
Exploring the Potential of the Segment Anything Model
- Estimated
- 5 min read



Segment Anything Model's (SAM) potential impact as a new foundation model for computer vision is exciting, particularly in the geospatial imagery community. With SAM, users can drop a point on objects in satellite imagery and, in many cases, automatically generate great segmentation predictions. This model uses a two-stage prediction approach. First, an encoder converts an image to image features (embeddings). Then, a decoder + encoded prompt converts a user supplied input (point(s), bounding box, or text) into segmentation masks that delineate the boundary of an object or objects (Figure 1). In our initial explorations, SAM is more robust and has better domain adaptability than Imagenet or COCO pre-trained weights out of the box. What's more, SAM can be adapted on the fly for particular detection problems through user prompting! With prompting, as a user supplies inputs that relate to objects of interest, the model adapts to get better at generating segments for the problem at hand.
Computer vision - the ability for computers to extract high dimensional data from the visual world and produce symbolic summaries for decision making - has taken huge strides toward automated image segmentation in recent years. Regional convolutional neural network based approaches like Mask R-CNN demonstrated state of the art segmentation performance and speed, allowing for segmentation models to run at frame rate speeds and process large archives of imagery with great accuracy faster than ever before. Since then, benchmark performance of newer supervised segmentation models on traditional photography datasets like Common Objects in Context (COCO) has advanced rapidly, yet it has remained difficult to adapt these models to new problems in foreign image domains, especially satellite imagery! But today there's an exciting new model that could pave the way for easily tunable image segmentation on domain specific imagery: Segment Anything, released by Facebook AI Research.
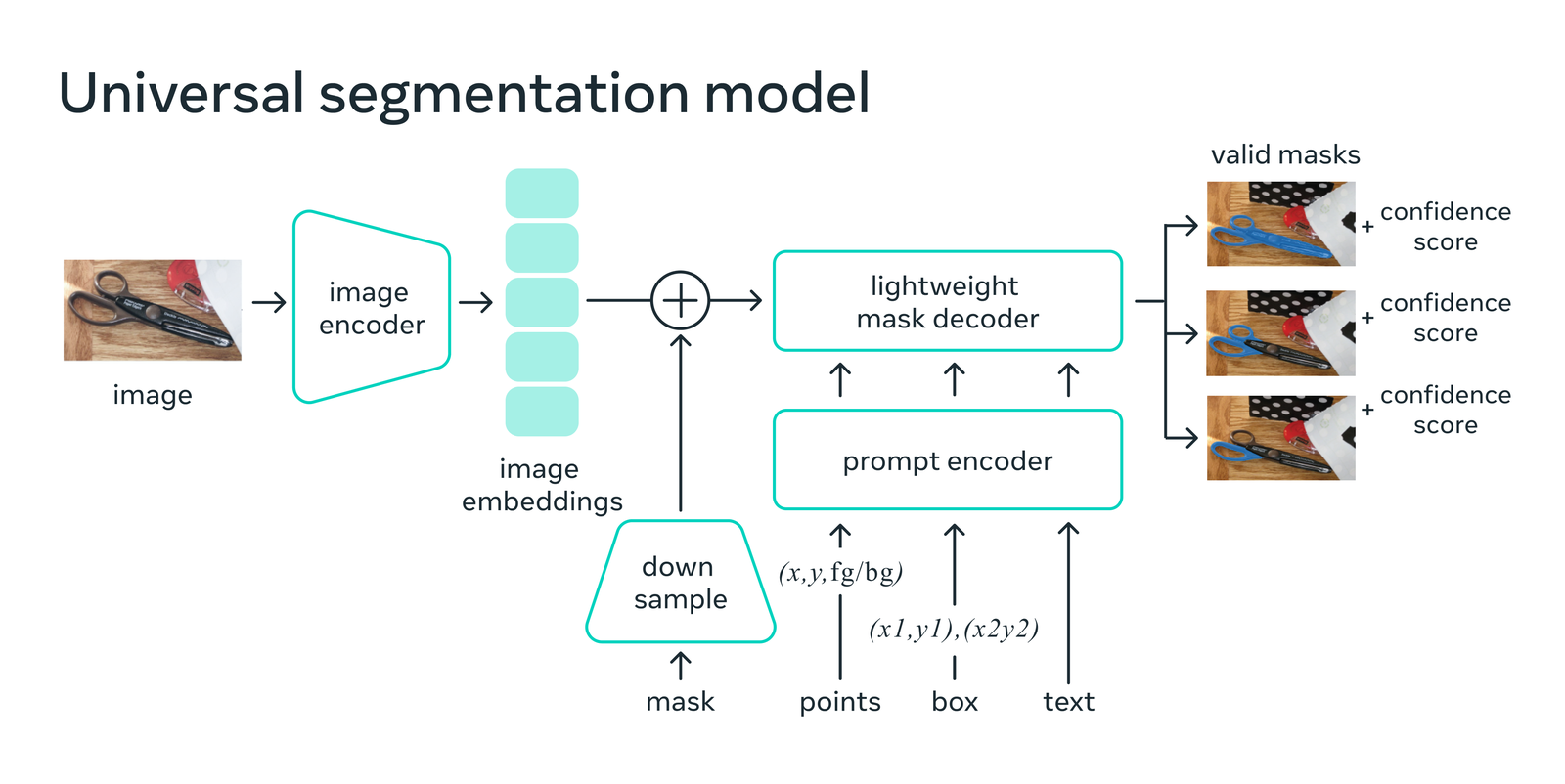
Figure 1: SAM - A Universal Segmentation Model. Source.
