
We used AI to help UNICEF identify unmapped schools across Asia, Africa, and South America

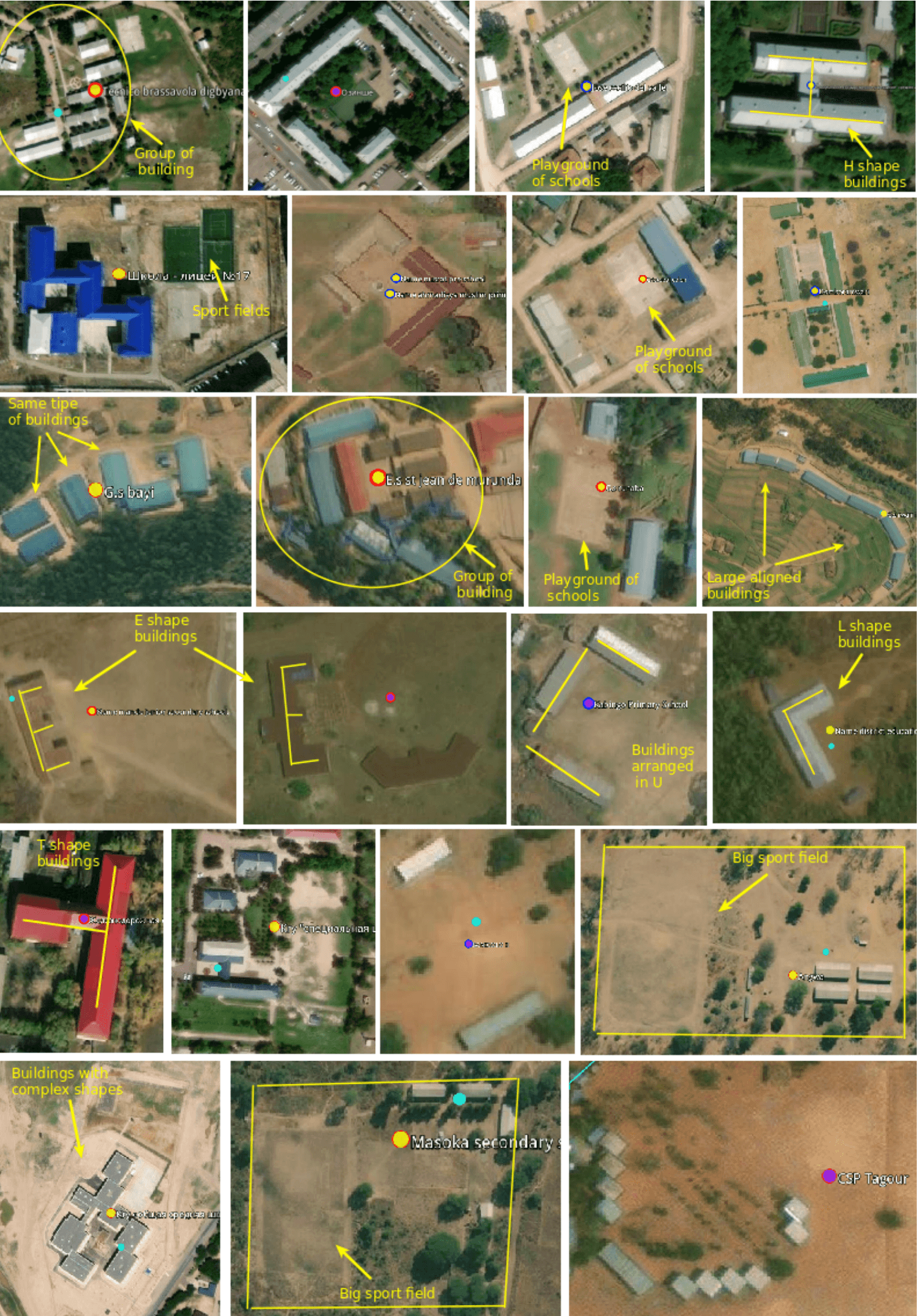
Despite their varied structure, many schools have identifiable overhead signatures that make them possible to detect in high-resolution imagery with modern deep learning techniques.
