

Deep reinforcement learning could support tighter human-machine collaboration
For nearly two years, we’ve been researching a new approach to map roads in satellite imagery using machine learning (ML). Deep reinforcement learning (RL) is a relatively new subfield of ML that we’re applying for autonomous road mapping. Rather than the current approach of classifying individual road pixels and extracting road vectors from the result, RL models can take a satellite image as input and then manipulate a cursor to “trace out” a road network. This mimics how humans map, and therefore has potential to better integrate with and massively accelerate human mapping efforts.
 Satellite image and road network from the SpaceNet dataset.
Satellite image and road network from the SpaceNet dataset.
Introduction
Road maps are vital for everyday navigation. Good road maps guide people from Point A to Point B, help farmers and businesses bring goods to market, and allow governments to better connect citizens to services. Many parts of the world still aren’t on the map or have incomplete maps, which leads to wasted effort and poor infrastructure planning. Projects like OpenStreetMap start to address this by empowering regular citizens to trace roads on top of satellite images thereby creating free and open road maps. We and many others are researching ML algorithms and tools that will help find gaps in the road map and then empower citizen mappers to fill those gaps faster.
The ML community has made serious efforts to create road mapping algorithms over the past few years. For example, CosmiQ Works leads the popular SpaceNet competition series to support open tools for road and building tracing. Facebook’s recent announcement of the RapiD tool also marked a major milestone as it brings autonomously traced roads into iD — a popular interface for mapping in OpenStreetMap. So far, the most common ML approach is a two-step process. First, an ML model predicts which pixels in an overhead image belong to a road using a semantic segmentation approach (Figure 1, center). Then, most groups convert this segmentation map into a vectorized road network comprised of nodes and edges (Figure 1, right).
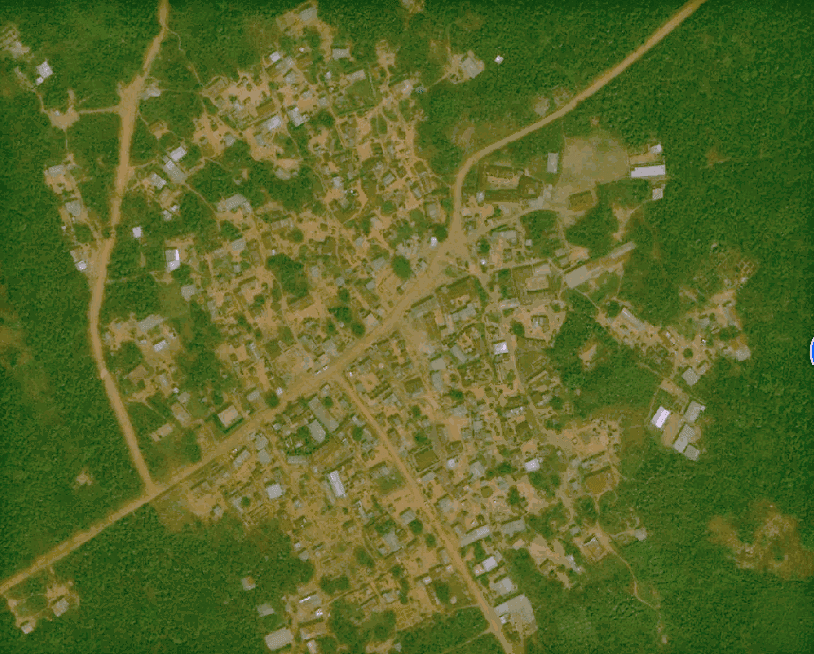

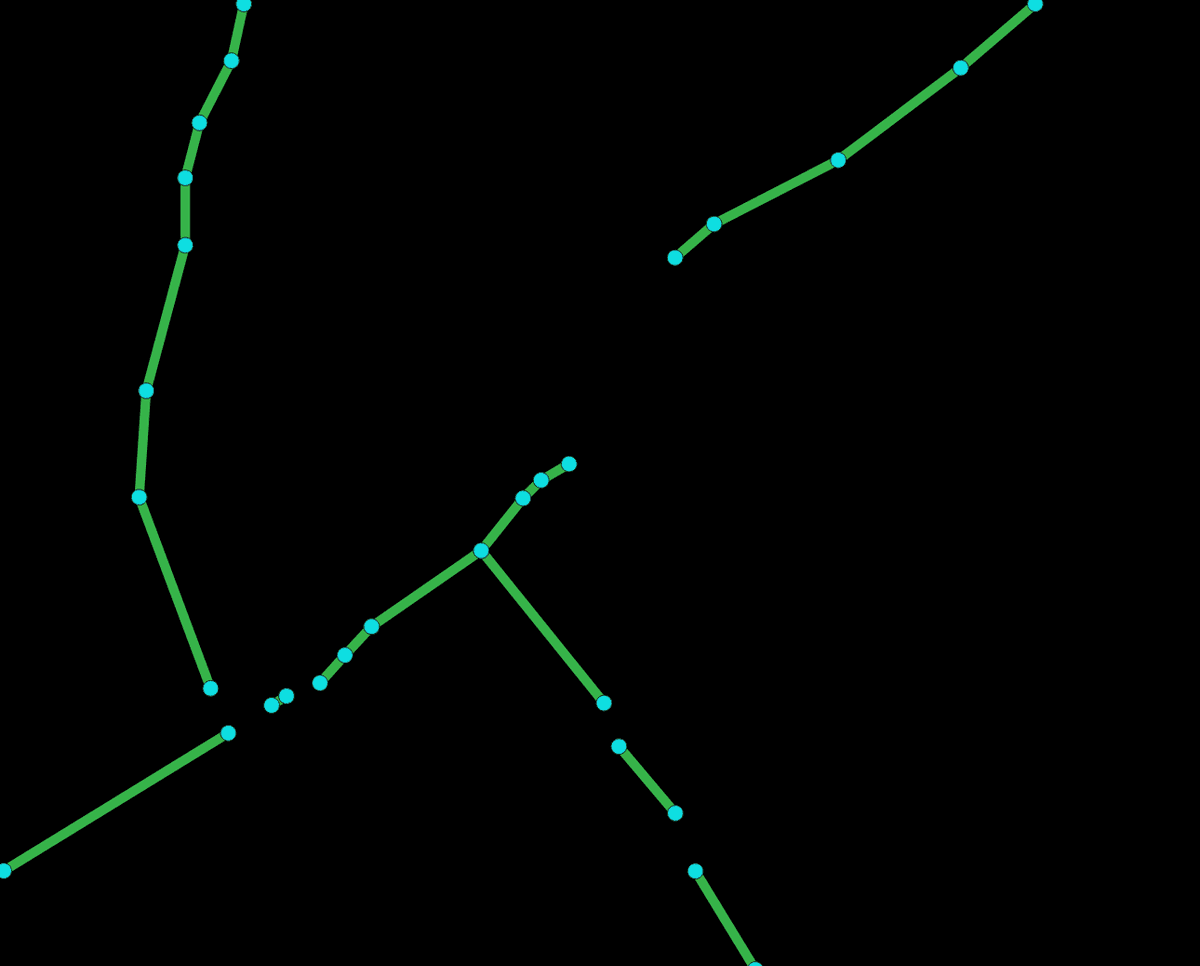 Figure 1. Road segmentation and vectorization. The most common strategy for generating road maps is to segment the overhead image and then extract vectors from this segmentation mask. Left: RGB satellite image. Middle: semantic segmentation map where each pixel’s probability of belonging to a road is predicted by an ML model. Right: illustration of a vectorized roadmap might be obtained by extracting a road network of nodes and edges from the segmentation map. Quality of the final roadmap can vary, so manual validation and cleanup is often required.
