


New machine learning techniques hold tremendous potential to revolutionize our ability to solve complex social and environmental problems. However, there is increasing recognition that these tools can return incorrect and even biased results. This results in automated irrigation equipment that works well for certain crops or areas but which overwaters in others. Or self-driving trucks which can navigate over asphalt roads but fail to reach their destination over dirt or gravel. Ultimately these tools are as good as the data that they learn from. To build algorithms that work for the whole world we must use training data that better represents the world’s diversity. This post lays out a vision for creating geo-diverse data sets.
The Google Brain Team recently released a paper investigating geographic bias in open data sets for machine learning. Specifically, they found that ImageNet and Open Images “appear to exhibit an observable amerocentric and eurocentric representation bias”. So while these datasets have been invaluable as benchmarks for advancing the machine learning field, their use in production models should be called into question.
We suggest that examining the geo-diversity of open data sets is critical before adopting a data set for use cases in the developing world. No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World
This tracks with our own experience applying machine learning to analyze satellite imagery. Roads, buildings, agriculture, settlements, and poverty look different from space depending on where you are in the world. Even within a country you can see big differences. We recently mapped the electricity grid in Pakistan using training data from one region of the country. When we applied that model to predict power lines in the rest of the country, our model made more errors in farmland and other terrain that was underrepresented in our training data. Our colleagues at N/Lab in the University of Nottingham have experienced this phenomenon in their work and are currently working to better quantify the impact of geo-diversity in this space.
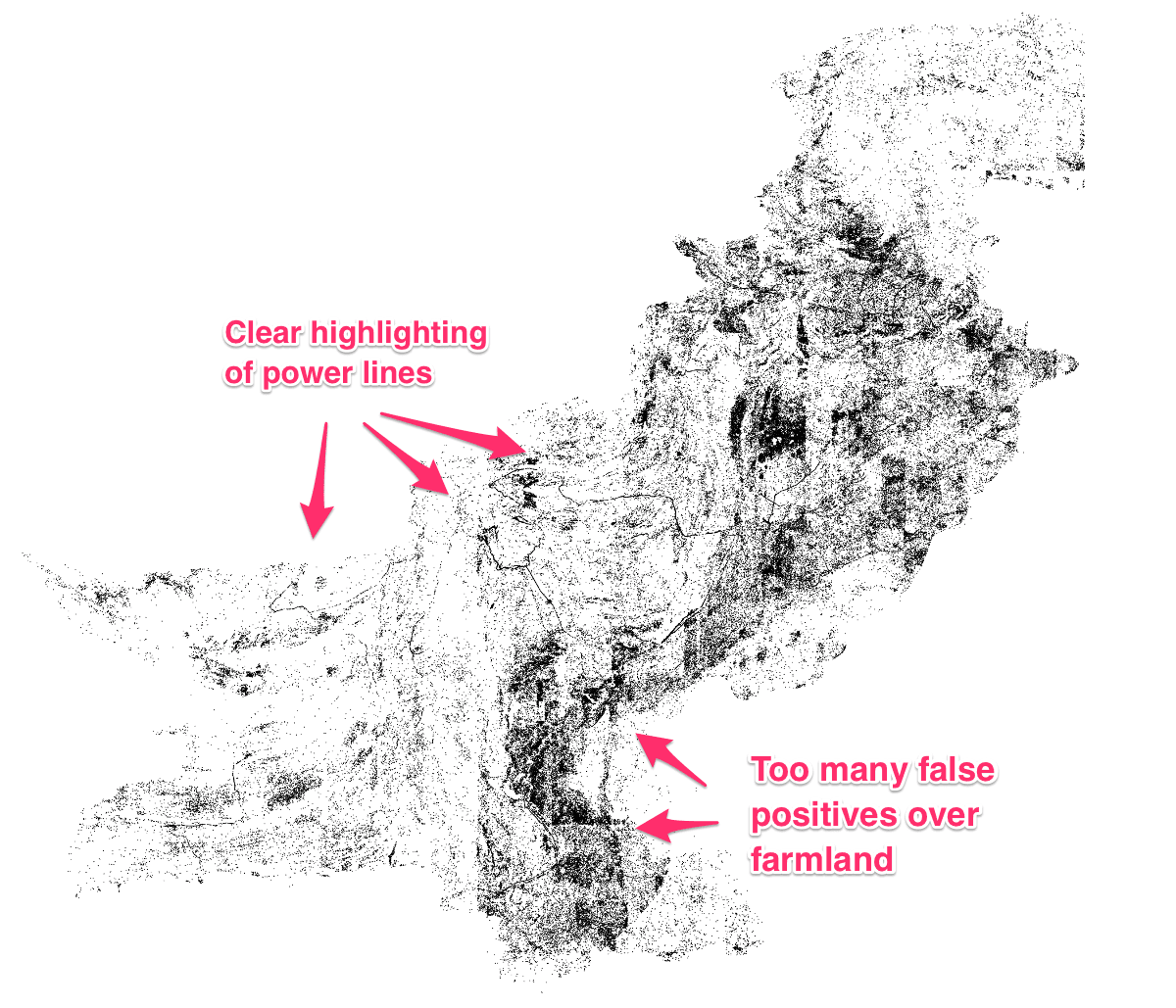 Black dots correspond to locations where the model predicts a high voltage tower was present. In the mountainous desert region of Pakistan, the model performed relatively well. In the Eastern agricultural region, the model predicted many more false positives as we did not obtain any training data from this region.
