


Most cloud-native Earth data platforms rely on powerful infrastructure to deliver metadata search at scale. We are exploring how to make geospatial metadata more portable, efficient, and cost-effective by combining the flexibility of STAC with the lightweight power of GeoParquet.

Not every geospatial project needs a planetary-scale database.
We’ve helped build and scale powerful STAC-based systems (like NASA’s VEDA) that index hundreds of millions of assets. But we’ve also seen a growing need for something leaner. Teams often don’t want to spin up managed databases or maintain complex backends just to enable metadata search.
What if there were a simpler way to store, query, and serve STAC metadata using modern, open formats that work at rest (stored as static files rather than in a database), in the cloud, and even on your laptop?
That’s the goal behind stac-geoparquet: a lightweight approach to Cloud-Native Geospatial metadata. It’s cost-effective, server-optional, and built for fast iteration, especially in workflows where traditional infrastructure is overkill.
STAC at Scale...and STAC at Small Scale
The SpatioTemporal Asset Catalog (STAC) specification has become the standard for describing geospatial data, and for good reason. Built on familiar formats like GeoJSON and OGC standards, it powers massive catalogs like Microsoft’s Planetary Computer and AWS Earth Search, which rely on robust database-backed APIs like pgstac or OpenSearch to query millions of assets.
But what if your catalog has only has a few thousand items, or you don't want to manage a large database? For smaller teams or lightweight workflows, setting up and maintaining a full backend can feel like using a sledgehammer to crack a walnut.
- Managed databases add cost and complexity.
- Local development setups can be cumbersome.
- The stack often doesn't match the scale.
We wanted something simpler but still STAC-compatible.
Querying Metadata Where It Lives
To simplify metadata workflows, we’ve been exploring a lightweight pattern: converting STAC catalogs into GeoParquet — a columnar, cloud-native format that’s efficient to store and easy to query.
Why GeoParquet? Because it works at rest with modern data tools. You can use engines like DuckDB, which supports spatial extensions, to query a GeoParquet file directly from local or remote storage:
D install spatial;
D load spatial;
D select * from read_parquet('s3://stac-fastapi-geoparquet-labs-375/naip.parquet')
where st_intersects(geometry, st_geomfromgeojson('{"type":"Point","coordinates":[-105.1019,40.1672]}'));
┌─────────┬──────────────┬──────────────────────┬──────────────────────┬───────────────┬───┬───────────┬──────────────────────┬───────────┬──────────────────────┬──────────────────────┬──────────────────────┐
│ type │ stac_version │ stac_extensions │ id │ proj:shape │ … │ naip:year │ proj:bbox │ proj:epsg │ providers │ bbox │ geometry │
│ varchar │ varchar │ varchar[] │ varchar │ int64[] │ │ varchar │ double[] │ int64 │ struct(url varchar… │ struct(xmin double… │ geometry │
├─────────┼──────────────┼──────────────────────┼──────────────────────┼───────────────┼───┼───────────┼──────────────────────┼───────────┼──────────────────────┼──────────────────────┼──────────────────────┤
│ Feature │ 1.1.0 │ [https://stac-exte… │ co_m_4010556_sw_13… │ [12240, 9550] │ … │ 2021 │ [489150.0, 4441434… │ 26913 │ [{'url': https://w… │ {'xmin': -105.1274… │ POLYGON ((-105.060… │
├─────────┴──────────────┴──────────────────────┴──────────────────────┴───────────────┴───┴───────────┴──────────────────────┴───────────┴──────────────────────┴──────────────────────┴──────────────────────┤
│ 1 rows 19 columns (11 shown) │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘This illustrates the power of storing STAC metadata in open, interoperable formats. The metadata becomes portable, queryable, and accessible using tools you may already use in your analysis stack.
