

We just published our analysis “What Happened in the Afghanistan Elections?”. I worked with Drew Bollinger to examine the degree and impact of potential election fraud in the country by comparing the results to the population and looking for statistical anomalies in the results. We are using Github to track all our data, opening up population data from the government and our analysis scripts.
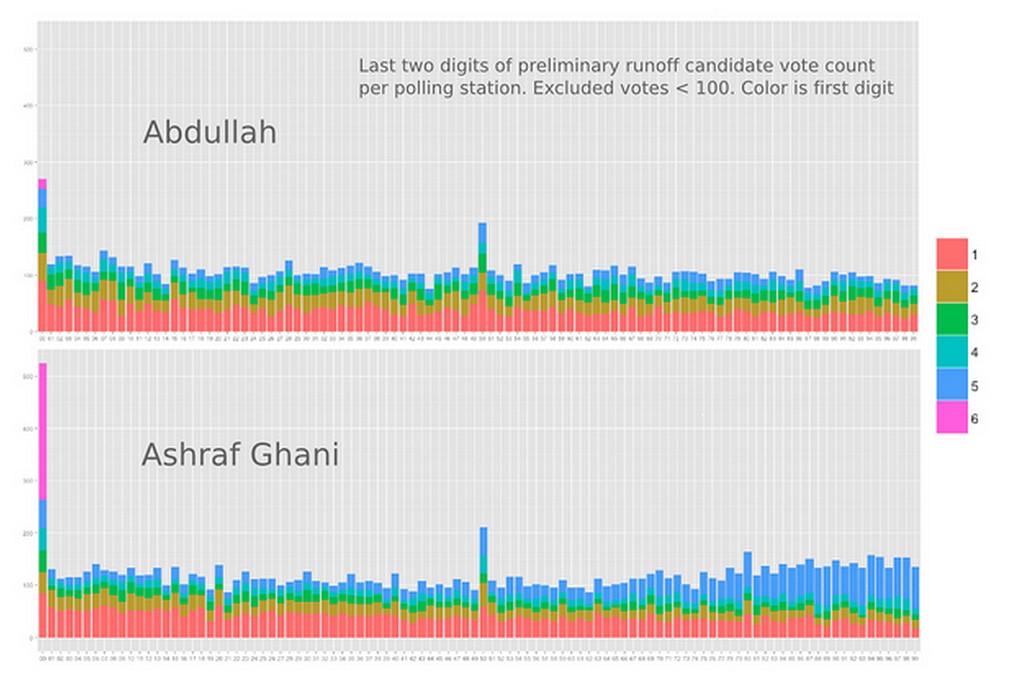
Open access to official data makes analysis possible. Our findings are blunt. Twenty-one districts in Afghanistan reported more votes than the estimated population using the most recent official data from Afghanistan Central Statistics Organization (CSO). Districts with significant increases from the first election in April turnout are much more likely to have runoff turnout numbers greater than the population. More than 500,000 votes came from districts with more votes than people and 1.85 million votes came from districts where more than 60% of the population voted. Again, abnormal distributions of vote counts can provide insight into identifying fraudulent provincial results (read the full report).
Data is complicated, especially in conflict zones. Afghanistan had one partial census in 1979 before war broke out. The government has been working to augment this old data. For instance, between 2003–2005 UNFPA and the CSO ran a new Socio-Economic and Demographic Profile, a household level survey that was a rebasing for a planned future census. We are currently pulling all the data out of this UNFPA PDF report (expect an update later today) and posting it to Github. But even this rebasing was incomplete because of limited access given the conflict — — for example, the results from Helmand, Zabul, Daikundi, and Paktika were never updated in the official CSO numbers. In short, the lack of updated data is causing some of these outliers in our findings.
But this lack of data only points to a larger issue: data is infrastructure. Governments need data to run well and elections need open data to be administered well. And this is why we are using Github, it’s a place to put data that is openly accessible and social so citizens can not only have access to data to ensure transparency and accountability, but so they can improve the data. Github makes data social. Pull requests wanted. Hit us up @developmentseed on twitter if you have questions.
What we're doing.
Latest