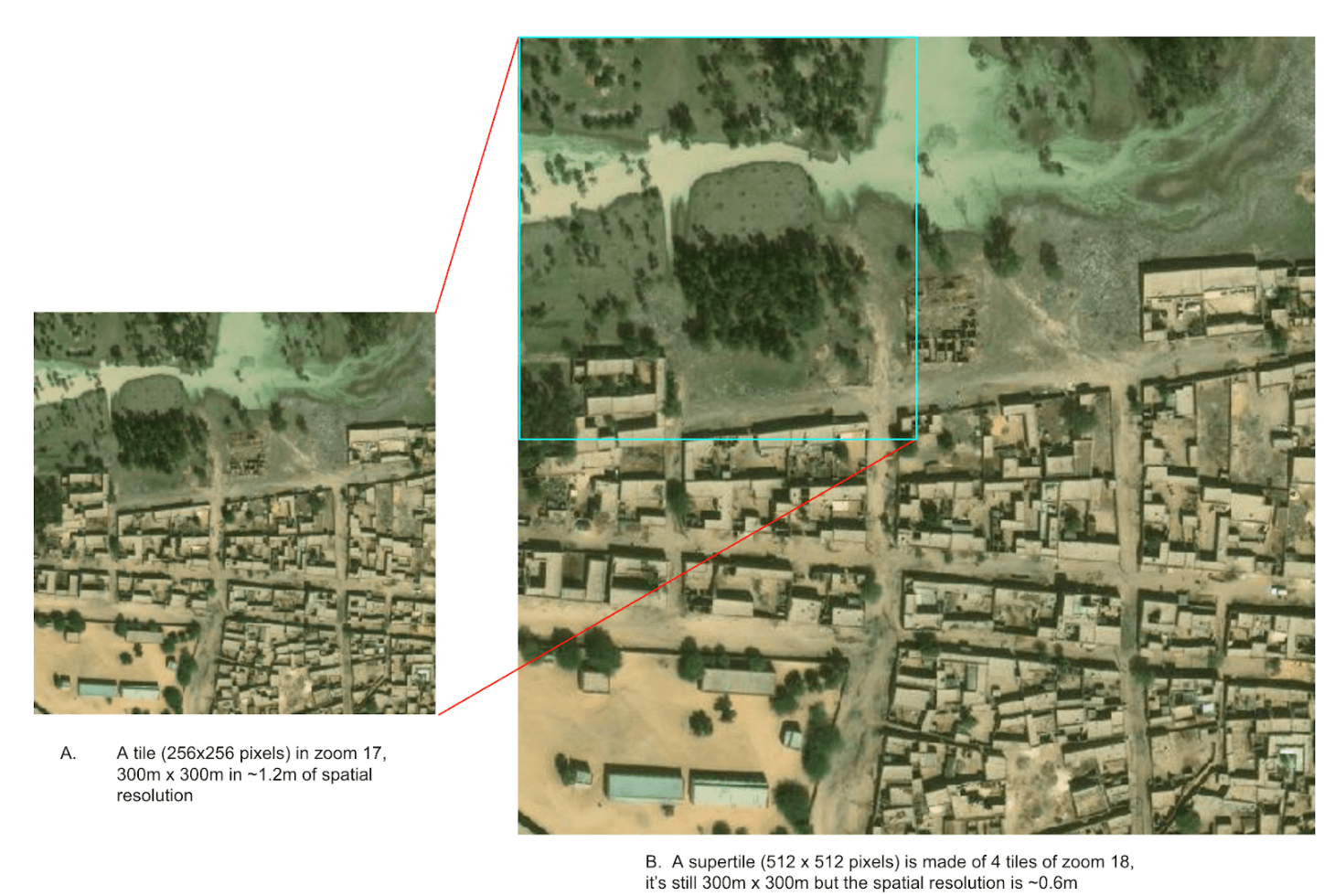
A supertile of zoom 17 (on the left) is made of 4 zoom 18 tiles (on the right). The supertile represents higher spatial resolution and higher image dimension (512x512 pixels) compared to the original 256x256 pixels tile in zoom 17.
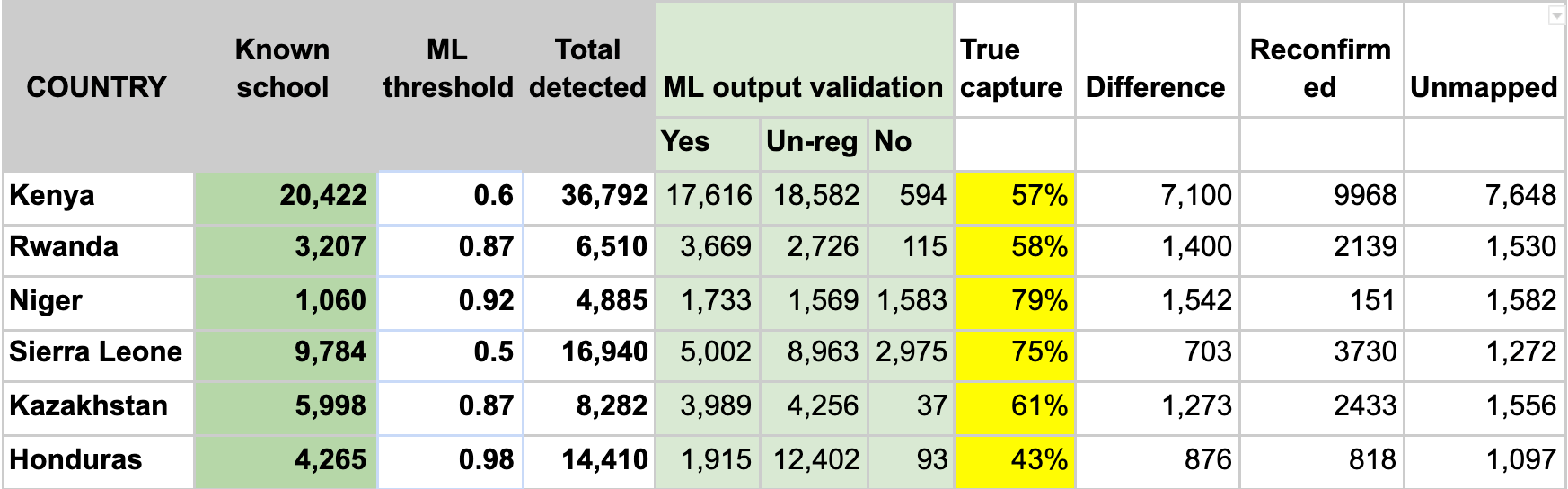
The six country models we trained obtained high F1 scores in test datasets. The models were able to identify already mapped schools up to ~80% depending on the country. At the end of the project, we added 18,000 unmapped/missing schools in Africa, 4,000 to Asia, and more than 1,100 in Honduras.
