


The availability of large volumes of Earth observation data is at an all-time high.
Deciphering these datasets is critical to understanding the planet, and advancing cloud-native data standards and formats is key to transforming the geospatial industry. For example, data producers like NASA are embracing cloud-native, underscoring a broader shift in how the science community thinks about big geospatial data. Satellite missions, like NISAR and SWOT, are expected to produce around ~85 TB of data daily. To meet the needs of the climate and conservation grand challenges, we need to build more efficient tools faster than ever before.
Combining Cloud-native and GPU-native
Traditional machine learning pipelines face bottlenecks when moving data from cloud storage to GPUs for training. Every second spent doing data pre-processing on the CPU or doing costly CPU-to-GPU data transfers means wasted idle time on the GPU. As we start training models on petabyte-scale datasets, a paradigm shift is required, not only on the technical side regarding data storage and high-performance compute but also on how people collaborate on building next-generation tools for open science.
We can drastically improve performance by leveraging modern tools and processes in three steps:
- Using accelerated GPU-native compute
- Streaming data subsets on-demand
- Handling complex multi-modal data inputs
Let’s now take a look at how to implement each of these approaches using modern tools developed within the Pangeo Community.
We need to build more efficient tools faster than ever before.
Using accelerated GPU-native compute
NVIDIA GPUDirect Storage is a technology that accelerates data movement from storage to GPU memory, bypassing transfer over CPU RAM.
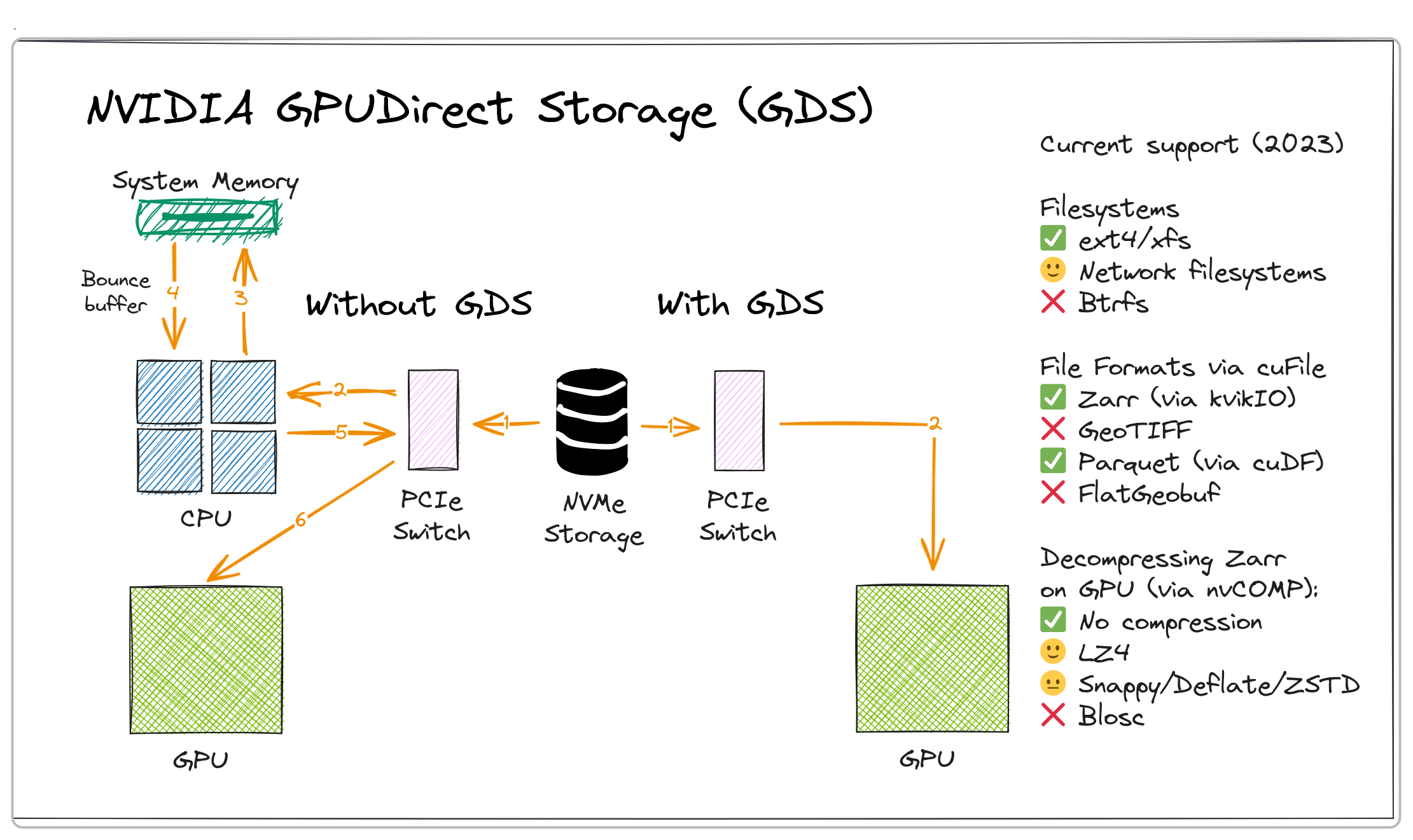
Figure 1: NVIDIA GPUDirect Storage (GDS). Source: Wei Ji Leong, FOSS4G 2023 Oceania
GPU-accelerated RAPIDS AI libraries can leverage GPUDirectStorage for high-performance I/O. Parquet (via cuDF) and Zarr (via kvikIO) are the best supported cloud-optimized geospatial file formats. For Zarr, kvikIO supports GPU-accelerated decompression of LZ4-compressed datasets via nvCOMP. Additionally, cupy-xarray offers an experimental kvikIO interface for seamlessly reading Zarr data into GPU-backed xarray datasets.
Streaming data subsets on-demand
Using GPU-native storage methods allows us to read data faster, but this means the GPU memory will soon limit us — there’s no way we can fit all the datasets into memory at once. A common approach is to subset the datasets into smaller 'chips' that are stored as intermediate files before loading them into memory. This, however, results in duplicated data, and when you're working on the terabyte or petabyte scale, it can quickly become cumbersome to store and manage all of those intermediate files.
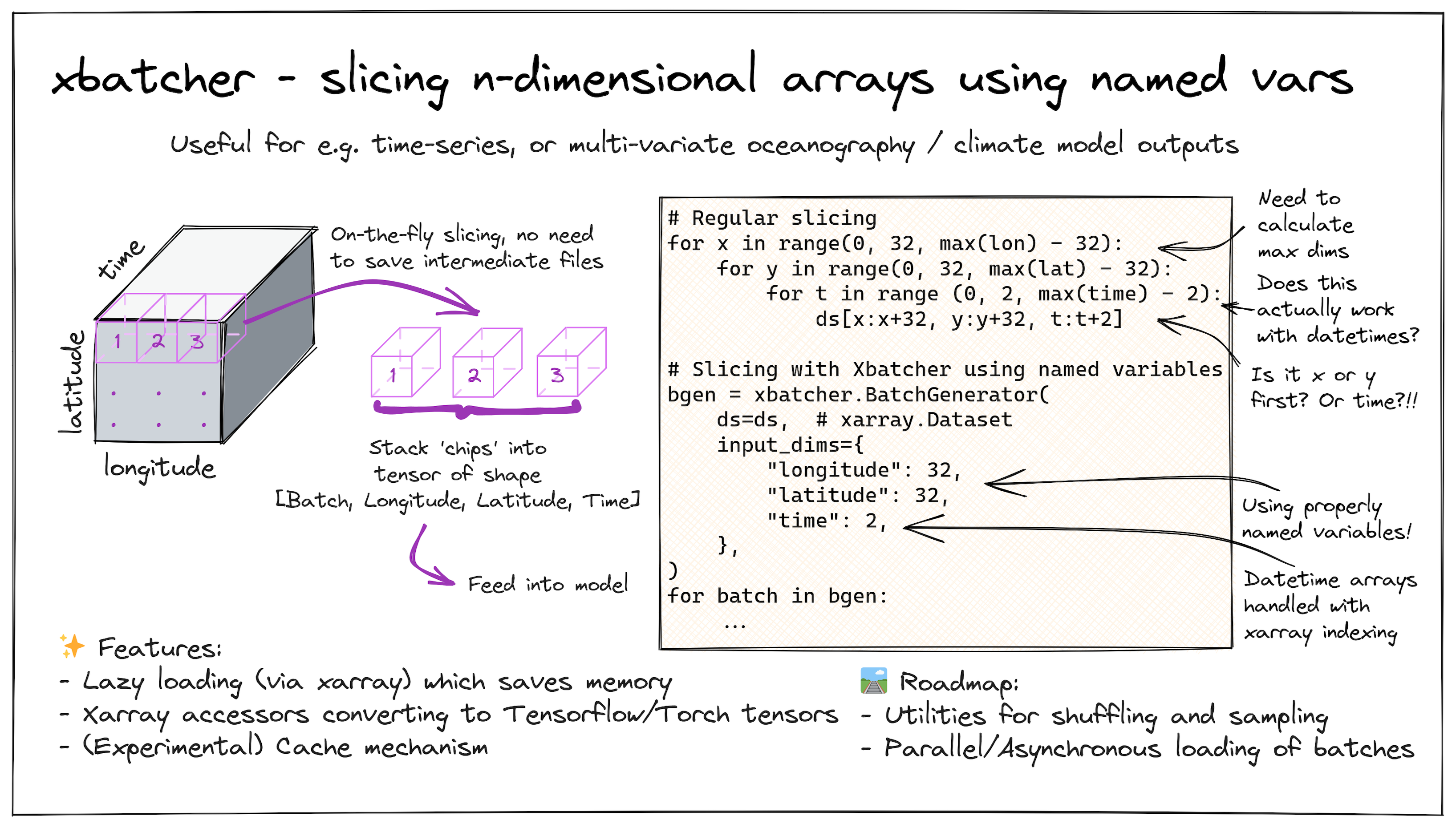
Figure 2: xbatcher - slicing n-dimensional arrays using named variables. Illustration and code sample. Source: Wei Ji Leong, FOSS4G 2023 Oceania
