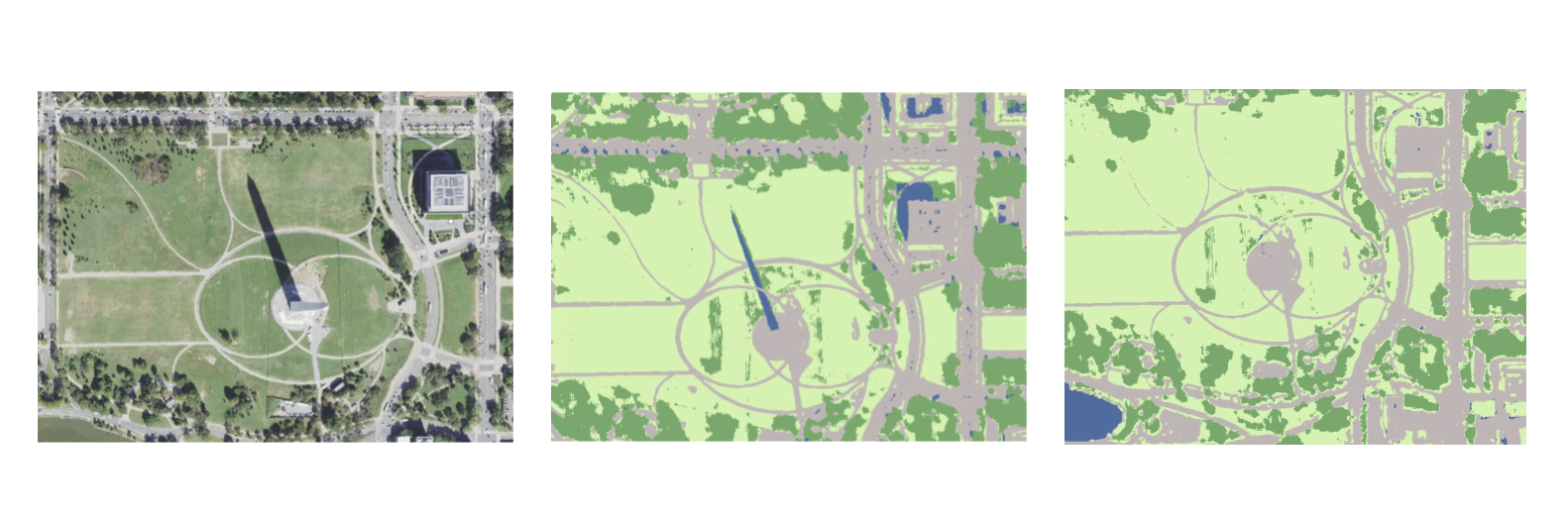
Satellite imagery, first inference, and second inference after one round of retraining
With just a few clicks or keystrokes users can submit points or polygons for retraining specific classes that the model might have incorrectly predicted. This is made possible by combining the work of Microsoft Research scientists Nebojsa Jojic, Caleb Robinson and Kolya Malkin with Development Seed’s R&D on human-in-the-loop UX and infrastructure engineering.
Over the last few months, we have been shipping several improvements to PEARL. Today, PEARL supports 5 regional models based on NAIP for the US. These models are trained with data provided by the Chesapeake Conservancy and the Spatial Analysis Lab at University of Vermont.
Using the code
We are excited to open source all components of PEARL. This includes the API and infrastructure management, frontend, and ML training pipeline. These repositories will allow anyone to train a new model using appropriate training data and run an instance of PEARL. As you might imagine, setting up PEARL on your own requires managing a somewhat complex infrastructure. For many researchers you may be better served using the limited access public version of the platform. We are open to collaborating and supporting additional use cases and ideas.
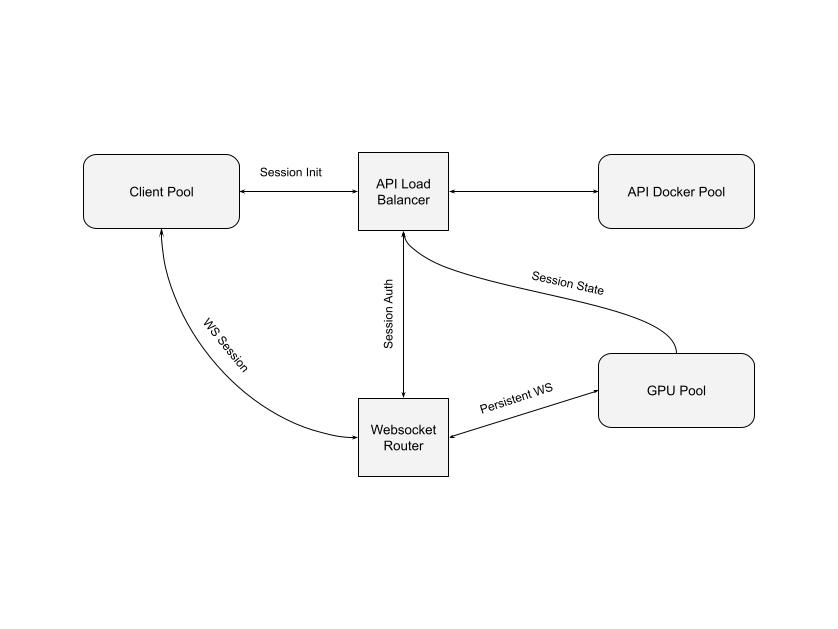
The orchestration code currently only supports running on Microsoft Azure, but by using Kubernetes, we have built it to be cloud provider agnostic as far as possible, and porting to other cloud providers should be relatively straightforward. By default, the PEARL backend will run models on CPU compute. We also publish a stand-alone Helm chart to directly install PEARL onto an existing Kubernetes cluster. PEARL’s ML training pipeline is built specifically for NAIP and written to run on AzureML. The pipeline supports FCN, UNet and DeepLabV3+ architectures. We also introduce the use of seed datasets to improve the retraining experience.
Future development
Our vision for PEARL is a seamless, collaborative experience for creating highly accurate land cover maps anywhere in the world. Our immediate roadmap involves expanding the imagery sources and starter AI models. The experimental version of PEARL is currently limited to NAIP imagery in the US. We are currently integrating a range of public and commercial imagery sources, and building regional models across the globe. We are creating highly accurate and diverse training datasets for an extensive set of classes and growing the user and developer community. In the meantime we are exploring using the PEARL experience and code to solve other large scale mapping problems.
In the next few months, we’ll be working closely with our partners to improve and maintain PEARL. Let us know (GeoAI@developmentseed.org) how PEARL could be useful for you in your project, we’d be happy collaborate!
What we're doing.
Latest