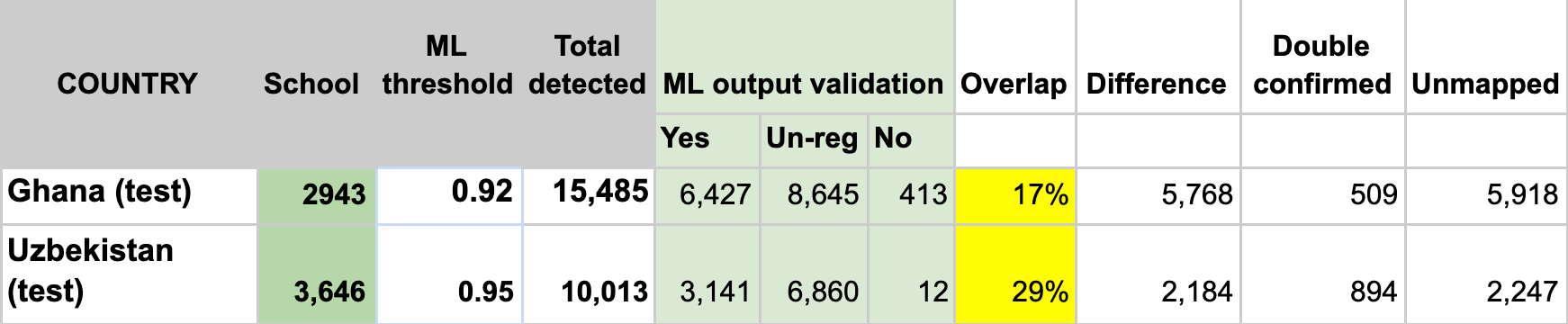
The two test countries, Ghana and Uzbekistan don’t have their own country model trained. We ran model inference in Ghana with the West African regional model that trained with Niger and Sierra Leone and applied the Kazakhstan country model to Uzbekistan. Even though the ML confidence scores were high to filter the ‘predicted’ schools tiles for both countries (see ML threshold column), we were able to identify a