
Going Small with Efficient Models for Large Problems
- Estimated
- 7 min read


We built Gazet, an intelligent geocoder powered by a small, fine-tuned model. It can run on a 1 core 1 gb CPU machine, uses open data, and is fully deployable without the cost or constraints of large model APIs.

Building and deploying generative AI systems is still harder than it looks, especially if you want to do it openly. Even when these systems work well, they are often expensive to run and difficult to share at scale.
That tradeoff shows up quickly in geospatial workflows, where many problems are structured and repeatable. Large models can handle these tasks, but they often introduce unnecessary cost, energy consumption, and complexity.
Gazet is our attempt to take a different approach: a lightweight geocoding service that uses a small, fine-tuned model to turn natural language queries into usable geometries.

Small models are all we need
Cost and lack of transparency can be blockers in real-world applications. We have created around a dozen agentic systems for our partners, but most were never released openly. The primary reason was the high costs these systems might incur if used by a large user base.
This is changing with the advent of powerful, small, and open models. Over the past year, small open models have become more capable and increasingly interesting alternatives to the frontier model class. One prominent example is gpt-oss-20b, which was released in August 2025 and delivers results similar to OpenAI’s o3-mini on common benchmarks. That is just one of many examples; there is a whole series of very performant open models for different purposes, such as the recent qwen-3.5 model family that includes coding models and has different sizes available.
For geospatial workflows, this matters. Many problems - like geocoding, feature selection, or spatial filtering - follow predictable patterns. They don’t require a language model with world knowledge embedded in them; a smaller model, paired with the right structure and data, can often do the job just as well.
Model size also directly translates into energy use, a recent study shows that a jump from 8B to 32B results in a 5 fold increase in energy consumption, and goes up to a striking 1000x increase in energy use when going to large 480B model versions. These numbers depends on the model architecture and inference technique, but similar trends apply across the major model families.
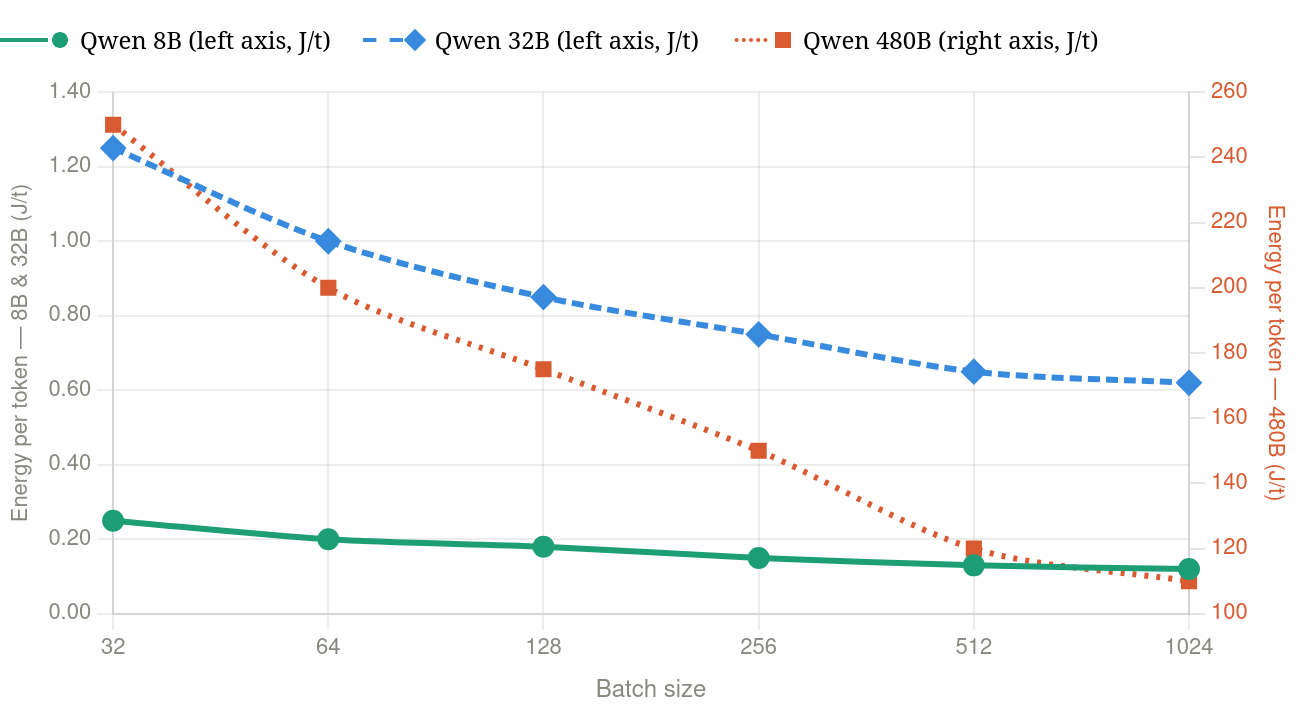
Comparison of total energy per token for Qwen 8B, 32B, and 480B models at varying batch sizes - values extracted from TokenPowerBench. Qwen 480B plotted at differnt scale on the right axis.