In our first week with SAM, we were eager to explore its capabilities and test its performance on satellite images. To do this, we decided to build simple streamlit apps to allow us to analyze satellite images and assess how SAM could assist us as a data annotation tool.
Fig 2. Running SAM on different satellite imagery & brand combinations from planetary-computer.
Fig 3. SAM as a data annotation tool
Looking into the future of what is possible with SAM, there are some exciting directions that SAM could take for annotation, which we are experimenting with in our projects. PEARL + SAM, for example, could enable more accessible annotation, fine-tuning, and retraining of SAM models. DS_Annotate or Label Studio + SAM could facilitate model-assisted annotations without retraining. It's worth noting, however, that retraining may still be helpful in cases with complex land use and land cover features but less so in simple oil slick detection, for example.
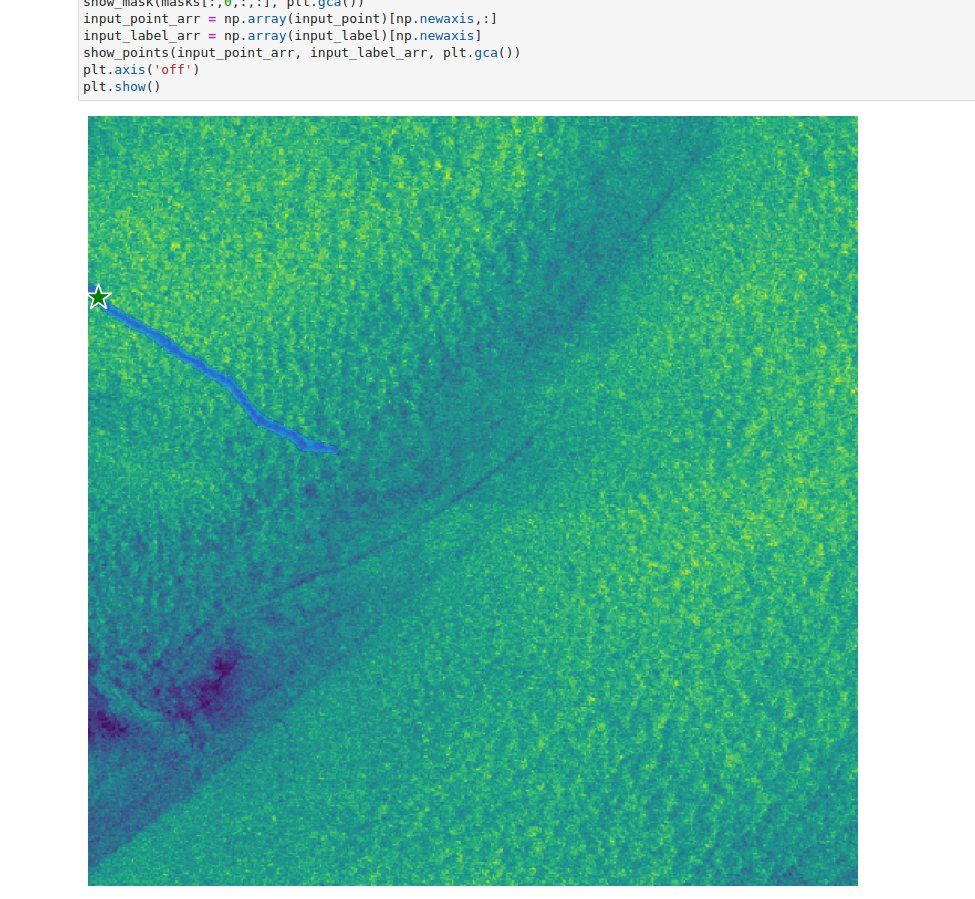
Figure 4: An oil slick that is perfectly segmented from a single input prompt. This is a game changer for fast data annotation and monitoring with satellite imagery!
Trying out the tool for field delineation from #SatelliteImagery, it's not perfect, but it's surprisingly decent.
