

I’ll be at the Humanitarian OpenStreetMap Team (HOT) Summit today, facilitating a discussion on integrating machine learning into their workflow.
OpenStreetMap (OSM) is ripe for machine learning. As a community built map, its most valuable resource is the time and engagement of its volunteers. If OSM mappers were even 7% more efficient, they could map another Australia every year. [1]
HOT’s work involves rapidly building the map around disaster events, such as its amazing efforts over the past two weeks mapping flood areas in South Asia, earthquake-affected Mexico, and the entire paths of Irma and Harvey. But HOT volunteers also spend long monotonous hours searching through open forests to map small villages in support of Malaria eradication projects or power lines in support of electrification projects.
Machine learning can help in both of these cases, by directing volunteers attention to where it is most valuable or by directing them to tasks suited to their skill level and the time they have to contribute.
Machine Learning in the HOT workflow
As a thought exercise, here is an example of what it could look like to augment HOT’s workflow with machine learning.

A HOT manager defines a new task and selects an area of interest. As she creates the new task she has the option of adding some context layers. These invoke a computer vision algorithm created using machine learning to quickly scan the imagery and create a layer that provides volunteers with more information about where to start mapping. For instance, this context layer might show an estimate of the number of buildings, the number of buildings that appear to be damaged, or the locations for settlements.
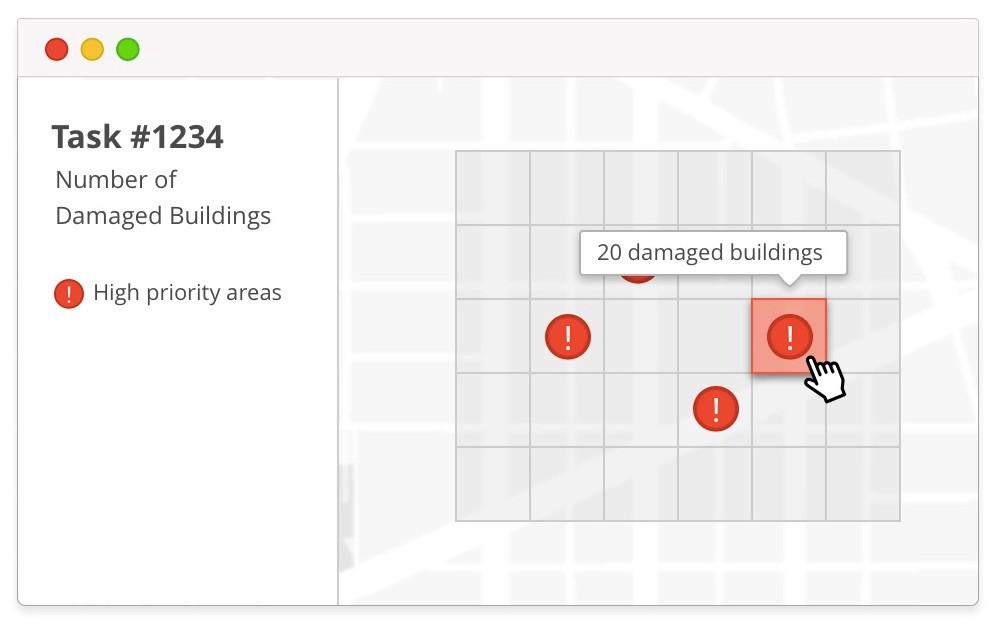
These context layers can be used to prioritize parts of the map or to help users select a square that fits their skills and available time. Mapping rural areas can involve monotonous time scanning through miles of forest looking for a settlement. Preprocessing can help direct attention where it matters.
Blake has an even better idea. The algorithm could try to assess the difficulty of mapping each square. Difficulty could be determined through a known heuristic, such as how close buildings are to each other. (Beginning mappers do better with detached homes.) Or data from the OSM validation process could be used to teach a computer what an easy cell or a hard cell looks like.
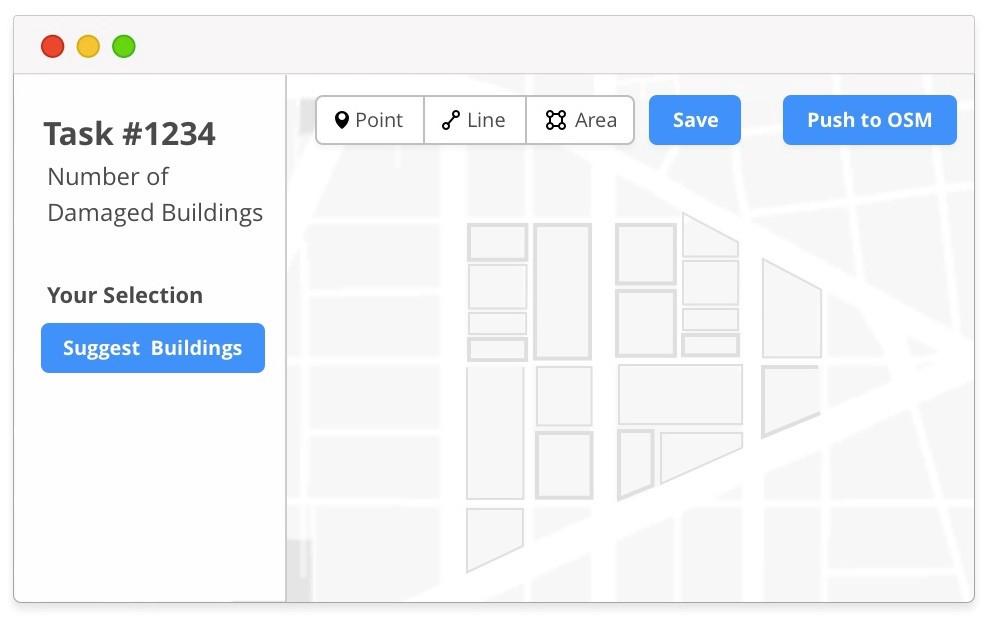
A volunteer mapper selects a high priority grid square and starts mapping. In order to save time, he selects a button that says “Suggest buildings”.