Stac-geoparquet In Action
To bridge the gap between STAC and GeoParquet, we're continuing to develop stac-geoparquet, a specification and toolkit that converts STAC Items into GeoParquet files while preserving fields and metadata structure. Originally prototyped by Tom Augspurger using GeoPandas, the library has matured to support performant I/O, alternative storage formats like Delta Lake, and more direct bindings via Rust libraries (like geoarrow-rs).
And to make this even more accessible, we built a prototype STAC API server
stac-fastapi-geoparquet is a lightweight FastAPI wrapper that serves GeoParquet metadata through a STAC API interface. That means existing clients like pystac-client or stac-browser can query and explore the data as if it were coming from a traditional STAC backend but without the infrastructure.
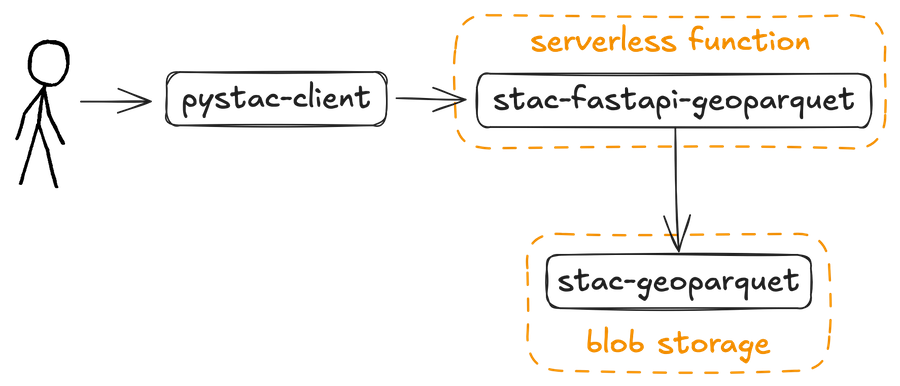
Accessing stac-geoparquet data through a lightweight STAC API server.
Benchmarks
We benchmarked stac-fastapi-geoparquet against stac-fastapi-pgstac using the same NAIP dataset. Here’s what we found:
- For small to medium catalogs (under ~100,000 items), stac-fastapi-geoparquet performs better for broad, paginated queries and lightweight faceted search, especially when cost and simplicity matter.
- For targeted queries (e.g., finding a single item by ID), traditional databases like pgstac still shine. Indexing and query planning make them faster for “needle-in-a-haystack” lookups.
💡 The Takeaway: GeoParquet works well for serverless and low-infrastructure environments. Databases still play an important role for highly specific querying at scale. A system based on stac-geoparquet will likely be lower-maintenance than one based on a database.