— Zhuang-Fang NaNa Yi(依庄防) (@geonanayi) April 5, 2023
Gif 1. Fields in India https://t.co/1ZUHWczEBD pic.twitter.com/vL859Us2sy
Fig. 5: Devseed Alum NaNa Yi investigated SAM’s out of the box single point performance on a complex agricultural scene, finding that individual fields are segmented surprisingly well but are sometimes inaccurately grouped together or otherwise missed.
The potential of SAM for use in data annotation and active learning workflows is immense. This could have a massive impact on the computer vision field, and plenty of other commercial tools are already integrating SAM. In the open source world, Napari and the napari-sam plugin are being used for segmenting 2D image slices, and soon SAM support is coming to Label Studio, a general-purpose ML annotation tool. We’ll complement these efforts by open-sourcing SAM support for annotating geospatial imagery.
Soon we hope to share fine-tuned performance on more complex LULC annotations tasks. Additionally, we are excited about the release of Google’s WebGPU, which will significantly improve the breadth of ML models that can be run in the browser and model performance. In the future, this can enable functionality where users with GPUs can run the SAM encoder model on their hardware from the browser, removing the need for a cloud-based, GPU-backed service for the hefty SAM encoder model.
SAM is an impressive tool, but it still has some challenges. For example, the placement of input prompts can greatly alter the result's quality. In the below example, we intentionally misplaced the input point so that it is next to, but not directly on, an oil slick, which produced an incorrect segment:
The potential of SAM for use in data annotation and active learning workflows is immense.
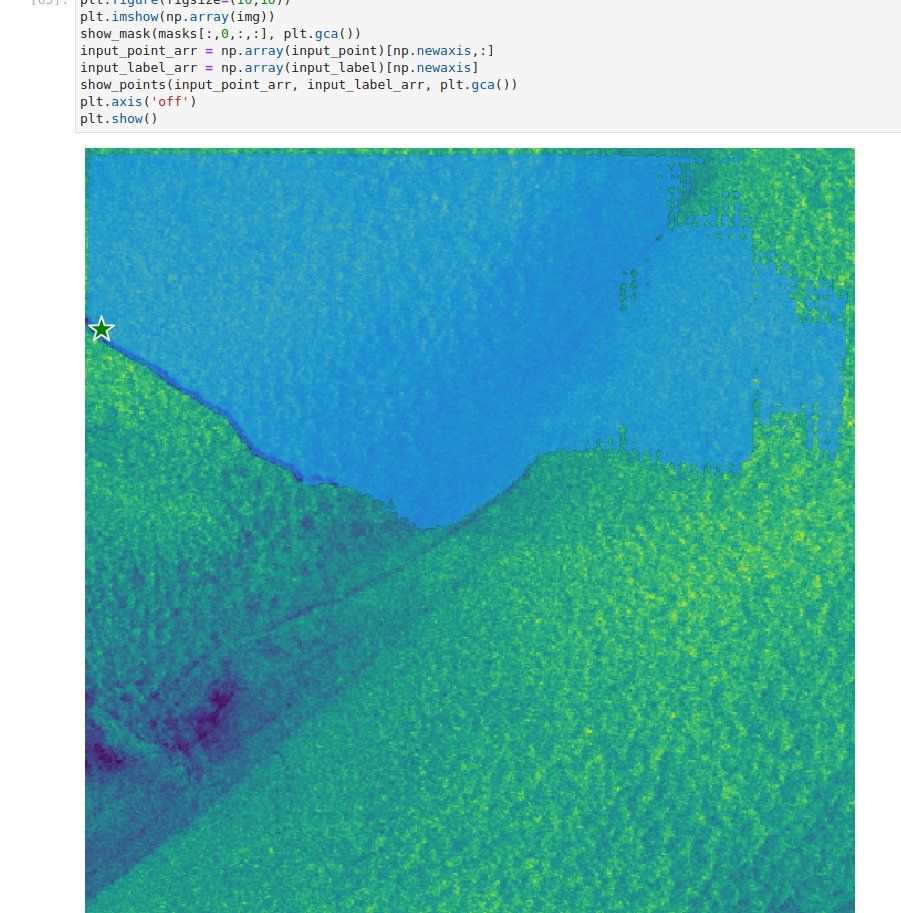
Figure 6: An oil slick that is perfectly segmented from a single input prompt. This is a game changer for fast data annotation and monitoring with satellite imagery!
While SAM is highly effective for object detection and image segmentation tasks, it may be less helpful for more complex functions like 3D object detection. Nevertheless, SAM is being extended to support these use cases, with promising results.
SAM shows promising potential to revolutionize computer vision by enabling zero-shot performance (no prompting) and domain-specific fine-tuning. The integration of SAM into internal tools and ongoing efforts to enhance its capabilities indicate exciting possibilities for geospatial datasets and beyond. With the anticipation of new insights and discoveries, we're excited to see what else we can uncover from our visual data. Stay tuned for updates as we push the boundaries of what's possible with this innovative model!
What we're doing.
Latest