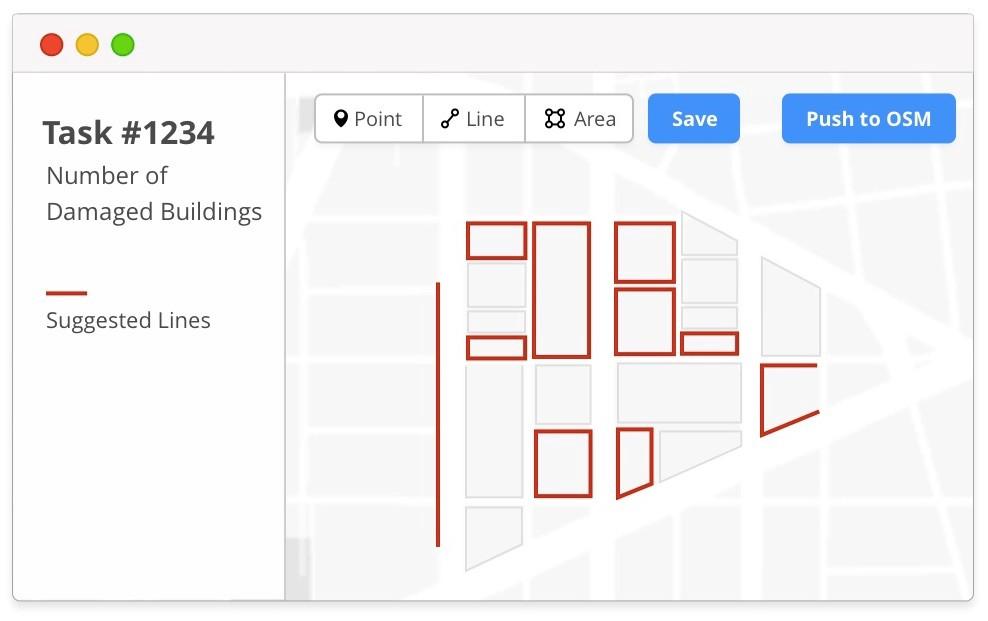
A machine learning trained process instantly provides suggestions of building outlines along with appropriate building tags. The user reviews this data; he adds, removes, and edits the suggestions as needed. When he is happy he saves the changes and pushes the changeset to OSM.
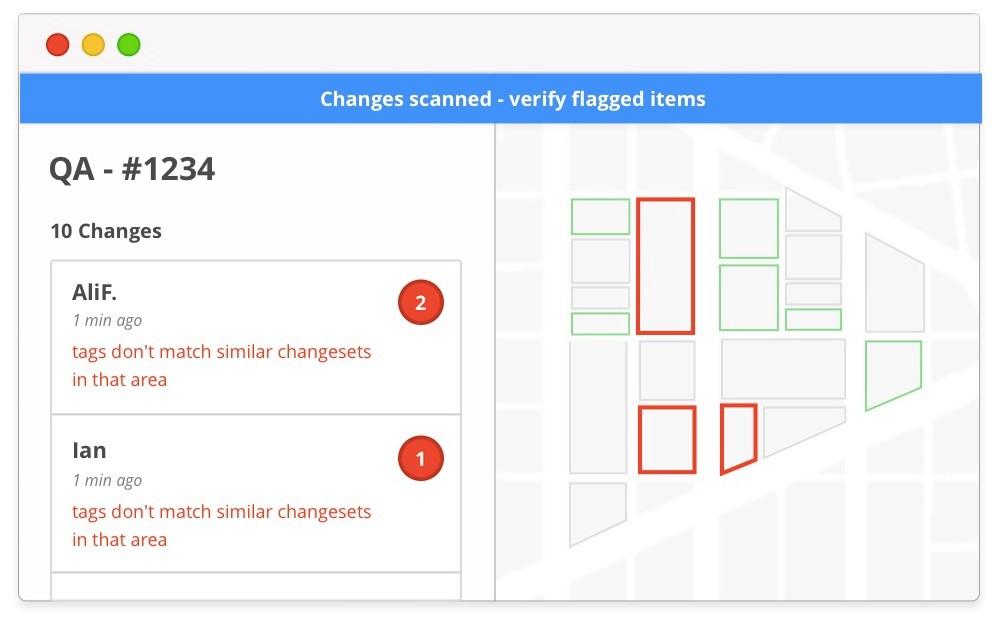
As mappers submit their changesets, a machine learning process automatically scans them looking for evidence of errors or vandalism. This allows a QA team, using a tool like OSMCha, to have smarter flagging and ordering of tasks in order to spend QA time on areas of greatest need. As the QA team reviews changesets, their actions help the process get smarter about what to flag and prioritize. In this way new “flavors” of mistakes can be quickly noticed and addressed.
What do you think?
If you are interested in the possibilities for machine learning to help HOT, join us today at 10 at the HOT Summit. There is a great group of people at the Summit who are already working on applying machine learning at scale. It’s going to be a great conversation.
If you aren’t at the HOT Summit you can drop your thoughts in the discussion notes or on twitter using #HOTSummit.
- Some quick numbers from @kamicut: Over the past year, OSM mappers have added 568,633,723 nodes and 65,193,364 ways. All of Australia currently mapped on OSM currently comprises around 40 million nodes and 3 million ways.
What we're doing.
Latest