

Artificial intelligence is not magic. It may be portrayed like magic — we see big advancements like autonomous cars, superhuman Atari game play, AlphaGo, and ubiquitous home assistants. Like magic, AI can also defy understanding. The broad concepts of machine learning (ML) — the applied arm of AI — can be challenging to explain to anyone who hasn’t spent time developing their own models. Deep learning models, which sit at the cutting edge of ML, are nearly impossible to dissect and understand for AI experts and novices alike.
However, regarding AI as magic is a liability — especially in the business world with contractual obligations. Deep learning frameworks (e.g., TensorFlow and PyTorch) have put modern ML tools within reach for the masses. Many groups outside the comp-sci research community, enchanted by ML’s promise, are now eager to wield its power. However, realizing its potential requires an understanding of its limitations and the narrow set of problems it’s suited to address. This post attempts to:
-
explain what problems are most amenable to ML
-
provide tips for discussion between ML experts and non-experts
-
outline a framework for thinking realistically about the ML process
Foundations for a successful ML project
 AI as an idiot savant.
AI as an idiot savant.
Machine learning, the applied branch of AI, excels at problems that are relatively simple and repetitive. Much of the ML work today involves calibrating a model to take input and generate quantitative predictions. This calibration (or “training”) occurs by feeding the model thousands of examples where the “correct” answer is known. For example, we might want to use ML to automatically detect cars in images. To do that, we’d need training dataset where someone has manually labeled thousands of images indicating which images do indeed contain an automobile. Or we can train a model to locate buildings within satellite imagery using an training image set where building outlines were pre-traced. After using this training data to calibrate the system, the hope is that the model makes accurate predictions on new, unseen data. If the task doesn’t require any special skills, a large training dataset exists, and there is a clear quantitative output, ML is probably worth investigating. Some experts suggest thinking of modern ML as an idiot savant; given a narrow task with very specific instructions and many training examples, ML can provide superhuman accuracy at uncanny speed.
When applying ML for business, the key is defining specific, deliverable goals — again, AI is not magic. Fans of the Hitchhiker’s Guide will know that autonomous systems don’t do well with ambiguity. ML experts should convey their field’s limitations to non-technical collaborators and express that ML projects usually operate like R&D work. Staying forthright and realistic up front will avoid over-inflated expectations and the tension that comes with deliverables going undelivered. Giving an honest opinion will also encourage trust and lay the groundwork for a long-term business relationship. Consider starting with a narrow pilot project if any of the major collaborators are new to ML work. If the project is successful, it will provide insight into realistic next steps and a springboard to get there. If not, a small-scale project likely involves fewer burned resources and a better chance to pivot.
Discuss what’s important: input and output
When scoping an ML project, technical experts and project stakeholders (e.g., the client, manager, or advisor) should first agree on what’s flowing in and out of the ML algorithm — not the algorithm itself. At the end of the day, the project planners want to know the sausages got made; not necessarily how they got made. Early in the project, it may help to treat the ML algorithm as a black box and focus instead on the input and output.
Input: due diligence from ML experts
As the ML expert, try early on to secure all the resources required to deliver on schedule. As discussed later in this post, the earliest obstacles are likely to stem from issues with the training data (e.g., size of dataset, poor quality, or lack of organization). Monica Rogati wrote an excellent piece on The AI Hierarchy of Needs that underscores the importance of clean and accessible data. You’ll make your life easier if everyone involved understands that any required data collection and munging will push back the time horizon for a successful model. It’s not uncommon to spend 50–75% of the total project effort toward cementing this foundation.
Output: due diligence from business and planning experts
As the client, advisor, or manager, it’s likely your job to ensure the high-level goals are met. Define the efficiency boost, cost reduction, or research advancement you expect at the output end of your ML pipeline. What exactly is the format of the model’s output, and are you prepared to handoff this output to the next link in your processing chain? Any ambiguity here should be sorted out before the project begins. If possible, also discuss the best ML metric(s) to gauge model performance (e.g., accuracy, false-positive rate, etc.). Everyone should share a common understanding of “success.” Once a working system is developed, does it need to be optimized for prediction (or “inference”) and deployed at scale? Again, having these conversations early will avoid having to move the goalposts at the tail end of the project.