Black dots correspond to locations where the model predicts a high voltage tower was present. In the mountainous desert region of Pakistan, the model performed relatively well. In the Eastern agricultural region, the model predicted many more false positives as we did not obtain any training data from this region.
In the Pakistan case, we were able to recognize representation issues due to obvious geographical differences in model performance (seen above). But in many cases the bias in our models might be subtler and harder to detect. Still these biases can have real impacts. What we realized is that there aren’t good tools to evaluate, improve, and articulate the level of geo-diversity in our training data. And therefore we are missing important tools for understanding and correcting bias.
Getting this Right
Open Data
Open data and data readiness take on a new importance in the context of machine learning. Engineers are able to develop accurate agricultural models for predicting corn output in the US because there are decades of good data about corn yields from the US Department of Agriculture. This data is paired with readily available, open satellite imagery from sources like Landsat and Sentinel to create a predictive algorithm.
But while the imagery provides worldwide coverage, open data on agricultural yields doesn’t exist for many crops or in many countries. To power new machine learning tools, it is more critical than ever to work with governments to generate open data that creates knowledge and value from all that open imagery. The World Bank, United Nations, and others groups should work to provide open data sets that are standardized across countries.
High quality training data
There are a few great training data sources for satellite machine learning data: SpaceNet, Functional Map of the World, and xView. We need to expand on these and create more high quality training datasets that are representative of many parts of the world. These can be useful in training new algorithms and also for evaluating the generalizability of existing models. Building a separate validation set would be a valuable tool in ensuring that algorithms generalize to the global South. This data could be used as a scoring set to encourage developers to build and improve models so they excel beyond the Western world.
 Training data from Functional Map of the World. Images from https://arxiv.org/pdf/1802.03518.pdf
Training data from Functional Map of the World. Images from https://arxiv.org/pdf/1802.03518.pdf
Tools for generating diverse datasets
People don’t generate diverse data sets because it is difficult. It’s hard and time consuming to create labeled data even without thinking about geo-diversity. Satellite data providers are usually serving up images as single scenes which are big bulky files. As a result, many people just work with one or two scenes in one part of a country. In the best case they may pick a few scenes from different areas.
Public and commercial data providers need to distribute their data to allow for downloading small chunks of imagery. This can be in the form of Cloud Optimized GeoTIFFs, which allow for reading small windows of images via HTTP Range Requests, or via map tiles (e.g. TMS or WMTS). Planet is pushing this forward but many of the workflows are still based around limited geographic areas. DigitalGlobe and Planet both have global basemaps but quality isn’t guaranteed in all areas. We should continue to build tools to make finding quality imagery for multiple arbitrary locations as easy as possible.
Improving labeling
OpenStreetMap is a great resource for most feature detection problems. It is a truly global dataset and can be used to create labels to match up against diverse sets of satellite images. The simplest way to access the data now is via QA tiles or Overpass. Both of these have some challenges when trying to quickly download/access small chunks of data. The continuing development of OSMesa could provide easier methods of accessing OpenStreetMap data. We also need better tools to deal with offset of the data from satellite imagery. And knowing that data quality isn’t consistent globally, we need tools to find out where the map is complete.
