

Tomorrow, I will be at SatSummit talking about Development Seed’s machine learning work and what we’ve learned over 18 months of building open source tools for imagery analysis. We are building open source machine learning tools and open algorithms that can be shared and improved by academics and implementers without expensive software or license fees.
Machine learning has tremendous potential to improve the work of development organizations. We use machine learning to create smart algorithms to analyze satellite imagery to determine land use or to identify features like roads and buildings. Automating imagery analysis allows us to more quickly map unmapped areas or to monitor vast crop or forest areas and alert us to anomalies.
But what does it require to take advantage of machine learning in your work? Here are a few things we’ve learned about using machine learning to identify features like roads and buildings.
For road detection use one meter resolution imagery or better. Multispectral imagery can improve results.
We’ve done land use classification and vegetation analysis on all manner of data, from 30 meter to less than one-meter resolution. For many of these applications, higher resolution imagery doesn’t significantly improve results, and can even add noise in some cases. For road and building detection, we’ve had greatest success with imagery that is one-meter resolution or better.
Bringing in infrared bands can better distinguish plants from built up areas. It’s helpful for identifying roads in certain contexts, particularly in suburban neighborhoods with lots of trees.
 left column: input images (infrared, true color), © DigitalGlobe; middle: OpenStreetMap data; right: our model prediction
left column: input images (infrared, true color), © DigitalGlobe; middle: OpenStreetMap data; right: our model prediction
You need at least 100 square kilometers of high quality training data for feature extraction
Machine learning requires a lot of good training data to produce accurate results. Groups often ask, “How much training data is enough?” We ran some experiments to determine that.
For the road detection work that we demonstrated at State of the Map we used 559 square kilometers of training data. We experimented with using gradually less data (372km2, 186km2, 93km2, 47km2) to determine at what point the accuracy deteriorated. For less dense mapping across a consistent area, sometimes ~100km2 of high quality training data produced accurate results on roads. (That’s about the size of Sacramento. Or a little less than Washington DC’s NW and NE quadrants combined)
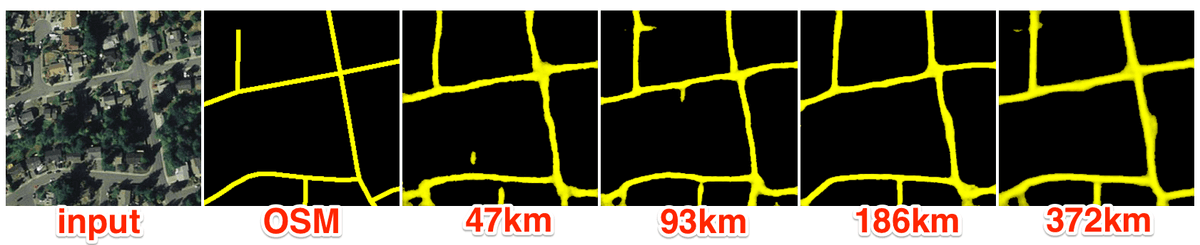 left-to-right: input image, © Mapbox Satellite; OpenStreetMap data; columns 3–6: our model predictions with varying amounts of input data
left-to-right: input image, © Mapbox Satellite; OpenStreetMap data; columns 3–6: our model predictions with varying amounts of input data
For denser areas, or when trying to create a model which can make predictions over a larger variety of areas, more input data helps.
 left-to-right: input image, © Mapbox Satellite; OpenStreetMap data; columns 3–6: our model predictions with varying amounts of input data
left-to-right: input image, © Mapbox Satellite; OpenStreetMap data; columns 3–6: our model predictions with varying amounts of input data
For buildings, we started with the same 559km2 baseline for training data and saw promising results but it was tough to get clearly defined edges. We tried to limit our inputs to places where we felt very confident about the training data. Because this limitation reduced the input data to under 100km2, we didn’t see good improvement. Jump in the repo if you have some ideas for how to improve!
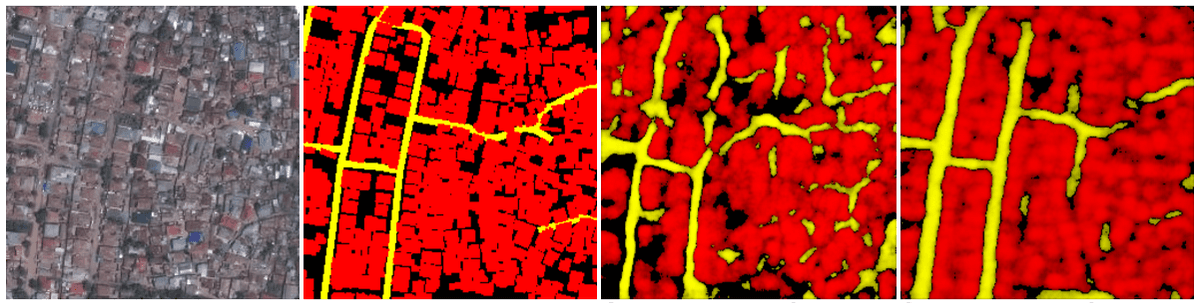 left-to-right: input image, © Mapbox Satellite; OpenStreetMap data; our updated model with less input data; our first attempt
left-to-right: input image, © Mapbox Satellite; OpenStreetMap data; our updated model with less input data; our first attempt
Training a model can take a few days. But once its trained you can apply it in real time.