Figure 1. Road segmentation and vectorization. The most common strategy for generating road maps is to segment the overhead image and then extract vectors from this segmentation mask. Left: RGB satellite image. Middle: semantic segmentation map where each pixel’s probability of belonging to a road is predicted by an ML model. Right: illustration of a vectorized roadmap might be obtained by extracting a road network of nodes and edges from the segmentation map. Quality of the final roadmap can vary, so manual validation and cleanup is often required.
While some groups have had real success with the segmentation + vectorization strategy, this approach is encumbered by some important drawbacks: It’s computationally intensive, labeling images at the pixel level is tedious, and the vectorization step is notoriously difficult to get right. Therefore, we’re experimenting with deep reinforcement learning (RL) models (see here or here for an overview) overcome some of these limitations. Specifically, we’re training RL models to manipulate a cursor within a mapping environment. RL models are relatively light in terms of compute resources required, they can directly use vector data in training (which is plentiful), and the RL model directly outputs vector data, as shown below. This problem formulation is also philosophically attractive because the model’s output — a sequence of cursor movements that trace road segments — mirrors how humans map road networks.
Reinforcement learning for roads
RL models excel at making a long series of decisions in response to input as opposed to typical ML models that map a single input data point to a single output. We’re training RL models to make a sequence of cursor movements on top of an overhead image. Each prediction (or “action” in RL parlance) taken by the model consists of 3 parts:
-
Where to move the cursor (x, y position)
-
Whether to trace a new road segment (pen down) or simply move the cursor (pen up)
-
Whether to make another action or quit mapping
Notice that this process roughly replicates how humans trace roads. For this reason, we’re hopeful that RL models could act like “AI-Assist” plugins for editors like iD or JOSM. Figure 2 illustrates this point — a mapper and the model would take turns collaborating to trace a road network. The RL model will take an image and any mapped road segments as input and then suggest several new road segments at once. We then rely on a human to verify the machines suggestions, or fix errors by manually tracing new road segments. The model will then incorporate these human edits into its next prediction, thereby continuing the interactive mapping cycle.
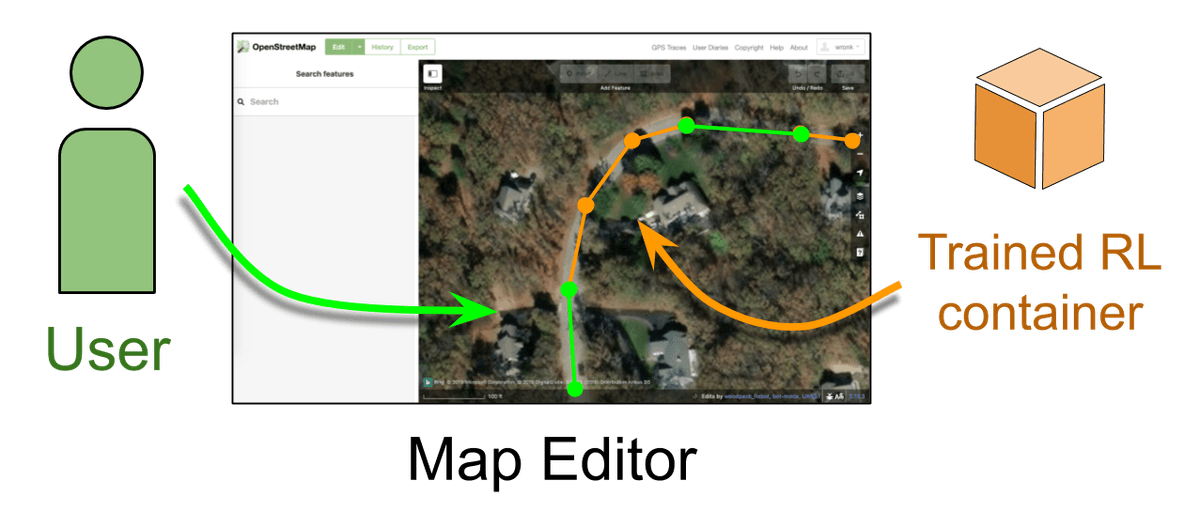 Figure 2. Planned interface for integrating an autonomous assistant into a map editor. While we are still working on developing the RL model, this illustrates the interface where human mappers and the RL model could collaborate. When using a map editor (center), a user (green) will trace road segments on top of overhead images as is done now. However, we will augment the user’s work by deploying a trained RL model (orange) to the editor backend, which will autonomously suggest road edits. The RL model will use the overhead image and any existing road geometry as input to predict the next 5–10 road segments. Users could quickly validate and accept its suggestions or fix any incorrect ones. Anytime the user makes a new edit (or fixes a prediction), the model would immediately recompute the next batch of 5–10 road predictions.