fair amount of double confirmed and unmapped schools in both countries. The high ML threshold scores indicate a lower false-negative rate, but we may also potentially miss a lot of true schools.
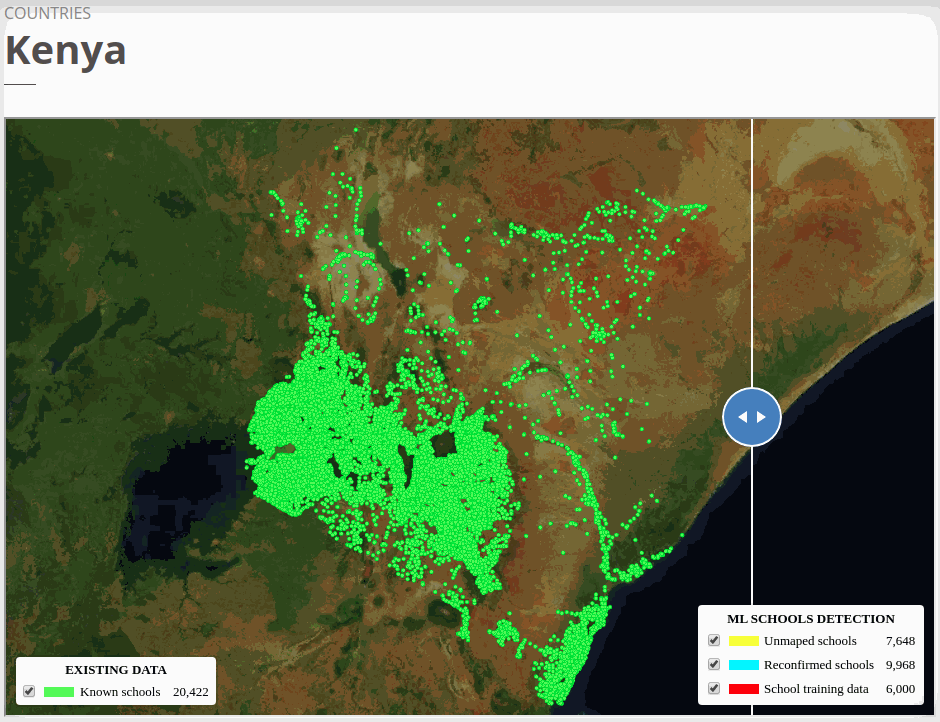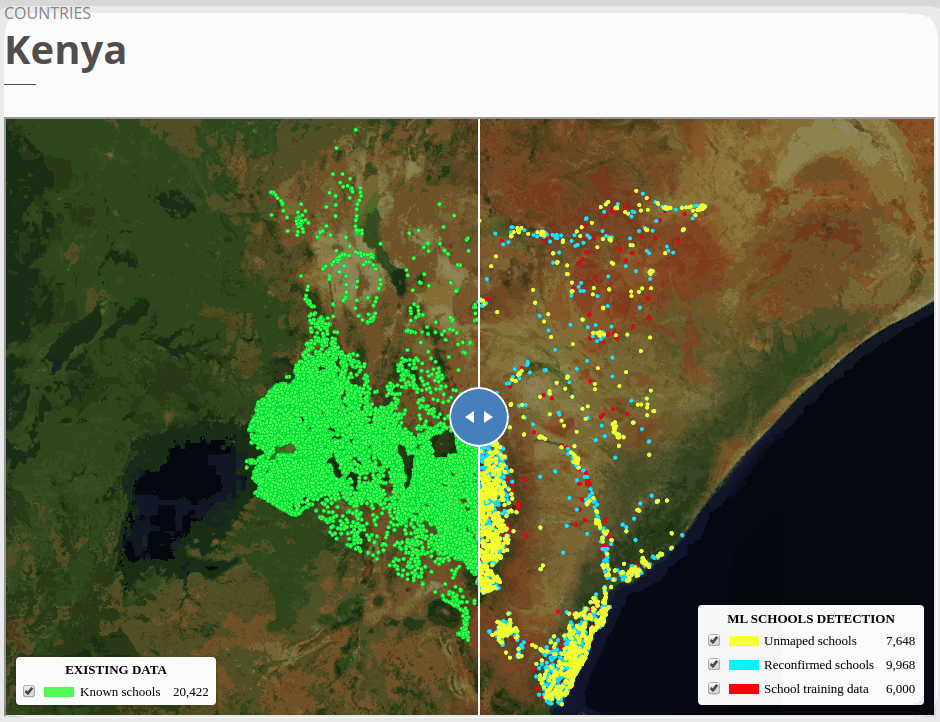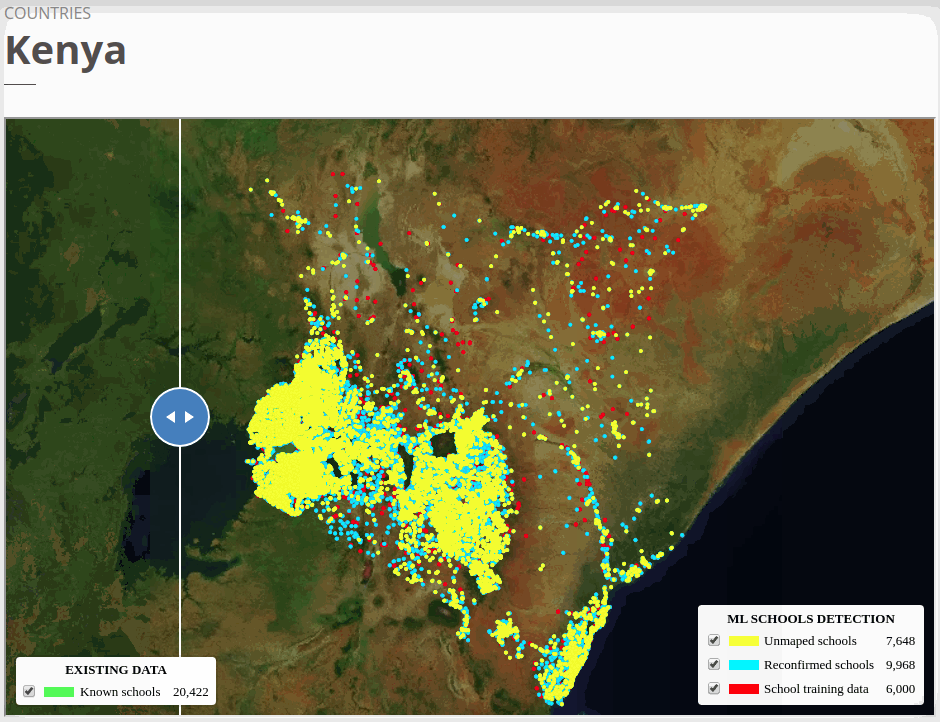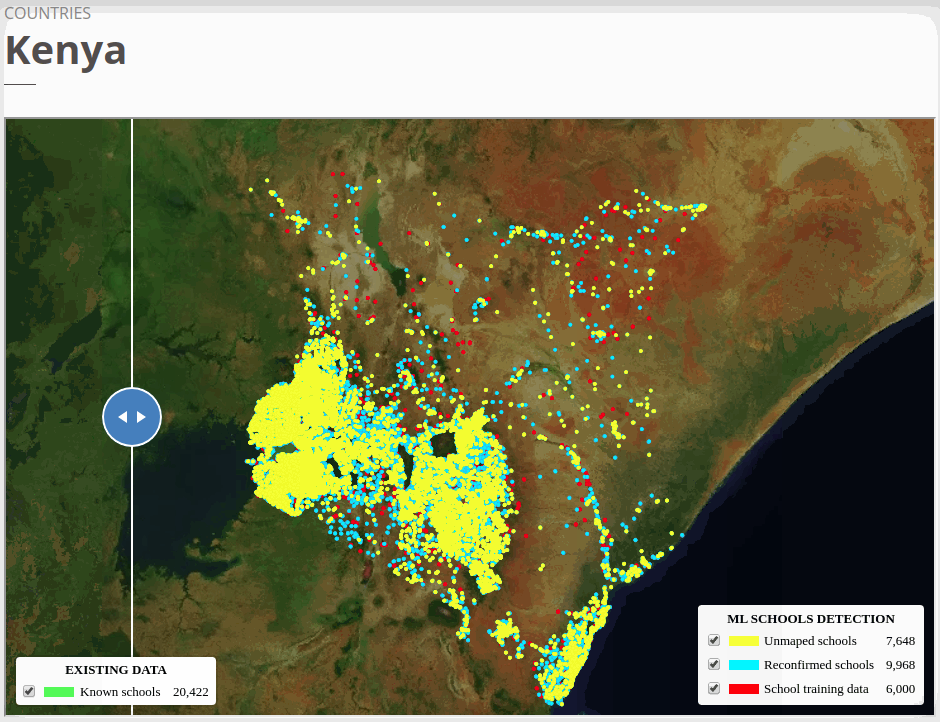
To view the online school map for Kenya, please go to the Kenya school map viewer. Basemap by © Mapbox.