We’ve had most success running about 100 thousand iterations of our model. With one AWS g2.2xlarge instance that takes around 4 days. This is mostly something that can run in the background, but occasionally you'll need to kick the server.
Once the machine learning process has produced a algorithm, you can apply it to additional imagery in real time. We have set up apps that conduct analysis of imagery in real time as you browse.
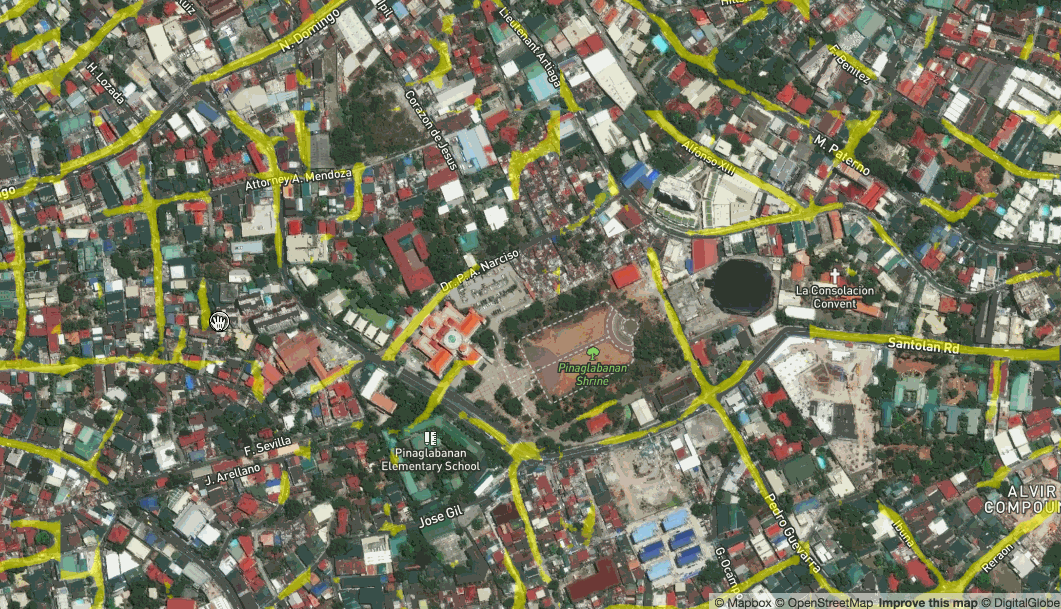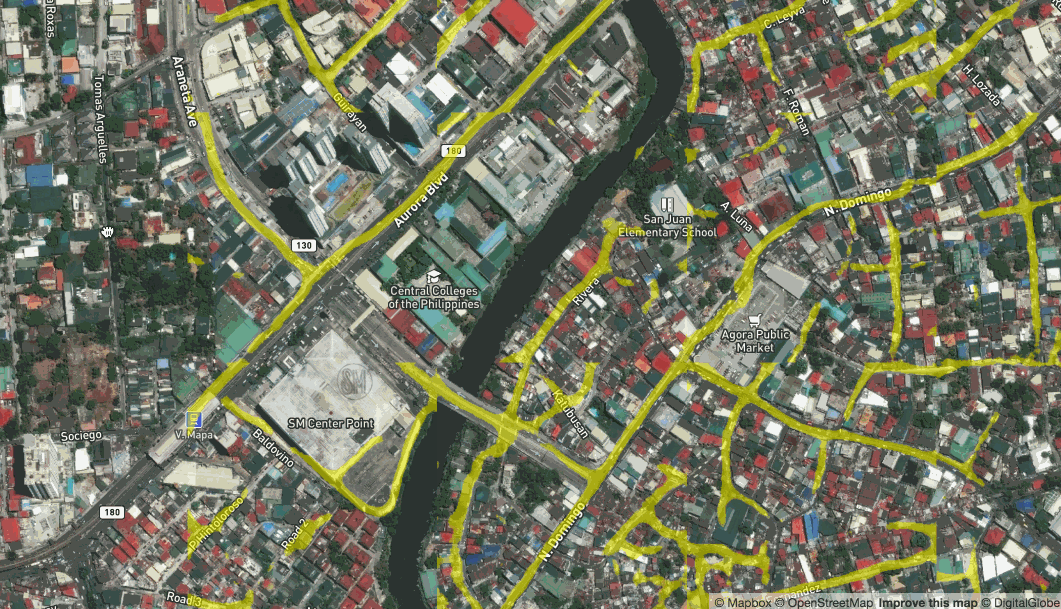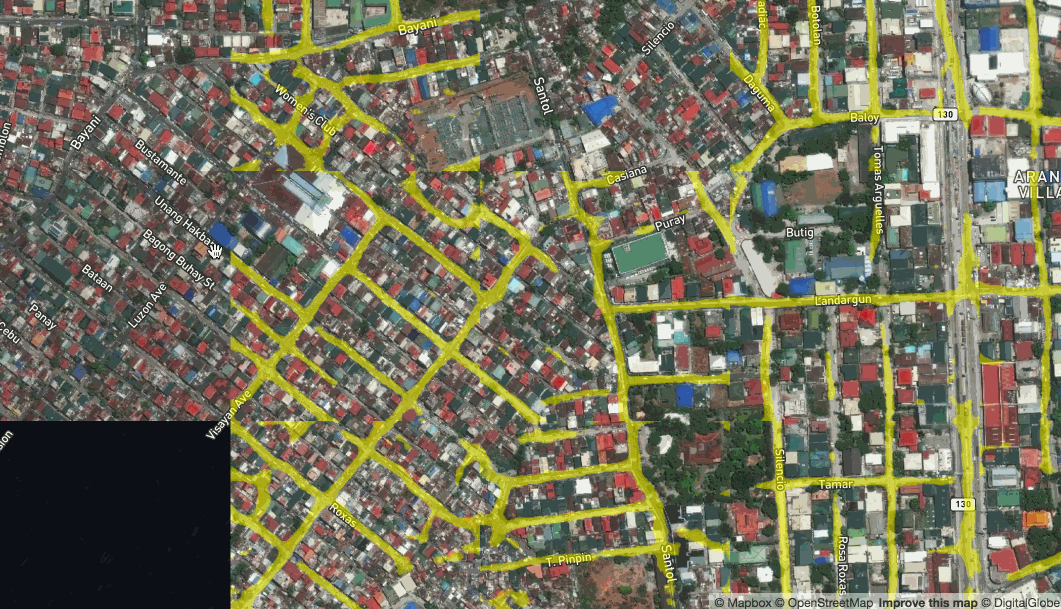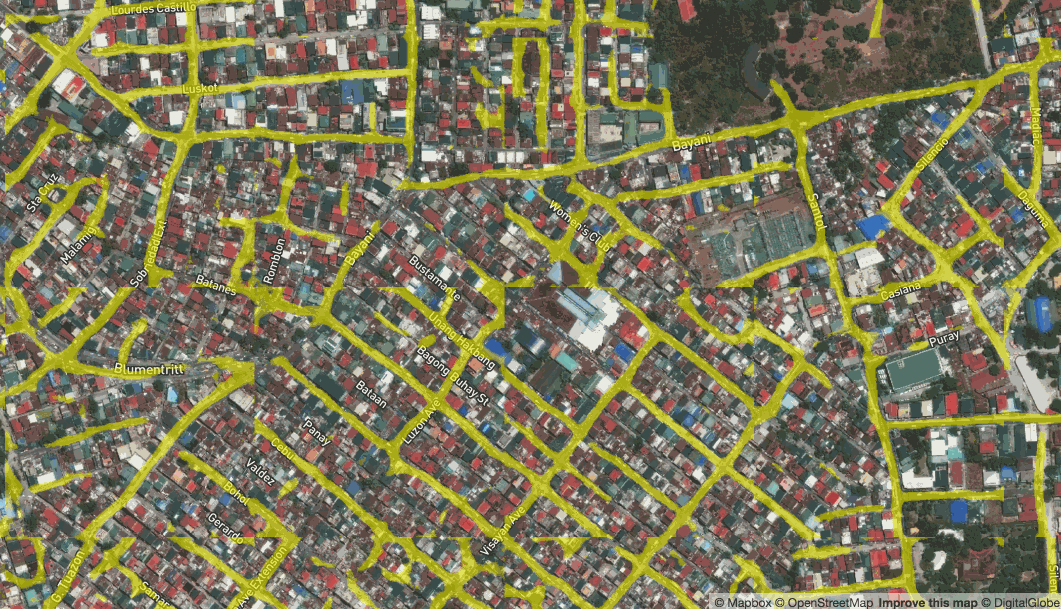 Live prediction of roads in Manilla, Philippines
Live prediction of roads in Manilla, Philippines
While the results aren’t always perfect, they are pretty good. They can be used to give an immediate idea of where to spot features or to run a quick calculation on approximately how many buildings or kilometers of road fall into an administrative region or disaster area.
Open works well for development work
We’ve benefited greatly from using open tools for our work and by sharing our imagery processing pipeline with others. We love collaborating with people with interesting problems to solve or ingenious solutions we haven’t considered. You can check out the code on Github or find me at SatSummit to chat.
What we're doing.
Latest