Figure 2. Planned interface for integrating an autonomous assistant into a map editor. While we are still working on developing the RL model, this illustrates the interface where human mappers and the RL model could collaborate. When using a map editor (center), a user (green) will trace road segments on top of overhead images as is done now. However, we will augment the user’s work by deploying a trained RL model (orange) to the editor backend, which will autonomously suggest road edits. The RL model will use the overhead image and any existing road geometry as input to predict the next 5–10 road segments. Users could quickly validate and accept its suggestions or fix any incorrect ones. Anytime the user makes a new edit (or fixes a prediction), the model would immediately recompute the next batch of 5–10 road predictions.
Preliminary results
The animations below (Figures 3 and 4) show the RL model in action. We’re using data from the SpaceNet roads dataset to obtain satellite imagery and vectorized road networks from 4 cities: Paris, Shanghai, Las Vegas, and Khartoum. To start, we’ve simplified the road mapping problem by binarizing the overhead images (roadway is white, background is black) rather than using the RGB or multispectral image data. The simplified tasks is easier for the RL model to learn and has helped us understand how the final performance is affected by the simulation environment and choices of model parameters.
To achieve these preliminary results, we relied on the Stable Baselines toolbox (specifically, the PPO2 algorithm) and a custom road mapping environment built to the OpenAI Gym standard (see the end of this post for more details). We found that the model was able to handle this task reasonably well for simple or intermediate difficulty road networks where there are only a few long, straight segments (Figure 3). The model doesn’t exhibit fine grained control yet for short segments and small details (Figure 4); it prefers to draw only a few long road segments across the mapping environment.


 Figure 3. Simple mapping examples. In these animations, the first frame shows the binary road map which is displayed to the RL model. The second frame shows positive score locations (or dots) which help us quantitatively evaluate each action. The model receives positive reward when it draws line segments that overlap these points (but note that it never sees this score map). The following frames first show the random start position of the cursor (red dot) and then the model’s actions to trace road segments. The action number and reward per action are shown at the top of each frame.
Figure 3. Simple mapping examples. In these animations, the first frame shows the binary road map which is displayed to the RL model. The second frame shows positive score locations (or dots) which help us quantitatively evaluate each action. The model receives positive reward when it draws line segments that overlap these points (but note that it never sees this score map). The following frames first show the random start position of the cursor (red dot) and then the model’s actions to trace road segments. The action number and reward per action are shown at the top of each frame.

 Figure 4. Complex mapping examples. These examples show two complicated road maps, which illustrate the limitations of our current model. Specifically, the model sometimes struggles to trace small or short road segments within a larger road network, or doesn’t quite connect road segments at intersections.
Figure 4. Complex mapping examples. These examples show two complicated road maps, which illustrate the limitations of our current model. Specifically, the model sometimes struggles to trace small or short road segments within a larger road network, or doesn’t quite connect road segments at intersections.
RL models are generally light in terms of their memory and compute footprint, which is exemplified by the fact that these models can be trained and deployed on standard CPUs. This has a number of interesting implications. First, it is more cost effective and reduces electricity usage when compared to approaches that require GPU clusters. Second, the option to run on a CPU means more mappers can interact with these models on their own machines. Even during model training, typically the most computationally demanding portion step in a model’s life cycle, we could achieve ~200 training frames per second on a MacBook Pro. This implies we can eventually provide real time predictions in the context of tools that permit AI and humans to work together, even without an internet connection to remote cloud infrastructure. Third, by removing the high cost of model training and deployment, RL would also lower the bar for model iteration and analysis of new imagery when it becomes available. This advantage will help mappers keep up with the accelerating pace of satellite imagery collection. As of early 2020, the popular GPU-based segmentation + vectorization approach is still the go-to method for autonomously predicting road networks, but we believe that these preliminary results and the strategic advantages necessitate more research into an RL-based approach.