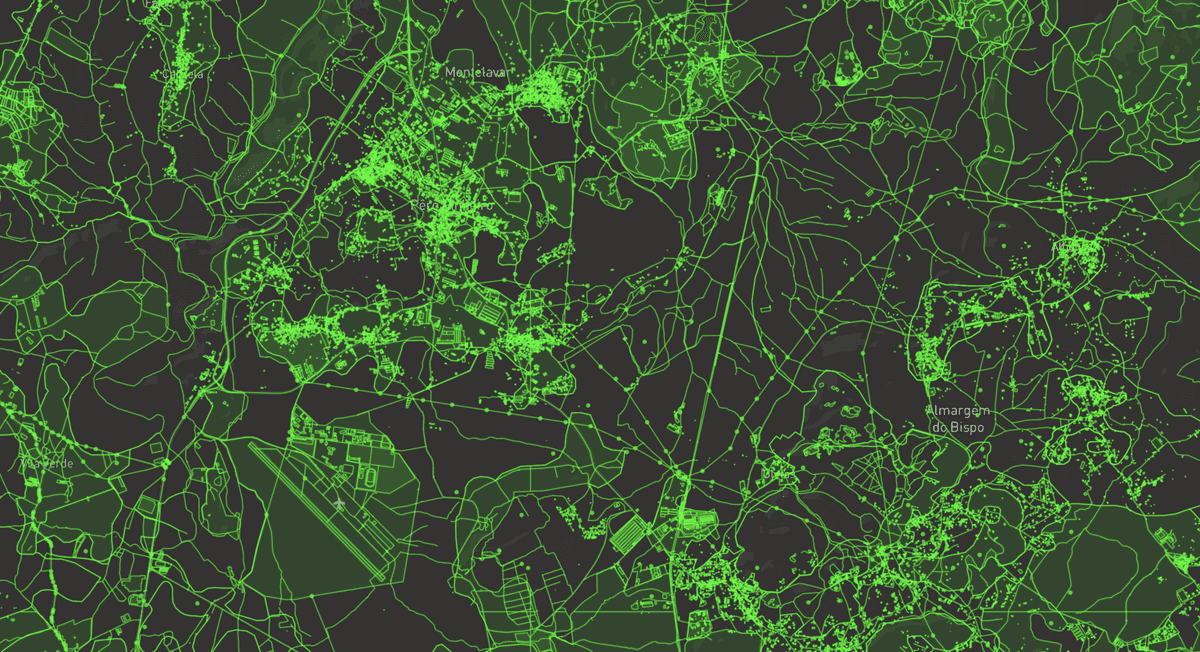 OpenStreetMap data over Portugal. Visualized with mbview and QA tiles
OpenStreetMap data over Portugal. Visualized with mbview and QA tiles
Tools to evaluate diversity
Finally, we need a way to look at how representative a dataset is of a country or of the world. One way to do this is running over a global satellite layer with a Generative Adversarial Network (GAN). This can generate a machine learning-derived compression of each image that captures specific features (e.g. mountains, vegetation distribution, hurricanes, or smoke patterns). Then we can compare, by image similarity metrics, our data set to the area we want to generalize over. This will help evaluate whether our training images are a representative sample of our desired deployment region.
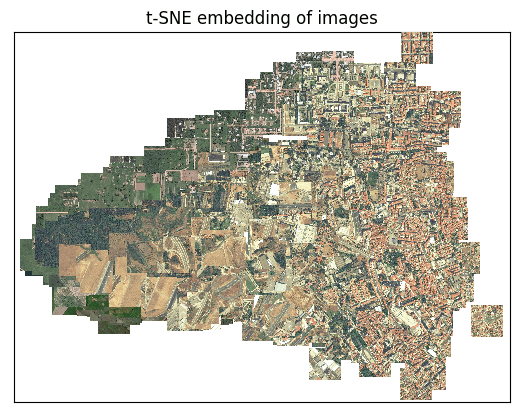 Satellite images shown in a 2-dimensional space based on feature similarity (dimensions reduced with tSNE). Created with artificio
Satellite images shown in a 2-dimensional space based on feature similarity (dimensions reduced with tSNE). Created with artificio
Next Steps
Here are some concrete steps we are taking right now to improve geo-diversity in deep learning:
-
Using images and labels from multiple locations when training a supervised machine learning model for satellite imagery. We’ve started this effort with our open source label creation tool: Label Maker. The next step will be figuring out how to scale this approach.
-
Building tools to better identify training locations. How do we know that our data is representative of our prediction area? How do we know which satellite imagery products have good coverage in which areas? If we’re using OpenStreetMap as a data source, how do we query for map completeness? We’re working on tools to answer these questions; ideally these would eventually be a single webtool or API.
-
Supporting the broader training data community. Spacenet, Functional Map of the World and xView are huge steps forward in this space. How can we make this effort more scalable? Our Data Team can contribute to this but we need multiple groups adding data sets and a system for cataloging and validating this data.
-
Assisting Earth on AWS as producers and consumers. We worked with AstroDigital to make MODIS available on AWS and built tools to make use of their innovative Landsat archive. Earth on AWS is also hosting machine learning specific data and we’ll continue to use and support this program.
-
Working with NASA to get data into the cloud: We’re working on Cumulus, a cloud-based prototype to ingest, process, catalog, archive, and distribute NASA’s Earth Data streams. Making this data more available gives everyone more options when looking for relevant satellite imagery.
-
Supporting the development of OSMesa. Azavea is building a toolkit for running analysis on OpenStreetMap at scale. We’re collaborating on the design and architecture of core components of this project.
We are doing much of this work in our own R&D time. We’d love to accelerate this with partners and supporters who also care about ensuring that the whole world benefits from advances in machine learning. Specifically we need the following:
-
Data providers willing to let us help them to create machine learning-ready data
-
Partners with ground truth data about crop yields, poverty levels, mosquito-born disease incidence, etc.
-
Developers who want to help us work on Label Maker and other open tools we’re releasing
-
Machine learning folks committed to geo-diversity willing to be beta-testers
What we're doing.
Latest