Building Gazet
We chose geocoding as our use case because it is a well-defined problem with clear inputs and outputs, but still benefits from natural language interaction. We had explored this before with Geodini, which relied on large language models. This time we wanted to see how far we could get with a smaller, open alternative. What we came up with was Gazet: a streamlined geocoding service powered by a fine-tuned model with fewer than 1B parameters. It uses open data from Overture and Natural Earth, stored in cloud-optimized geoparquet, and runs entirely without a traditional database.
That combination makes the system easier to deploy, easier to reproduce, and easier to share. It can be packaged as a single Docker container and run on a CPU, which opens up new possibilities for making these kinds of tools accessible in practice.
How Gazet Works
Gazet turns a natural-language query into geometry that can be used for analysis or visualization. It supports both standard lookups and more flexible queries, like: “districts along the Ganges” or “1 km buffer along the border of Texas and Louisiana”.
At a high level, the system follows a simple pipeline:
- Extract place names from the query, including locations, natural features, and regions
- Search for candidates using fuzzy matching against Overture divisions and Natural Earth Data
- Build an in-memory dataset of those candidates using DuckDB
- Generate spatial SQL with the model to compute the requested geometry
- Return the result as a valid geometry
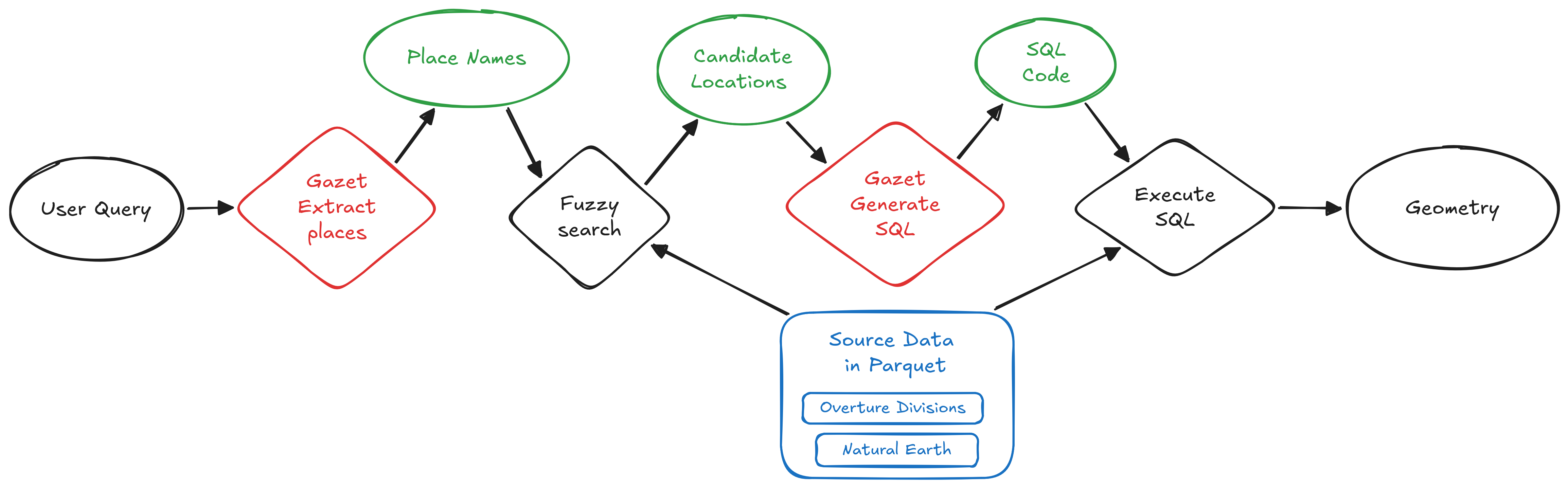
For example, a query like “the northern half of India” is translated into SQL that computes the corresponding polygon.