Going forward
We’re excited that RL could engender new and computationally efficient road mapping tools. But note that the end goal here is not to engineer humans out of the mapping process. Instead, we want mappers to spend time where they’re most valuable — we want them to focus on the most difficult and interesting components of a road network and allow autonomous algorithms to handle the simple or mundane mapping tasks. We believe the best use of ML technology is to empower humans and not replace them.
To realize this goal, we still have plenty of work left to do. Our next big step is to transition from binarized satellite images to true overhead images (in either grayscale, RGB, or multispectral format). This requires that the RL model learn to extract much more sophisticated features than is done currently. We’ll likely explore other convolutional neural networks or import feature networks trained on related image analysis tasks. After that, we’ll test other image resolutions to see if performance varies by pixel size. Finally, we need to determine the best way to integrate an interactive AI assistant into the mapping tools users are familiar with. There are many user-experience questions including the minimum user-tolerable model performance, performance by geographic area, and how many road segments the model should suggest at once. After overcoming these challenges, we’ll look to implement our RL model as a plugin into iD or JOSM (as sketched in Figure 2), so mappers can leverage these tools in their everyday work.
Extra detail: Building a good simulation environment
Deep RL models train differently than most deep ML algorithms used today. They don’t rely on supervised learning, which uses a set number of data samples and corresponding ground-truth labels. Instead, RL models train within a simulation environment. The model (or “agent”) makes a set of actions within the simulation. For each action or a set of actions, the environment provides numerical feedback about how “good” or “bad” the agent’s actions were. As a concrete example, some of the foundational deep RL work was completed on old school Atari 2600 video games. There, the model controlled the on-screen player and then used the game score as feedback. See this example showing an RL model learning to play “Breakout.” Again, there is no single correct way to get a high score — the RL model learns and evaluates strategies to reach a high reward by learning from millions of actions taken within the simulation environment.
Creating a good simulation environment is a key component to solving any problem with RL. In this work, we created a simple game to numerically define a “good” road mapping strategy. For each satellite image (Figure 5, left) from the SpaceNet dataset, we knew exactly where the road centerlines are (Figure 5, middle) because we have hand-traced vector maps. We generated a score map (Figure 5, right), containing a bunch of discrete reward locations. When an RL agent adds a road segment that overlaps one or more of these dots, then it received a positive reward commensurate with the number of dots acquired. This is somewhat similar to Pacman, except that the model tries to trace over the roads instead of eat them. There are likely other simulation environments that would perform well, but we found that the score maps necessary for training were fairly easy to construct and the per-action compute cost was low. Both of these points helped us get our RL approach off the ground quickly. In the future, we’ll continue to explore new approaches that might accelerate RL model learning or improve final performance.


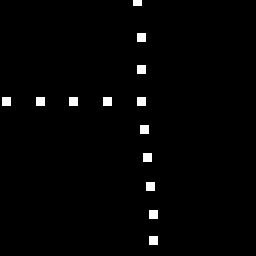 Figure 5. Components of our RL simulation environment. Left: Example overhead satellite image from the SpaceNet dataset. Middle: Example image displaying a binary road map used to generate the results shown in this post. Right: Example score map consisting of white reward dots. If the model lays a road segment that overlaps one or more of these dots, it receives a positive reward.
Figure 5. Components of our RL simulation environment. Left: Example overhead satellite image from the SpaceNet dataset. Middle: Example image displaying a binary road map used to generate the results shown in this post. Right: Example score map consisting of white reward dots. If the model lays a road segment that overlaps one or more of these dots, it receives a positive reward.
What we're doing.
Latest