A key benefit of cloud-optimized data formats is that they allow chunks of data to be accessed quickly. Libraries like xbatcher allow us to slice datacubes intuitively along any dimension using named variables. xbatcher uses xarray's lazy-loading mechanism behind the scenes to save memory. The interface remains the same since the Xarray data model doesn't care if the underlying data is a CPU or GPU-backed array.
Modularizing data inputs to combine multiple sources
We are actively developing Foundational Machine Learning models based on Earth observation datasets. These models use large volumes of raster, vector, and point cloud datasets. For example, our work with NASA and Clay involves using datasets like Sentinel-2 optical imagery, Sentinel-1 PolSAR data, and Copernicus DEMs. Regardless of Composable Data Systems or Modular Deep Learning, the core idea is to build components that are plug-and-play.
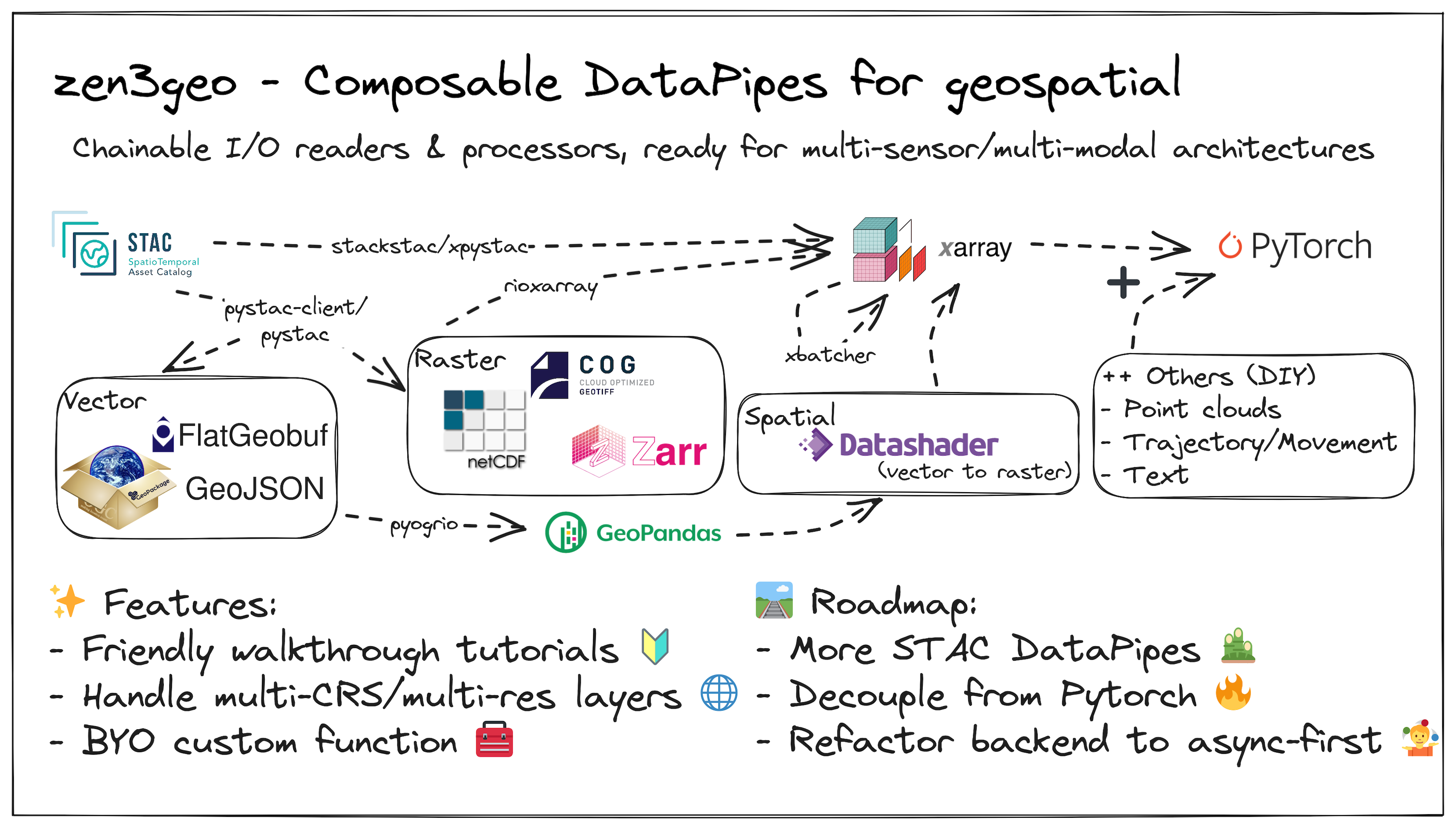
Figure 3: zen3geo's chainable I/O readers and processors for geospatial data. Source: Wei Ji Leong, FOSS4G 2023 Oceania
zen3geo is a library designed to allow for building custom multi-sensor or multi-modal data pipelines. It implements readers for standards such as Spatiotemporal Asset Catalogs (STAC), which can include raster or vector datasets. It also allows you to do data conversions (e.g., rasterization) or apply any custom processing function. Behind the scenes, zen3geo makes extensive use of the geopandas GeoDataFrame and Xarray data model and depends on torchdata DataPipes to chain operations together in a composable manner.
Putting it all together
Here’s an example that showcases the efficiency of a GPU-native data pipeline using zen3geo with an ERA5 dataset from WeatherBench2. This pipeline, depicted in Figure 4, showcases the flow from data retrieval to model training:
- Initiate with a URL to an ERA5 Zarr store.
- Read the data efficiently using kvikIO.
- Pre-process through a custom function for selecting specific variables like wind speed.
- Slice the data into manageable subsets with xbatcher.
- Zero-copy conversion of CuPy arrays into Torch tensors.
- Load into a Pytorch DataLoader for direct streaming to neural networks.

{kind=link}
Figure 4: The zen3geo DataPipe. Starting with a url to an ERA5 Zarr store, custom pre-processing function, sliced into subsets using xbatcher, converted from CuPy arrays into Torch tensors, and finally passed into a DataLoader. Source: Wei Ji Leong, FOSS4G 2023 Oceania
This approach not only simplifies but significantly accelerates the data handling process. Benchmarks reveal that using the GPU-accelerated kvikIO engine to load an 18.2GB ERA5 dataset is approximately 25% faster than the CPU-based method Zarr engine, cutting the load time from 16.0 seconds to 11.9 seconds.
Moving Forward
Climate and conservation challenges call for efficient and scalable tools and pipelines to harness this data. Encouragingly, efforts like the open Pangeo community and organizations, including Earthmover, CarbonPlan, and NCAR, are tackling these big data challenges head-on.
If you are designing an ML pipeline at comparable scales, consider these approaches to take advantage of modern tooling. For more details, see the code and findings in the FOSS4G 2023 Oceania GitHub repository.
What we're doing.
Latest