This approach does not guarantee that the first result is exactly what the user expects. But it does ensure that the output is always a valid geometry that can be inspected, visualized, and refined.
Importantly, the system runs without a standalone database like PostgreSQL or MySQL. Everything happens in memory, using open data and a small model. The entire service can be packaged into a ~4GB Docker image and deployed on a CPU, with the option to use a small GPU to further reduce latency.
Building the Training Dataset
The task is to take a query such as “give me the northern half of India” and generate spatial SQL that returns GeoJSON.
We tried the obvious approach - using an LLM to generate query-SQL pairs, then distill - but ran into issues pretty quickly. Every query is an API call, which means scaling costs real money, and diversity ends up bounded by your prompts. So we explored a different approach - instead of natural language to SQL via an LLM, we went with structured geography - SQL - natural language, using templates.
From Overture Divisions and Natural Earth data, we precompute a graph of which places touch, contain, or intersect each other. Around 70 SQL templates (lookups, adjacency, containment, buffers, set operations, and so on) get filled against this graph. Once the SQL and anchors are set, writing the matching natural-language question is fairly straightforward - no LLM needed. Every generated query runs against DuckDB, anything returning empty gets discarded. We ran this on Modal with around 100 workers. We generated 70k validated training pairs in roughly 1 hour for around $5.
The resulting training dataset can be downloaded from huggingface.
Fine-tuning the Models
We wanted sub-1B parameters, runnable on CPU. We trained Gemma 3 270M and Qwen 3.5 0.8B with Unsloth, LoRA, two epochs on a single A100. Total cost including data generation came to around $15.
Both models picked up SQL fairly quickly. The main difference was in geographic knowledge. Gemma sometimes picked the wrong "Paris"; Qwen's richer pretraining prior tended to choose the major feature more reliably. That's not really about the finetune though - a small LoRA doesn't add world knowledge that isn't already there.
We went with Qwen 3.5 0.8B. The finetune grounds the model rather than teaches it - the base model already knew SQL and spatial functions, we just anchored it to our schema. After quantizing to Q8 with llama.cpp (around 800 MB), we serve it locally via llama-server. We get under 10 ms/token on a Mac, with no data leaving the machine.
You can find the model weights on huggingface.
Next Steps
Gazet today is a small, focused model that does one thing well: turn a natural-language query into spatial SQL that returns a geometry. A few directions we want to explore from here:
- Add self-correction through an execution-feedback loop so the model can revise failed queries
- Improve candidate selection by replacing Jaro-Winkler with a small BERT style embedding model
- Expand template coverage for underrepresented multi-hop queries - scaling mainly requires writing more templates, not increasing spend
- Add tool use through a CodeAct-style loop for queries that require intermediate steps
The broader point is that an 500 MB model that runs on a laptop is a surprisingly good foundation. Most of the improvements we want from here are not "make the model bigger", they are "give the model a little more structure around it and better training pairs".
Join Us in Exploring This
For many geospatial workflows, the question isn’t how to use larger models, it’s how to use the right-sized ones. With the right structure and data, smaller models can be easier to deploy, easier to share, and more practical to use.
We think there are many more geospatial use cases where this approach could work.
If you have a workflow that feels like it shouldn’t require a large model, we’d encourage you to try it or reach out. We’re interested in collaborating on similar problems.
What we're doing.
Latest