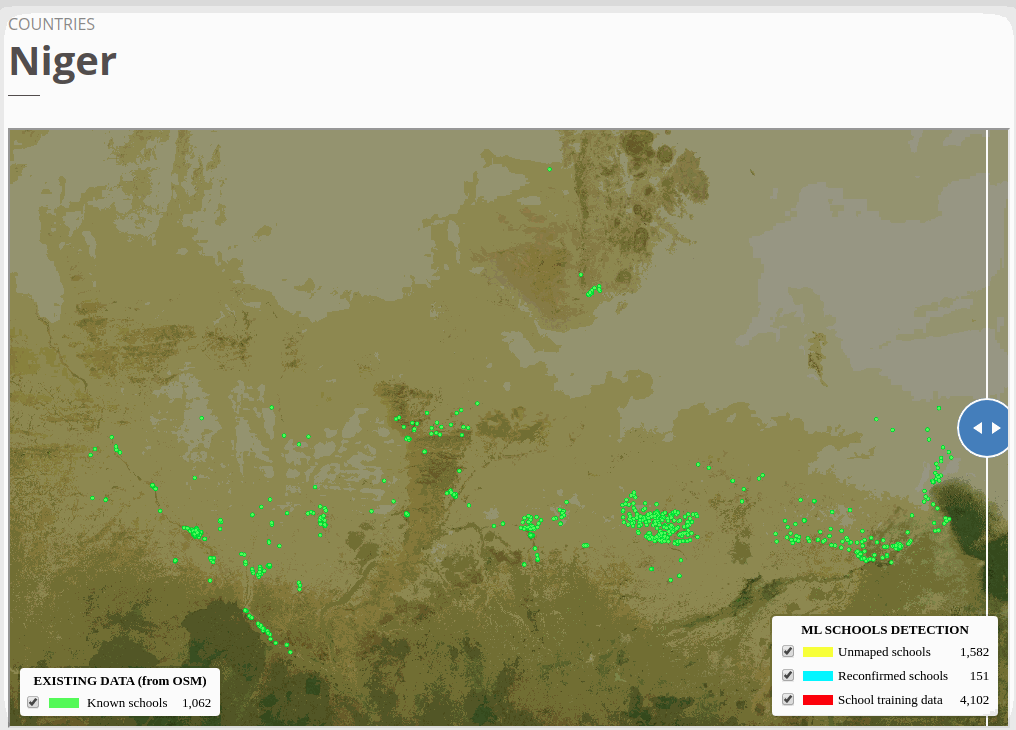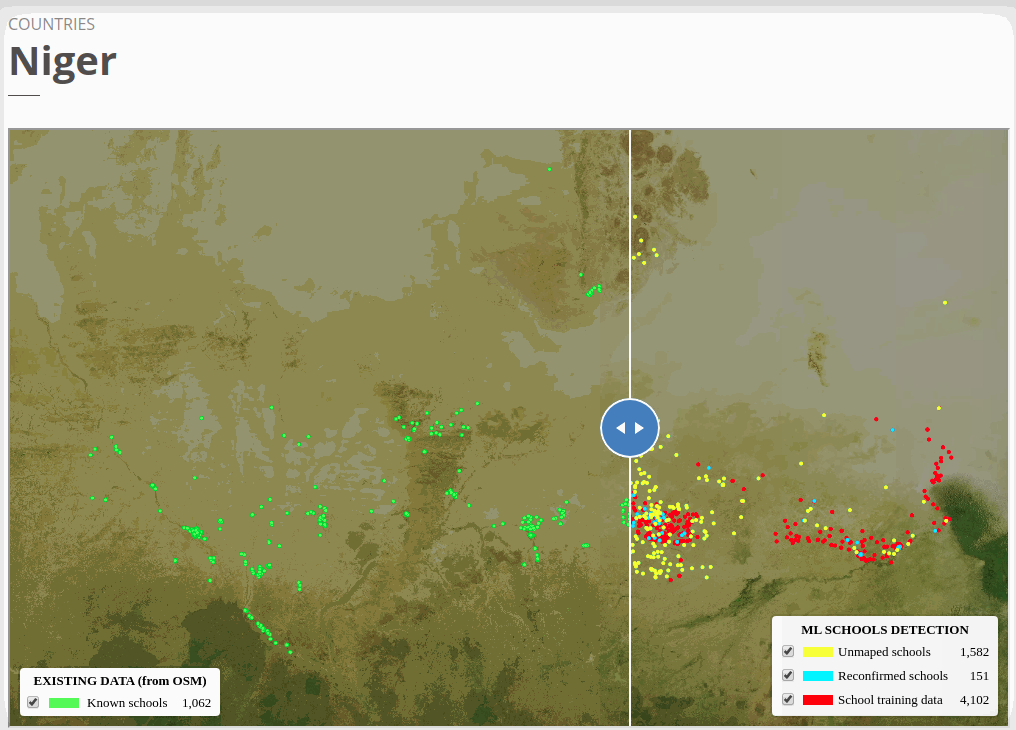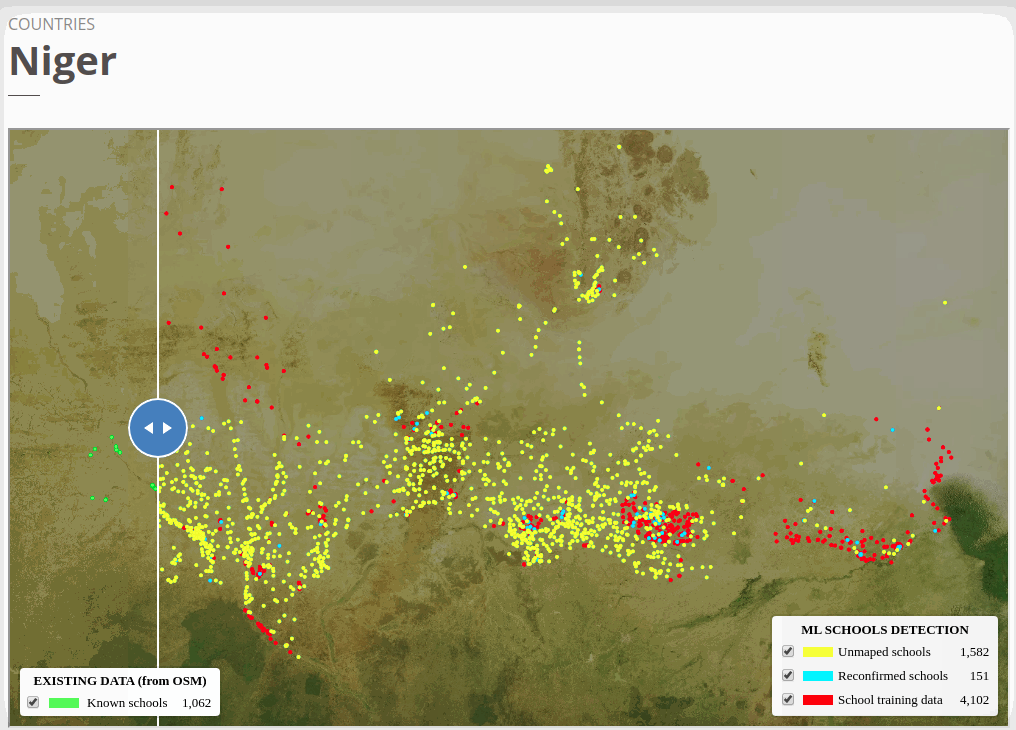