

Urban settlement change around Awassa, Ethiopia. Red indicates the extent of urban areas in 2000. Blue indicates the extent of these settlements in 2017. Awassa is located south of the capital city, Addis Ababa.
Policymakers rely on Land Use and Land Cover (LULC) maps for evaluation and planning. They use these maps to plan agriculture policy, improve housing resilience (to earthquakes or other natural disasters), and understand how to grow commerce in small communities. A number of institutions have created global land use maps from historic satellite imagery. However, these maps can be outdated and are often inaccurate, particularly in their representation of developing countries.
We recently worked with the World Bank to complete an analysis of urban dynamics in Ethiopian Lowlands. We found that Global Land Use and Land Cover maps were wholly inadequate for this analysis and little high-quality data existed to reproduce the process. To overcome this, our Machine Learning and Data Teams partnered to create a new methodology for machine learning in data-sparse environments and used it to create an accurate and timely settlement map for Ethiopia. By automating this approach, we believe we can create vastly more accurate results for land cover maps in most countries.
The Trouble With Global Land Use / Land Cover maps
When we began this project, there was no accurate Land Use and Land Cover (LULC) dataset for Ethiopia. This is not unique to Ethiopia. Studies of popular LULC datasets have shown that they produce dramatically different results, particularly in developing countries. (See for instance this study in China and this study across Africa.)
There are multiple reasons why this might be the case. Competing LULC schemas and standards certainly contribute to LULC maps that cannot be compared directly and don’t translate well. However, even within institutions, different units may produce maps that disagree. Current training datasets are still Amerocentric and Eurocentric. To benefit from deep learning or even traditional machine learning on such a task, especially in developing countries, high-quality training datasets need to be created and openly shared. My colleague Drew Bollinger has written on geodiversity and on how non-diverse datasets produce poor results in the developing world.
A model for Land Use / Land Cover in Data-Sparse environments
Rather than relying on global or continental LULC products, a repeatable methodology to accurately map LULC will often provide policymakers with better data for their needs on the ground. At the core of our approach is a two-step machine learning process (Figure 2 below) to map urban settlement and track changes. This approach helps to overcome some of the data challenges that make standard machine learning approaches inadequate, specifically:
-
Ethiopia is a large country (1.1 million km2) with highly variable land cover. This suggests a large amount of training data would be needed to cover all land use types;
-
buildings, roads, and public spaces generally do not fill an entire 30m x 30m pixel — the resolution of the Landsat imagery we used. The majority of built-up pixels are, therefore ‘mixed’, containing, e.g., both a few buildings, roads, and bare soil;
-
when we began this project, there was no accurate LULC dataset for Ethiopia to be used as training data.
To overcome these challenges, we created an ML pipeline (Figure 1.) that:
-
combines the strengths of a small group of human mappers with machine learning, and
-
combines the strengths of both unsupervised and supervised ML methods.
First, we used an unsupervised learning pre-processing step to cluster pixels of the urban mask from the satellite imagery. Second, we applied supervised learning to classify built-up within each identified urban mask cluster (Figure 1).
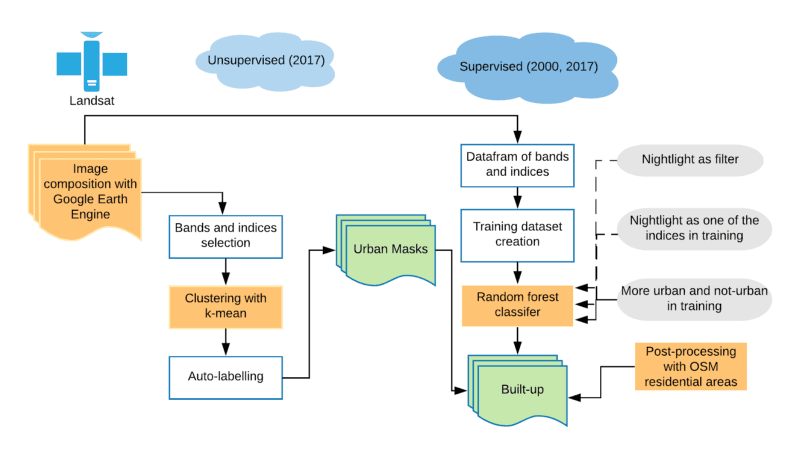 Figure 1. The diagram of our build-up and urban settlement detection with machine learning approaches. There are four components to this pipeline: 1) Composing Landsat imagery between 2000 and 2017; 2) creating urban masking with k-means; 3) creating a built-up map with Random Forest and urban mask from the previous workflow; 4) post-processing with OpenStreetMap to remove built-up pixel outside of residential and commercial areas as well as misclassified bare soil.
Figure 1. The diagram of our build-up and urban settlement detection with machine learning approaches. There are four components to this pipeline: 1) Composing Landsat imagery between 2000 and 2017; 2) creating urban masking with k-means; 3) creating a built-up map with Random Forest and urban mask from the previous workflow; 4) post-processing with OpenStreetMap to remove built-up pixel outside of residential and commercial areas as well as misclassified bare soil.
Data Preparation
To conduct this analysis we used two types of data:
-
Cloud-free mosaics for Ethiopia over time. We used Google Earth Engine to mosaic more that 50 Landsat scenes quarterly between 2000 and 2017.