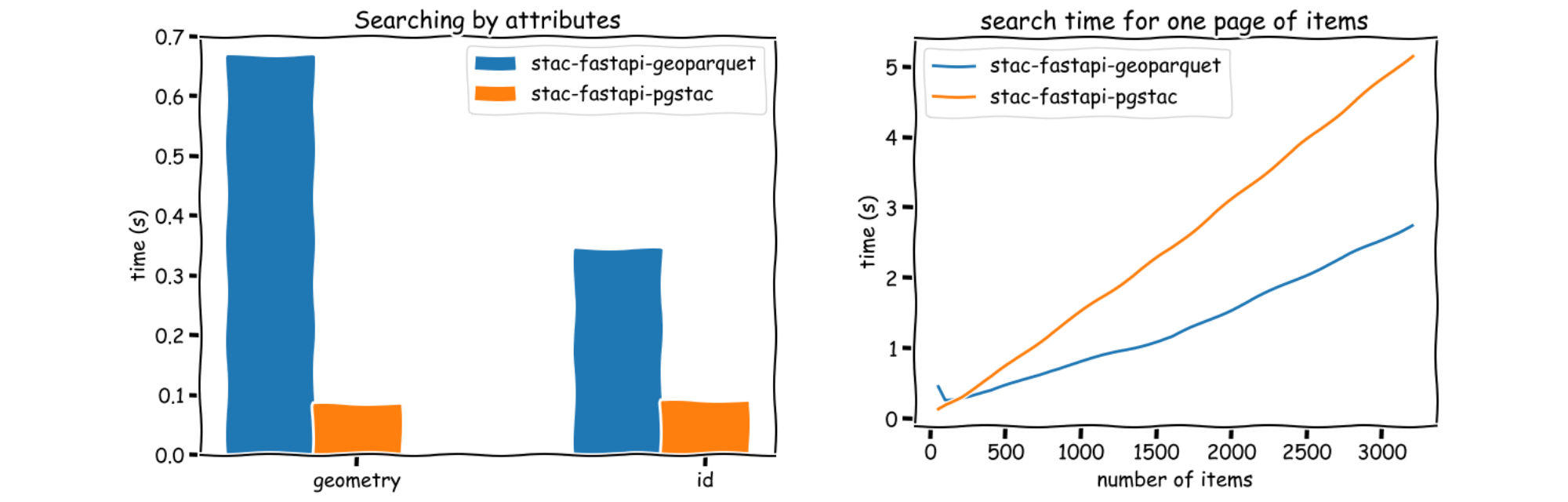
Left: Benchmarking attribute-based STAC searches (geometry and ID) using different backends. Right: stac-fastapi-geoparquet can serve large pages of items faster than stac-fastapi-pgstac
Serverless Search with rustac
Don’t want to run a server at all? That’s where rustac comes in — a Rust- and Python-compatible client for querying STAC metadata.
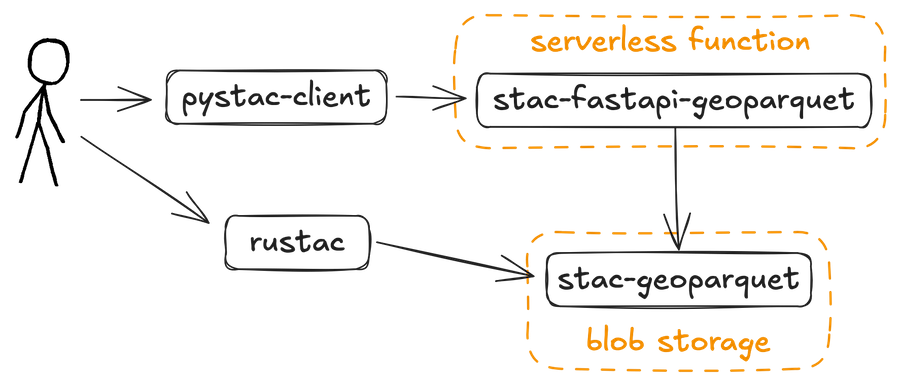
Two user access paths to STAC GeoParquet data. One uses pystac-client through a serverless stac-fastapi-geoparquet API; the other uses rustac for direct, lightweight reads from blob storage.
Under the hood, rustac uses DuckDB to perform fast, in-memory queries against GeoParquet files using familiar STAC parameters like intersects and datetime. For example:
from rustac import DuckdbClient
client = DuckdbClient()
# Configure AWS credentials
client.execute("CREATE SECRET (TYPE S3, PROVIDER CREDENTIAL_CHAIN)")
items = client.search(
"s3://stac-fastapi-geoparquet-labs-375/naip.parquet",
intersects={"type": "Point", "coordinates": [-105.1019, 40.1672]},
)With this approach, you can filter and fetch metadata with no backend at all — just files, formats, and open tools.
What’s Next? Try It Out
We’re continuing to test and refine this approach, and we’d love your feedback. If you’re working with small to medium-sized STAC catalogs and want to simplify your infrastructure, give stac-geoparquet and rustac a try.
- Explore the stac-fastapi-geoparquet labs repository and our Cloud-Native Geospatial slides
- Check out stac-geoparquet on GitHub
- Get in touch to tell us about your use case
What we're doing.
Latest