ML development process in reality
Research and development
Implementing modern ML algorithms is R&D work. This aspect may catch non-technical collaborators off guard, as the baked-in uncertainty of R&D eludes linear progression and rigid timelines. This is doubly true when using algorithms from the bleeding edge of ML research — often, the most powerful algorithms are also the most time-consuming to train and use. Modern ML has matured enough to be successful outside pure research environments at academic labs and tech giants, but again, the best practitioners are wise to its limitations. Applied ML engineers should give an honest opinion on how appropriate ML is for a given problem and be ready to temper AI exuberance. After the initial project planning, nobody involved should still believe AI is capable of consistent, easy wins; those that do will face a difficult disillusionment by project’s end.
Project sub-cycles
Applied ML projects comprise a rough set of stereotypical steps. Each step will require some amount of debugging, modifications, and fine tuning to build the complete pipeline from end-to-end. Progressing through these steps will likely look more like a twisting game of Chutes and Ladders than a sequential checklist. Discovering a problem on step four might require revisiting two and three. Or step two could require several attempts to get right. We can frame each step in the progression as a cycle to reflect this characteristic. We’ll dissect the entire ML project lifespan into five cycles: (1) data collection, (2) data flow, (3) classic ML model, (4) modern ML model, and (5) deployment.
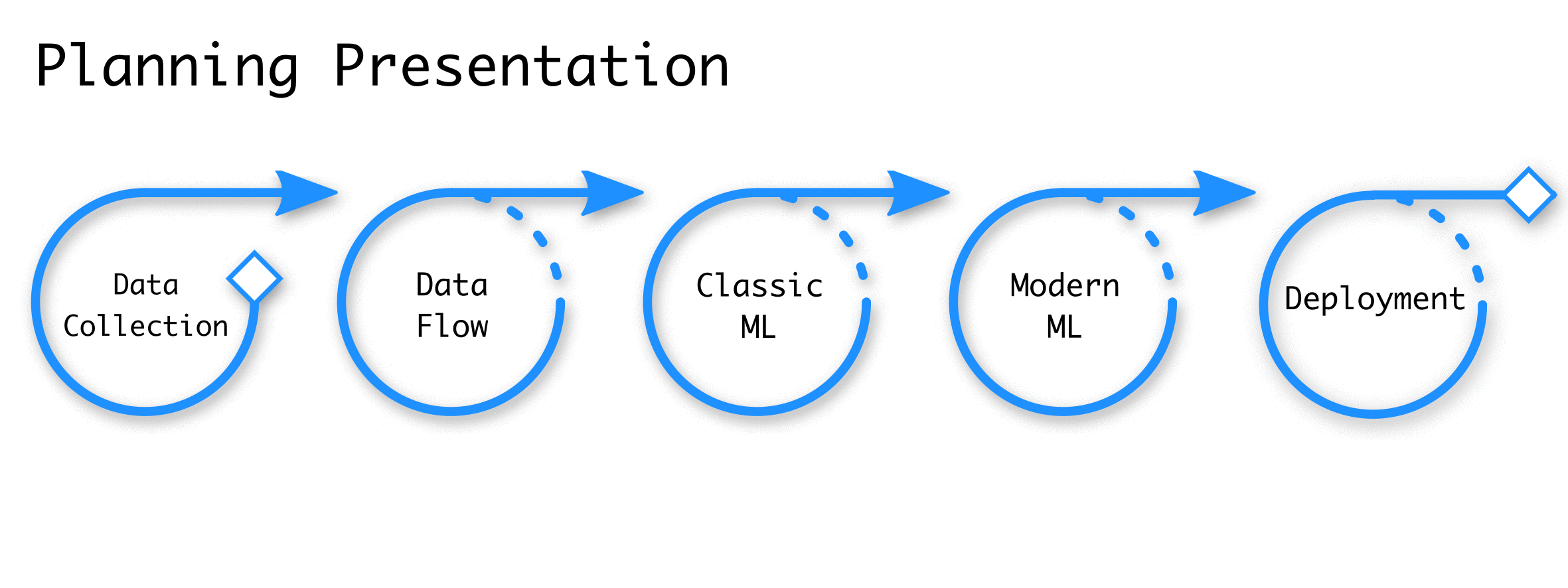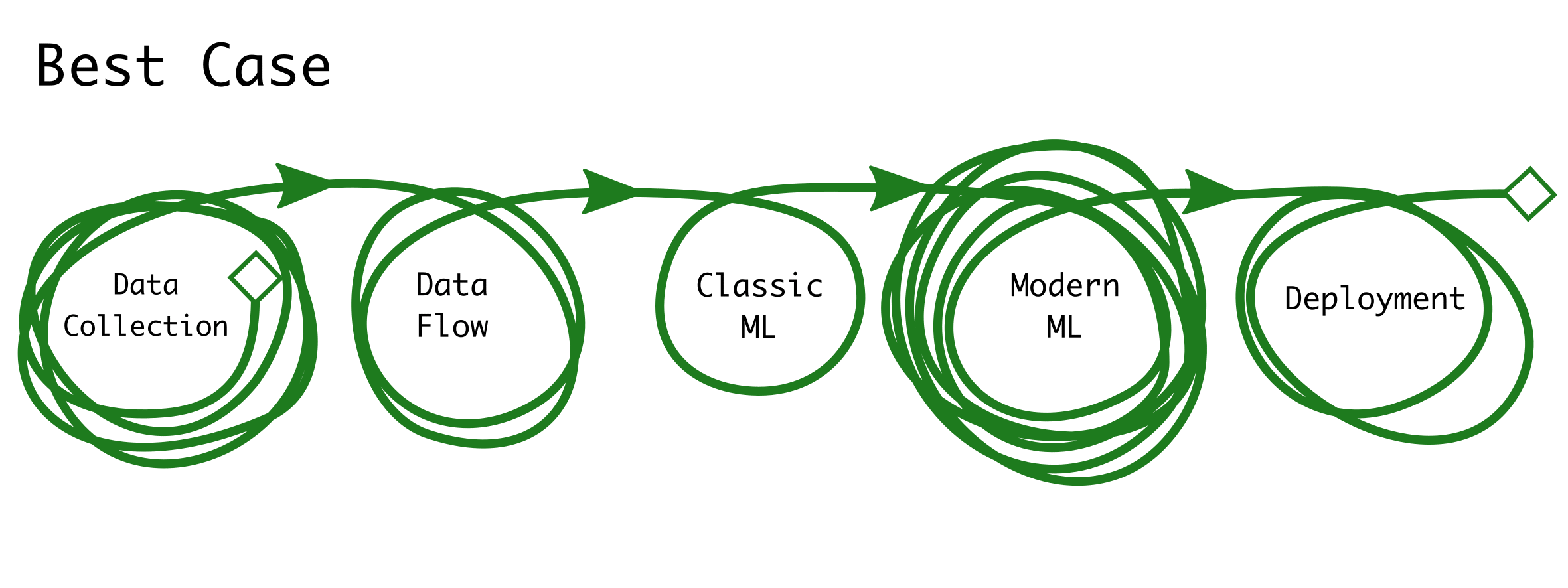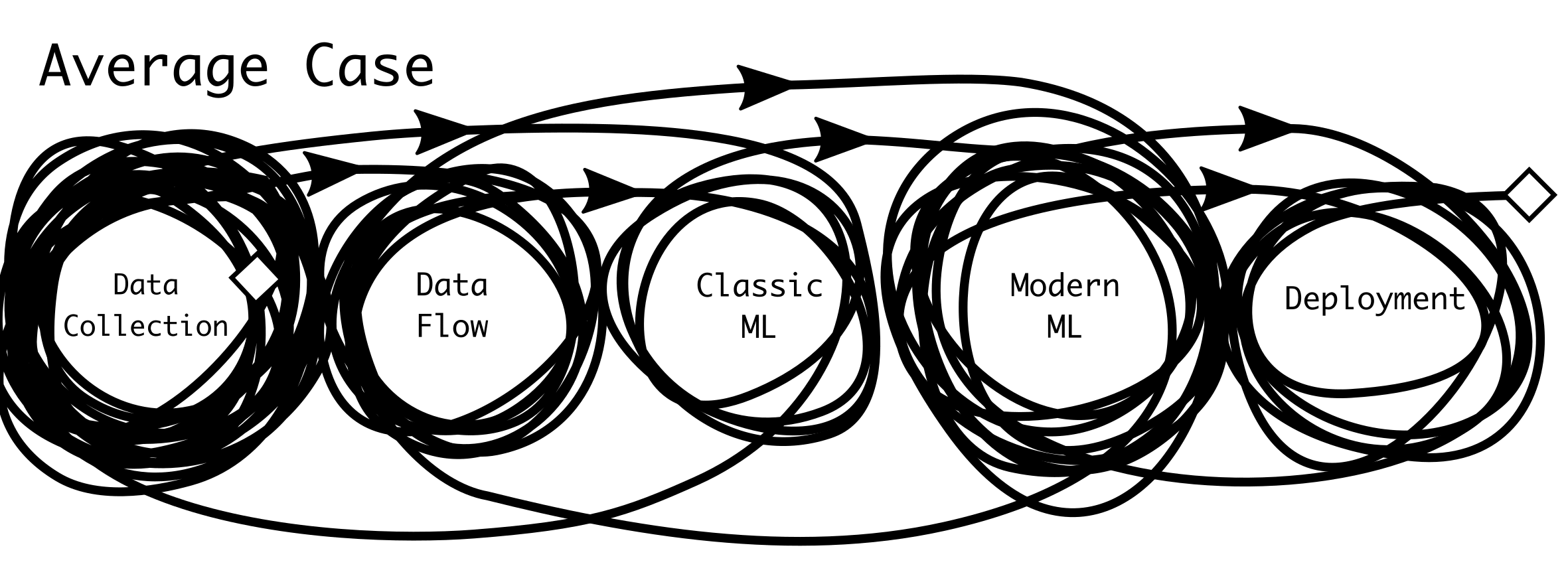 People with different views on ML will hold different expectations for the path to success. There are many factors (some unknown at project outset) that affect the work required. Often, the most important factors are the difficulty of the problem (e.g. pixel-wise image segmentation is more difficult than image classification), the quantity and quality of training data, and the desired performance and reliability of the deployed model.