-
Urban settlement extents for periods that correspond to our cloud free mosaics. A high-quality training dataset is essential for supervised learning models to learn the most important image features, especially for pixel level analyses. As mentioned earlier, no such training dataset was available for Ethiopia. Therefore, our Data Team of expert mappers quickly built a training dataset to calibrate our supervised models by tracing urban boundaries in the 2017 Landsat images.
Our ML approach
ML Step 1: Unsupervised learning: Creating terrain cluster masks
We first used an unsupervised K-means clustering to identify spectral classes from the imagery. K-means clustering doesn’t rely on training data. It groups image regions by similarity, creating groups that have a similar spectral signature. By reviewing the histogram of clusters generated from this process we were able to eliminate large swaths of the country that clearly did not have any similarity to urban areas.
Unsupervised clustering works well to identify distinct spectral classes from imagery. However, it is not adequate by itself to classify built-up/urban area, as there is considerable confusion between urban areas and bare earth in urban areas in Ethiopia. It can, however, be useful to mask out areas that are definitely not built-up.
K-means doesn’t use training data and doesn’t output what the specific class labels are. To automatically label the classes of candidate area we use a small amount of training data for urban areas. A histogram of the classes is generated from all the pixels underneath the training polygons, and the “urban” pixels were extracted. See our detailed technical report if you want to learn more.
ML Step 2: Supervised learning: classifying each cluster mask
Following the creation of an urban candidate area with unsupervised learning, we then selected the areas corresponding to built-up areas for further analysis. The urban candidate area contained built-up pixels and some other pixels, including a lot of bare soils and dry grassland.
We then used a second more intensive ML process, to distinguish between the remaining pixels using time series data. Different types of areas experience different types of change over the course of the year. For each candidate pixel, we generated quarterly values for Normalized Difference Vegetation Index (NDVI), Soil Index (BSI), Normalized Difference Built-up Index (NDBI) and Normalized Difference Water Index (NDWI). Supervised learning was helpful in removing pixels belonging to agricultural and grazing lands — these pixels can be identified by temporary periods of bare soil.
The second ML process generated results that closely correlated actual built-up areas across Ethiopia.
Post-processing with OpenStreetMap
Our final prediction of the built-up area still had a few false positives. Bare soil is sometimes misclassified as built-up/urban in the desert and steppe terrain in the Western and Southwest parts of Ethiopia. This is in part because the urban settlements in these parts of Ethiopia are rarely paved, meaning that there is a high composition of bare soil in the pixel. Further, the Bank wasn’t just interested in the built-up area, it was interested in urban areas, which have a narrower definition and exclude built-up areas like towns and agricultural production facilities.
These subtle distinctions are still best made by humans. We undertook the final analysis of the candidate areas, using the image, surrounding context, and supplemental data sources like OpenStreetMap. The post-processing has two purposes in our workflow:
-
Excluded bare soil areas in Western Ethiopia where desert and steppe terrain is dominant;
-
Removed the detected individual or small villages that aren’t the urban settlements.
Conclusions and next steps
Using our outlined approach, we were able to accurately map urban settlement and the changes. We also calculated the urban settlement growth rate between 2000 and 2017 in Ethiopia based on the maps (Figure 2).
 Figure 2. Urban growth rate (%) at the woreda-level in Ethiopia. Urban growth rate measures the urban trends and dynamics in Ethiopia from 2000 to 2017. The rate was obtained through (urban settlement 2017-urban settlement 2000) / urban settlement 2000 * 100. For more details, please go to *our project report*.
Figure 2. Urban growth rate (%) at the woreda-level in Ethiopia. Urban growth rate measures the urban trends and dynamics in Ethiopia from 2000 to 2017. The rate was obtained through (urban settlement 2017-urban settlement 2000) / urban settlement 2000 * 100. For more details, please go to *our project report*.
We did much of the initial work to package this into a repeatable ML workflow that can be automated and scaled to other countries. The above traditional machine learning method can be applied to other countries in a repeatable manner. From our current deep learning algorithm exploring and experimenting with deep Convolutional Neural Networks (CNNs), it may offer another promising approach to this urban mapping. CNNs are capable of learning from context. For example, pixels belonging to buildings are often surrounded by other buildings pixels or green space. They can also interpret more complex features, including how certain man-made patterns that forests or agricultural lands don’t contain. CNNs can be trained with the pre-trained ImageNet models, e.g. Inception, VGG, ResNet etc, which learned millions of image features benefit remotely sensed pixel-level classification. CNNs perform better when we have a bigger, high-quality, and richer training datasets. The modern and inexpensive GPU-powered cloud computing makes the training, and large model inference and interpolation much faster.
Landsat and Copernicus Sentinel images are the two most widely used open source images in LULC mapping. In this study, we were limited to Landsat imagery since it’s the only dataset that spans the period from 2000 to 2017. For projects that don’t need to go back before 2015, Sentinel-2 imagery would be better due to its higher spatial resolution and more frequent revisit rate.
We hope to explore the deep learning methods on similar subjects in the future. **If you are interested in deriving insights from satellite imagery for various applications ranging from agricultural development, urban resilience strategies, to special economic zones, let’s talk! You can ping me on Twitter**
What we're doing.
Latest