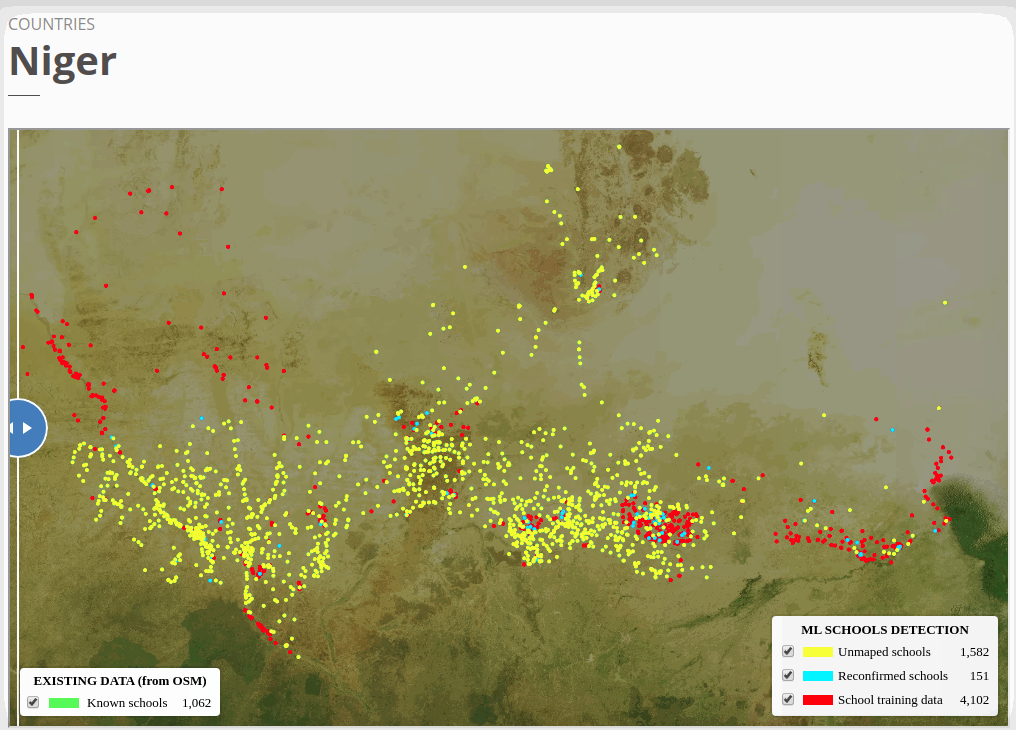
To view the online school map for Niger, please go to the Niger school map viewer.Basemap by © Mapbox.