People with different views on ML will hold different expectations for the path to success. There are many factors (some unknown at project outset) that affect the work required. Often, the most important factors are the difficulty of the problem (e.g. pixel-wise image segmentation is more difficult than image classification), the quantity and quality of training data, and the desired performance and reliability of the deployed model.
1. Data collection
Goal: Collect training data
-
Collect raw data samples to train your ML algorithm.
-
Generate labels (if working with supervised learning).
-
Discard bad data samples.
Overly honest admissions: There is no magic number for “enough” data samples. It depends on a range of factors, including the type and difficulty of the ML problem, potential for data augmentation, and your desired performance.
2. Data flow
Goal: Clean, preprocess, and structure training data
-
Write preprocessing scripts to further filter out low-quality data samples or label errors.
-
Collate data into single data structure or archived folder file-tree.
-
Run sanity checks by plotting data samples and calculating simple statistics.
Overly honest admissions: The data collection step and this dreary “data munging” step may combine to require well over half of the total project effort. Real-world data is often a mess.
3. Model: classical ML
Goal: Construct a simple ML model
-
Implement a classical ML algorithm (e.g., logistic regression or a random forest classifier).
-
Establish a lower-bound on the performance of your ML pipeline.
-
Investigate patterns of incorrect predictions.
Overly honest admissions: You may need to skip this step for time constraints or if the superiority of deep learning is well-documented for the problem at hand. Nevertheless, classic ML is usually simpler to train, easier for non-experts to grasp, and faster when deployed.
4. Model: modern ML (e.g., deep learning)
Goal: Construct a cutting-edge ML model
-
Implement a modern ML algorithm (likely drawing on pre-existing deep learning architectures).
-
Train the model using automated hyperparameter search and save the results of each experiment.
-
Visualize metrics and plot sample predictions to gauge performance.
Overly honest admissions: Skimping on the automated search, saving of hyperparameters, and visualization to move fast is risky business — it makes problems hard to debug and clouds the definition of success.
5. Scale prototype
Goal: Scale and deploy the trained model
-
Optimize model for inference (i.e., prediction) at scale.
-
Build pipeline to ingest requests, preprocess data, and run inference at scale.
-
Protect the deployed system’s reliability by preparing for dynamic data.
Overly honest admissions: This step will depend heavily on your application and end-users. If you don’t have experience deploying on the cloud at scale, seek advice from engineers who do.
Conclusions
Building end-to-end ML projects is hard. The process tends to resemble R&D more than software development, usually involves people with different backgrounds, and is sensitive to bloated expectations. This post focused on three tips for executing realistic ML projects. First, honestly characterize the problem at hand. Decide if it’s a good candidate for ML rather than deciding to use ML and subsequently hunting for a problem. Second, focus early team conversations around the input and output of the ML pipeline. Different team members will bring different assumptions to the table, so pin down unified expectations as a group. Third, outline the high-level steps needed to reach a working solution. Identify potential problem areas in each step (e.g., limited training data or lack of cloud deployment infrastructure) to inform the project timelines. Hopefully, this guide provides a useful overview for planning and implementing ML solutions. Nevertheless, don’t underestimate the advice of seasoned experts when the project inevitably veers into uncharted territory.
What we're doing.
Latest