
A user-centric, open-source AI model for Earth

Overview
In collaboration with our partner Clay, we have built a unique user-centric foundation model of Earth. This model makes it faster and cheaper to develop AI-centered applications that are customizable to your data and needs. Clay can be used over a wide range of data sources and spatial resolutions—no matter the platform. Whether you have imagery from drones, airplanes, or satellites, Clay can help.
Challenge
Earth observation foundation models are hard to build but also hard to use. They are hard to build because of the complexity of model architectures and the sheer scale of data required to train them. They are hard to use because they tend to require machine learning expertise and have rigid specifications for input data sources and formats. Our challenge was building a model that is flexible, globally applicable, and easy to use all at once. For this to be possible we had to innovate on the model architecture as well as the data pipelines.
Outcome
We have produced Clay v1, a uniquely versatile foundation model. Clay can accept images from a wide range of sources, different image sizes, pixel resolutions, and spectral band combinations. All of these aspects are input parameters and can be varied freely. This makes Clay usable across a wide range of applications and simplifies usage for use cases with specific data needs.
Model Architecture
Clay's unique architecture offers flexibility in model usage. It stands on the shoulders of giants, drawing architectural inspiration and implementation details from other recent models like DOFA, Prithvi, GFM, SatMAE, ScaleMAE and SpectralGPT. At a high level, the model is based on a two-stage transformer architecture.
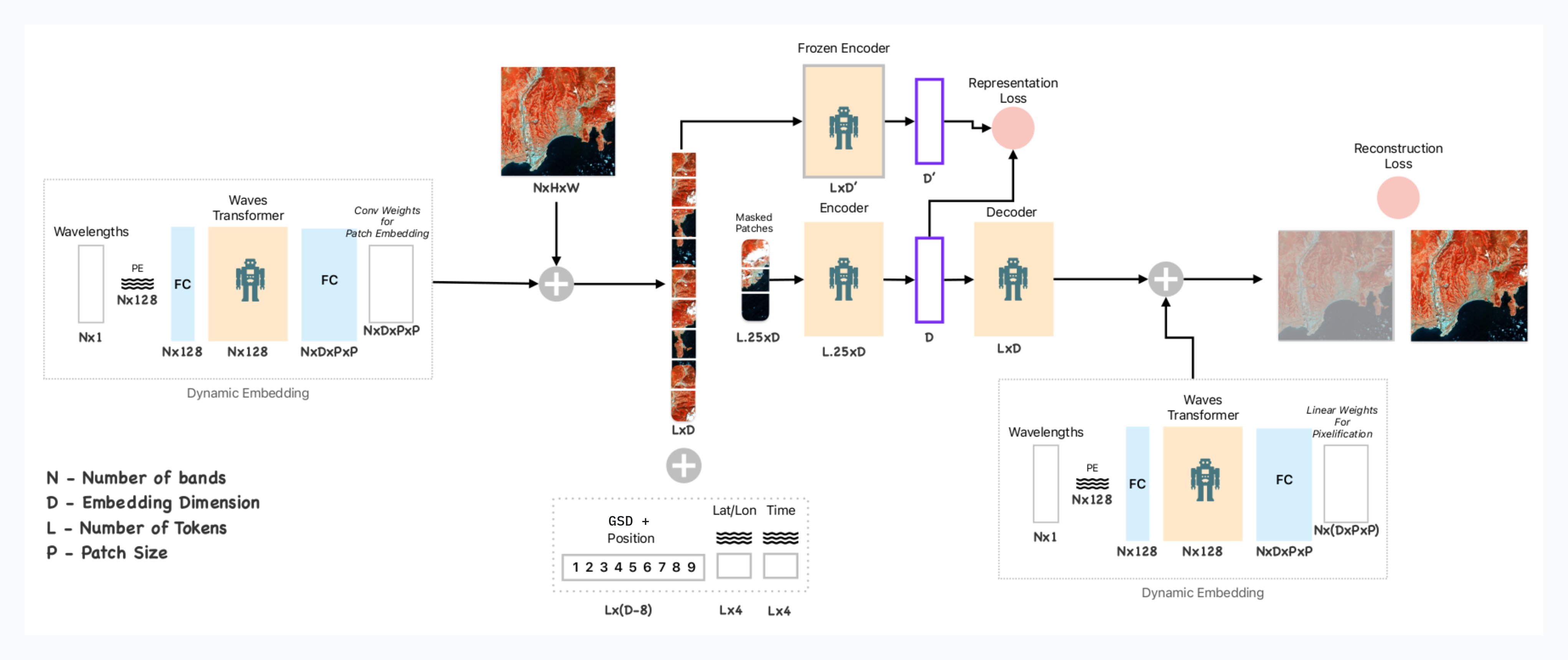
Clay architecture
The first transformer layer acts a meta learner & is built to standardize the input data for MAE. We parameterized as many aspects of the input as possible, allowing for maximum flexibility in shaping the input data. The model takes as input:
- Date of image capture
- Location of image
- Spatial resolution of the imagery
- Number of bands to be provided
- Central frequency of each input band
The second transformer is a more regular Vision Transformer (ViT) architecture, trained using a Masked Auto-Encoder (MAE) self-supervised learning technique. The model is additionally attached to DINO as a teacher network, ensuring that the feature learning is as good as possible and avoiding over-specializing on the MAE task alone.
Data Pipeline
We produced a huge dataset of about 70 million images that were used to train the model. The data was globally sampled from multiple data sources, ensuring a balanced distribution between high-resolution imagery, medium-resolution imagery, and Synthetic Aperture Radar (SAR) imagery. We focused on creating a reproducible and scalable data pipeline, packaged in stacchip, a dedicated library for dynamic image chip production. Stacchip relies heavily on the STAC and COG standards to make training data generation scalable and reproducible. With this data pipeline, the model has trained for 6400 GPU hours on H100 chips.

Similarity search results. The reference image is the first one on the left, the others are selected by similarity score. This is useful to find features such as pools or solar panels in no-code applications.
Clay’s focus on usability
Clay has been clear from the beginning that it has a strong focus on user needs. Clay’s goal is to produce a model that is easy to use and can be picked up by a larger community, including startups and large businesses. For this reason, all aspects of the model are fully open. All data used for training is fully open, which ensures there is no legal uncertainty. The licenses for the code, model, and data produced in the project have permissive licenses that allow for commercial use. You can learn more about their mission in this interview.

Examples of some of the applications Clay is exploring with this open-source AI model for earth.
But Clay’s mission also puts emphasis on accessibility. Open licenses alone do not necessarily guarantee that AI models are accessible. There are big hurdles in the usage of such models, and in many cases, advanced machine-learning knowledge is required to use them. Our partner Clay is committed to making the model useful for coders and non-experts alike through no-code applications. We are actively working on building use case examples and creating code wrappers that make the model as easy to use as possible. Examples are biomass estimation, finding aquaculture locations, or mapping land cover classes. In collaboration with Ode, Clay is also developing a first-class web application that exposes the power of the model in an intuitive no-code application.
If you are interested in talking about how Clay can have an impact on your work, feel free to contact us.
Have a challenging project that could use our help?
Let's connect
We'd love to hear from you.