
ML Enabler — completing the Machine Learning pipeline for mapping
- Estimated
- 4 min read

We’re partnering with the Humanitarian OpenStreetMap Team, Facebook, and Microsoft to build AI-based mapping tools to empower mappers around the world. We believe this will help volunteers to make sure their time is well utilized and improve the quality of the map where it’s most needed.
 Looking Glass segmentation
Looking Glass segmentation
Over the last few weeks, we built a key piece of the AI-Assist pipeline called the ML Enabler. The ML Enabler, as the name suggests, enables applications to take advantage of Machine Learning. It organizes and efficiently stores ML-derived map data so Tasking Manager and other tools can draw on this information via a standard API and enhance their own functionality. For a further explanation of how Tasking Manager and iD would use ML-derived data, check out our previous post and the recent announcement from HOT. With ML Enabler, we hope to bring more models to better support project manager’s plan task areas and help volunteers add new map features faster.
A registry of models for public good
One of the main goals of the ML Enabler is to serve as a registry of public and private machine learning models. The registry is critical because the models themselves are independent projects with different goals and lifecycle. For example, our looking-glass model only predicts building area while Microsoft’s buildings API outputs footprints. Integrating them one by one into tools like Tasking Manager is less than ideal. The ML Enabler’s registry, however, will allow us to track many different models from disparate organizations all in one place and take advantage of all them. If you’re looking to get an accurate picture of urban areas in East Africa, imagine being able to use an ML model that is very good at predicting buildings in Uganda and another one in Kenya. The ML Enabler can track multiple versions, metadata like area of coverage and success rates and make them available to Tasking Manager through the same API.
Common language for existing mapping tools
No ML model is the same. Models have varying schematics for input data and output predictions. ML Enabler exposes standard utilities to work with any model, and also sets some expectations from the model. These expectations are carefully chosen by our ML team. For example, the models should be versioned and there should be an API to interact with the model output. Our Looking Glass model adopts TensorFlow Serving. Any similar API would work just fine for integrating with ML Enabler.
Predictions from a model may not be directly useful to tools like Tasking Manager. For example, Looking Glass predicts building area in a region. This information is only actionable to the mapper if we can compare it with OSM to find what regions on the map need to be prioritized. Looking Glass predicts at zoom 18, which is perhaps a bit too granular for Tasking Manager. ML Enabler provides basic functions and an interface to augment and aggregate the predictions, as necessary, through the command-line. The API stores predictions indexed by quadkeys. The advantage of using quadkeys is its binning strategy. Practically, the use case from Tasking Manager is to get the building area for a polygon while creating a new project, which helps the project manager determine what priority areas are for mapping. The API already has functionality to augment the Tasking Manager project GeoJSON with prediction data stored in the Task Annotation API.
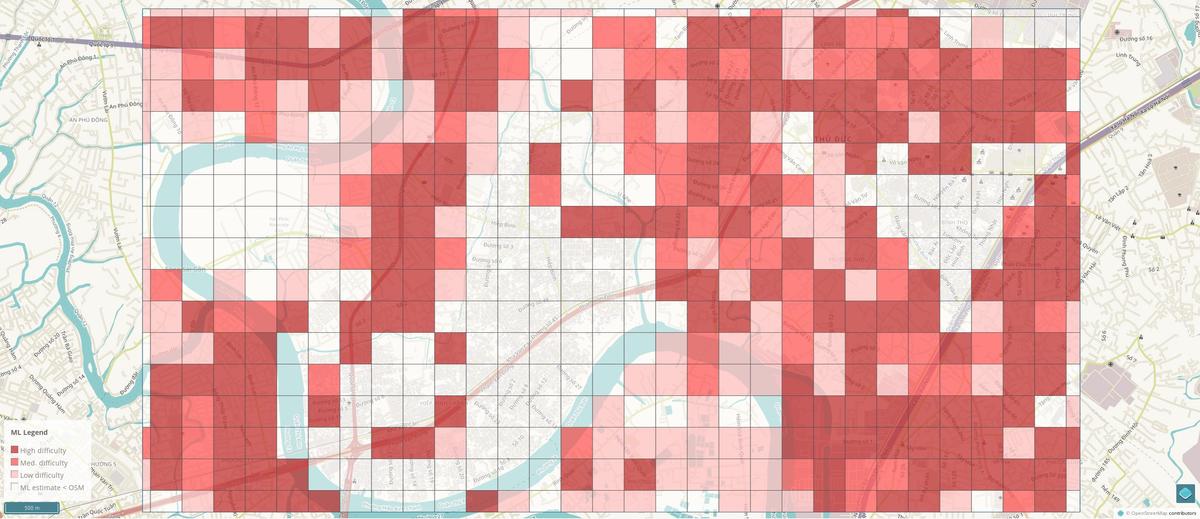 Prioritization in tasking manager based on ML data
Prioritization in tasking manager based on ML data
It’s relatively straightforward to integrate a new predictor and aggregator. At the moment, we’ve integrated Looking Glass and Microsoft’s building footprints API.
Run models on-demand
ML Enabler makes it easier to collect and organize AI-derived map information. In the near future, we want to improve the pipeline to further lower the bar for applying machine learning tools to mapping. Storing the docker information about each model allows us to build a job management system to run model containers on the cloud and fetch predictions automatically for new areas. This would allow us to scale models as necessary, and update the map as accurately as possible. We’re looking to add geometry storage functionality so ML Enabler can interface directly with tools like iD.
We hope ML Enabler is useful in bringing the vast amount of ML models and knowledge to improve the map. If you have questions or comments, feel free to hit me up on Twitter!
What we're doing.
Latest