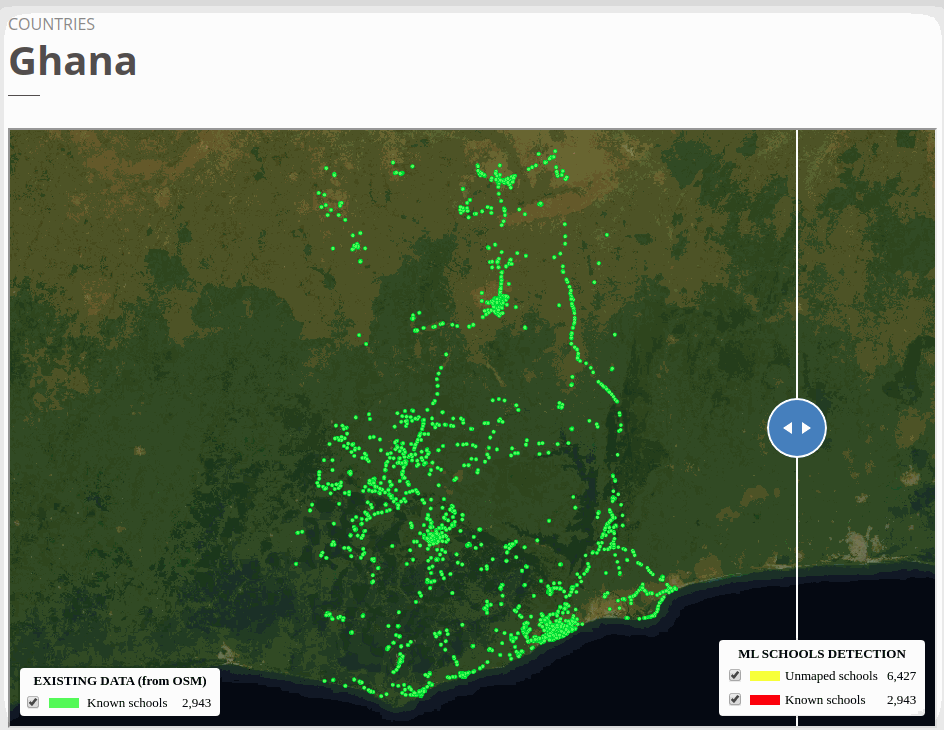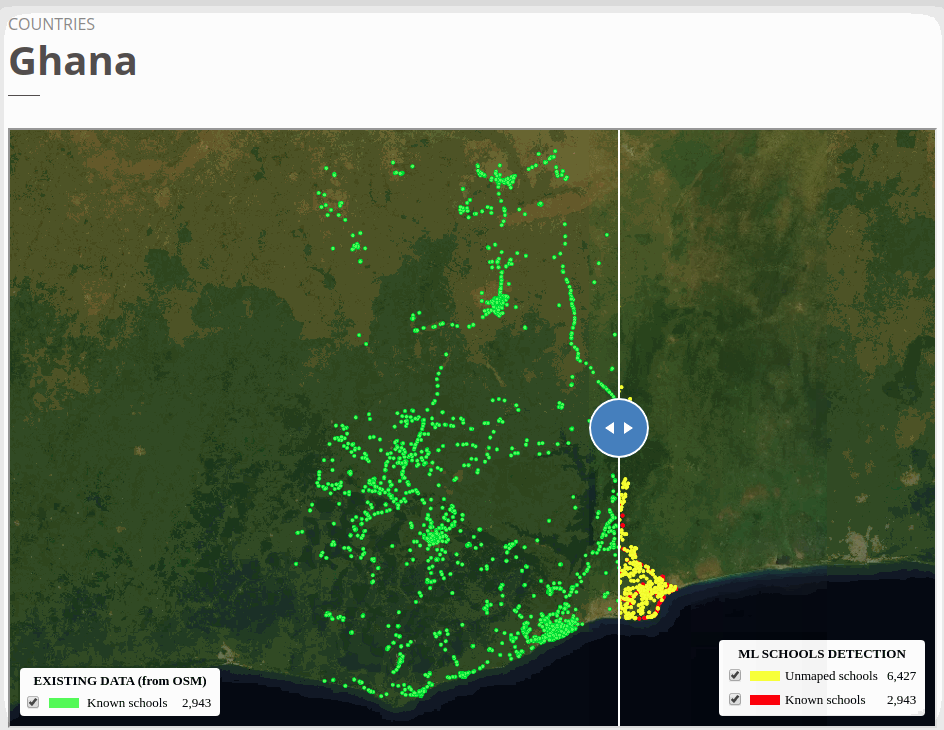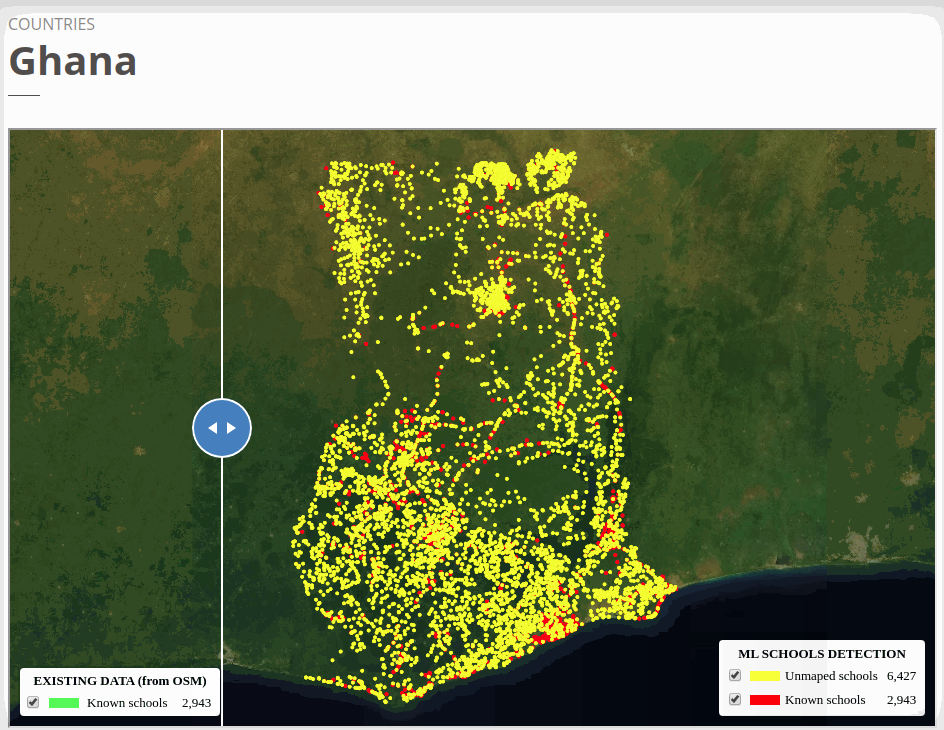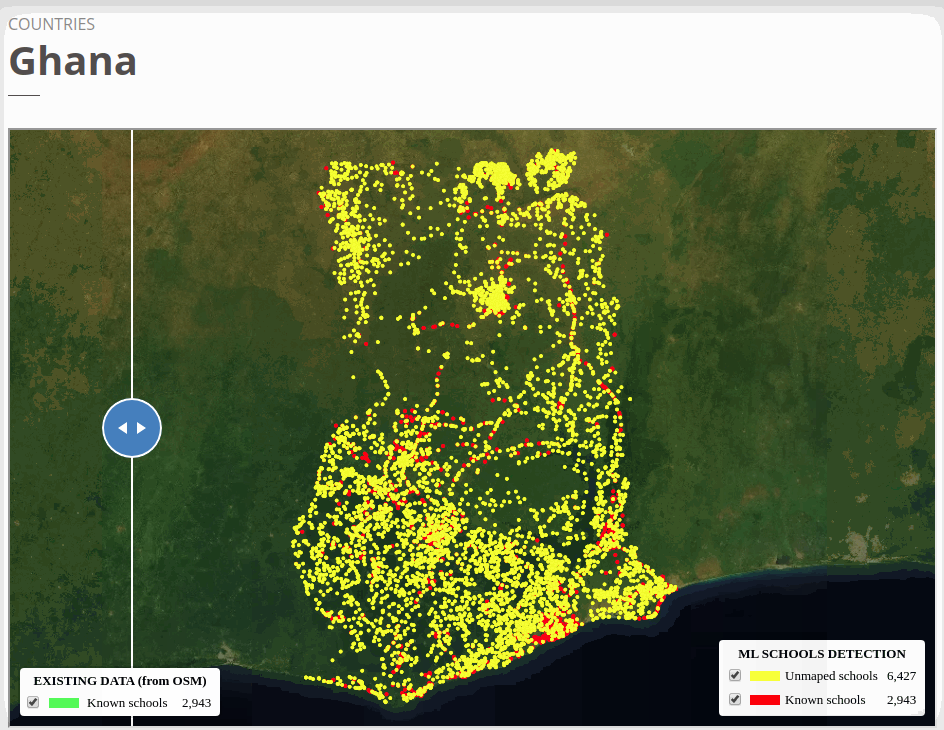
To view the online school map for Ghana, please go to the Ghana school map viewer. Basemap by © Mapbox.

We trained six country models (Kenya, Sierra Leone, Kazakhstan, Rwanda, Niger and Honduras), two regional models (West and East Africa regional models) and a global model under tile-based school classifier model training. The model training and experiment were deployed to GKE with Kubeflow and TFJob.
ML Enabler generates and visualizes predictions from models that are compatible with TensorFlow’s TF Serving, on-demand. All you need is to drag and drop a zipped trained model, provide a Tile Map Service (TMS) endpoint, and polygon of your area of interest (AOI) for the inference. ML-Enabler will spin up the required Amazon Web Services (AWS) resources and run inference to generate predictions.
What we're doing.
Latest